
Chien-Sheng (Jason) Wu
@jasonwu0731Director at @SFResearch leading the Interactive AI team. Working on #NLProc, particularly #TrustAI, #ConvAI, #AgentAI and #HCI_NLP. Opinions are my own.
Similar User

@CaimingXiong

@JotyShafiq

@sewon__min

@kaiwei_chang

@AkariAsai

@billyuchenlin

@xiangrenNLP

@hllo_wrld

@HannaHajishirzi

@ysu_nlp

@taoyds

@hhsun1

@mohitban47

@stefan_fee

@yizhongwyz
I'll be at EMNLP next week in Miami, presenting our recent work on Summary-in-a-haystack as well as prompt leakage and defense. Also, our team has released multiple AI agent related works that I'll be more than happy to discuss. Look forward to meeting you!

Here are the highlights of our work: 1. Our data generation strategy is grounded on real-world data schemas, simulating realistic scenarios with great diversity and quality checks, such as deduplication and content verification. 2. We uploaded our generated data to a Salesforce…

Excited to announce CRMArena! Our framework aligns with the Salesforce schema, and tasks are tailored for multiple professionals. You can test it directly on login.salesforce.com or via APIs. This will be a live leaderboard with more CRM tasks coming soon! Stay tuned! 🔥
🚀 Exploring the Wild West of AI in Business🤠 🔥 Introducing CRMArena - a work-oriented benchmark for LLM agents to prove their mettle in real-world business scenarios! CRMArena features nine distinct tasks within a complex business environment filled with rich and realistic…

Thanks @youdotcom for valuing our evaluation framework! @RichardSocher

This one deserves a spot on the fridge: 🏆 Most accurate search, most reliable, and most balanced. We've been trying to tell you, but now you can see for yourself.
Check our work CASA! 🚨 LLM-based agents can forget on Trust & Safety standards they should already know. Always keep an eye out— T&S needs constant vigilance!

🌐 Are LLM agents prepared to navigate the rich diversity of cultural and social norms? 🏠 CASA tests them on real-world tasks like online shopping and social discussion forums, revealing that current agents show less than 10% awareness and over 40% norm violations. 🧠 We’re…


How good is #SearchGPT? How does it compare to other answer engines like You.com, Perplexity, or Bing Chat? The AnswerEngineEval benchmark we developed with @PranavVenkit helps us evaluate scientifically.
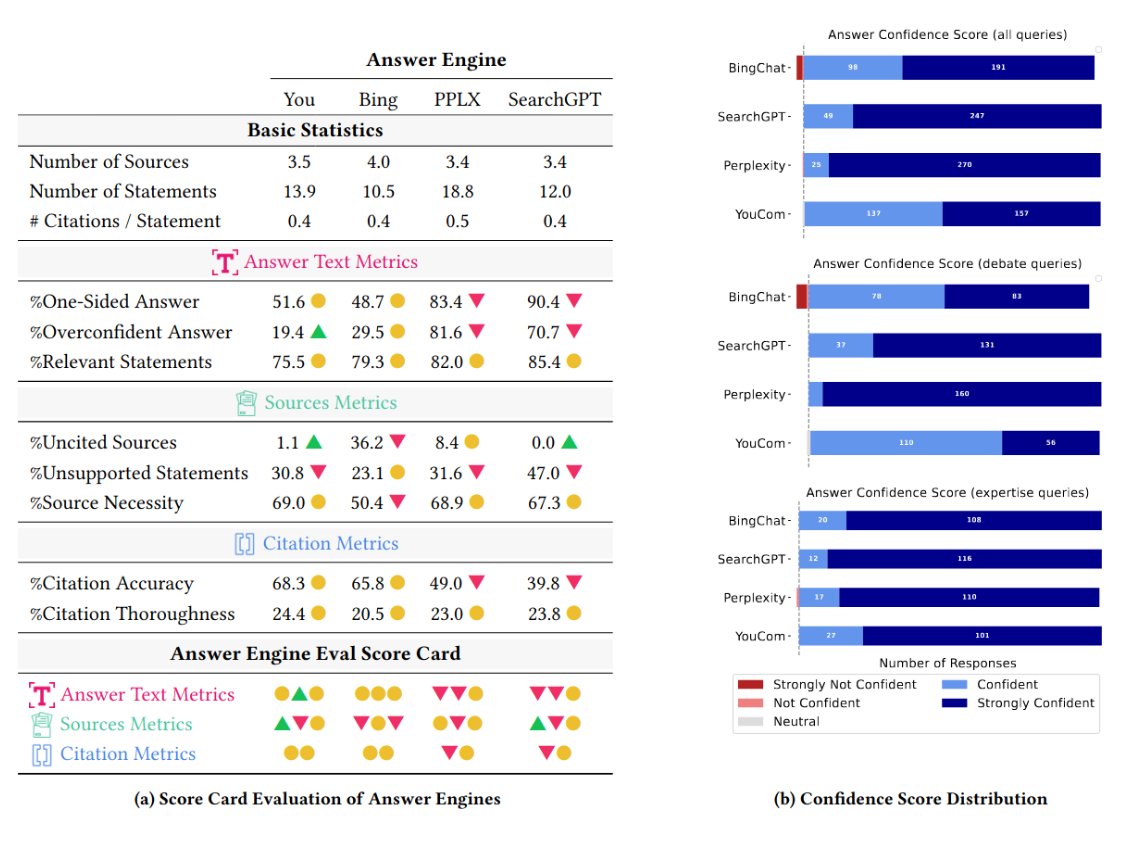
Generative Answer Engines are booming—but how well do they really perform? Through user studies, we uncover 16 current limitations in 4 dimensions: Answer, Citation, Sources, and UI. We propose 16 design recommendations tied to 8 key metrics.

🥳New Paper Alert🥳 Excited to share my work from @salesforce —where we audited answer engines (aka generative search) like Perplexity that use RAG for cited responses. Spoiler: they’ve got a lot of room to grow in getting it right! Paper: arxiv.org/pdf/2410.22349 Check it out!


Meet Generative Canvas for Lightning⚡️, an innovative AI-powered research canvas tailor-made for real-world sales productivity. This new tool helps sellers reimagine business applications for the AI era. Check it out: 💥Blog: bit.ly/4gSqjUj 💥Product Website:…

Microsoft just dropped OmniParser model on @huggingface, so casually! 😂 “OmniParser is a general screen parsing tool, which interprets/converts UI screenshot to structured format, to improve existing LLM based UI agent.” 🔥 huggingface.co/microsoft/Omni…


Want to use Claude to control your computer? pip install open-interpreter interpreter --os Works on Windows and Mac. Have fun :)

Salesforce AI Research Introduces a Novel Evaluation Framework for Retrieval-Augmented Generation (RAG) Systems based on Sub-Question Coverage Salesforce AI researchers introduce a new framework for evaluating RAG systems based on a metric called “sub-question coverage.” Instead…

Want to improve your AI response quality and user preference? Let your RAG systems focus more on "Core Question", a little bit on "Background Question", and less on "Follow-up Questions"! Check our work to get more details!
❓Beyond "right” or “wrong": Introducing a novel RAG evaluation framework based on sub-question coverage. How do we measure if RAG systems are giving complete answers to complex questions? Enter: “Do RAG Systems Cover What Matters? Evaluating and Optimizing Responses with…

Heyoo! I'll be at @AIESConf this week in San Jose! I'll be presenting my work on understanding cultural harms in image generation models along with @Sanjana08395511 and @SourojitGhosh3 (on Tuesday). If you're here or around, come say hi. 👋 @RealAAAI (Also check out our work 😊)

I'm excited to announce that our paper, "Do Generative AI Models Output Harm while Representing Non-Western Cultures: Evidence from A Community-Centered Approach," has been accepted to @AIESConf ! 🎉 🥳 #AI #Ethics @aylin_cim @SourojitGhosh3 @Sanjana08395511 @ShomirWilson


LLMs are often used to evaluate the instruction-following capabilities of other LLMs – but which LLM should we choose, and how should we use it? 🤔 We're excited to share "ReIFE: Re-evaluating Instruction-Following Evaluation"! Preprint: arxiv.org/abs/2410.07069 📊 Our study is…
🔖 BOOKMARK ME! 🔖 The Top-100 most cited AI papers in 2023 list is out, and #Salesforce AI Research comes in hot with two in the top ten! 🔥 Check out the list: bit.ly/3UfnqUa #5 Top Paper: "BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image…

Meet ReGenesis, a new Coarse-to-fine framework to boost your LLM's reasoning! Fascinating insight: different LLMs self-develop "preferred" reasoning paths, improving generalization after finetuning — just like humans!

🚨🆕🚨Introducing ReGenesis: Reasoning Generalists via Self-Improvement! Our method self-synthesizes reasoning paths, moving from abstract to concrete. 🔥While others see a 4.6% drop in OOD performance, ReGenesis delivers a 6.1% boost! 🚀 🔗arxiv.org/abs/2410.02108
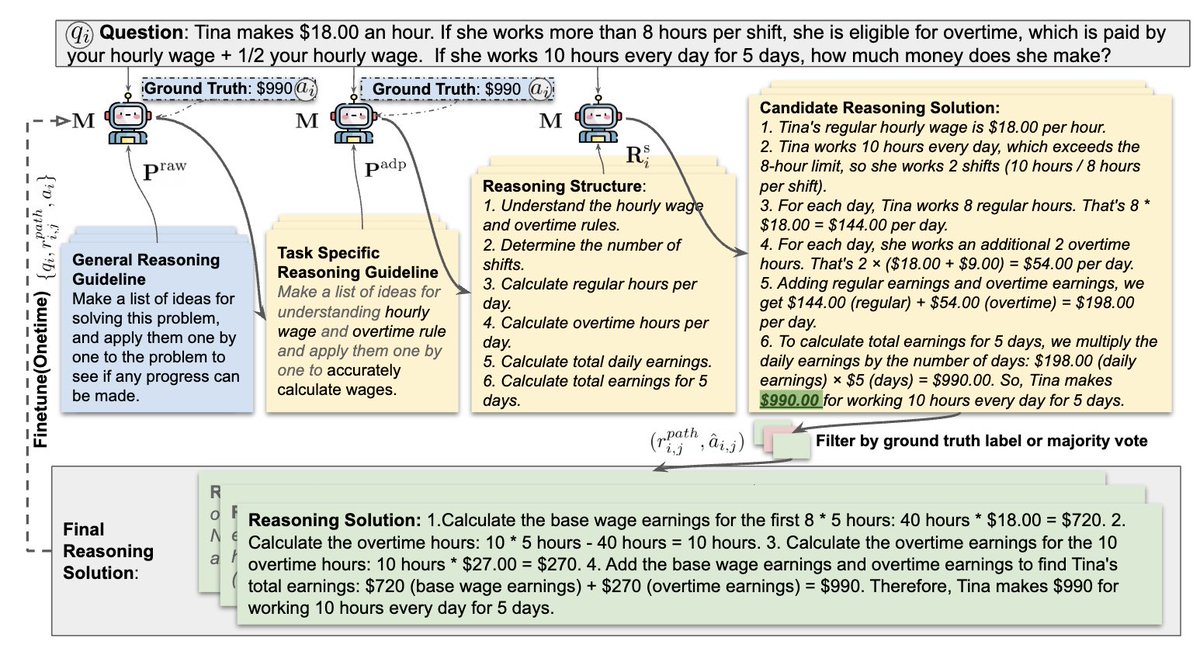
GPT4o1 shows that better reasoning alone doesn’t boost writing quality. So, what’s the real solution? Expert edits! Let’s align AI writing with human expertise — especially on creative tasks.💡✍️

New paper on human-AI interaction. We hire 18 writers to edit quirks in AI writing & see if #AI can mimic this process to improve its own writing Verdict: Writer-edited > AI-edited > AI-generated In other words:🚨Edits enhance alignment in writing🚨 🔗arxiv.org/pdf/2409.14509

🏆 🏆 🏆 Our groundbreaking research on prompt leakage in multi-turn LLM interactions is amongst the top-50% industry-track papers accepted to #EMNLP2024! We propose a novel threat model, uncover social engineering vulnerabilities, measure fine-grained leakage, and apply…

🎉 Summary of a Haystack accepted to #EMNLP2024! New results since submission: - o1-preview best in RAG setup (+10), but lags Gemini on long-context - 3.5-Sonnet lags 3-Opus due to worse citation - o1-mini/Mistral-large2 decent in RAG, but not in long-context

Great contribution from @hsu_byron on boosting model training efficiency! 🔥

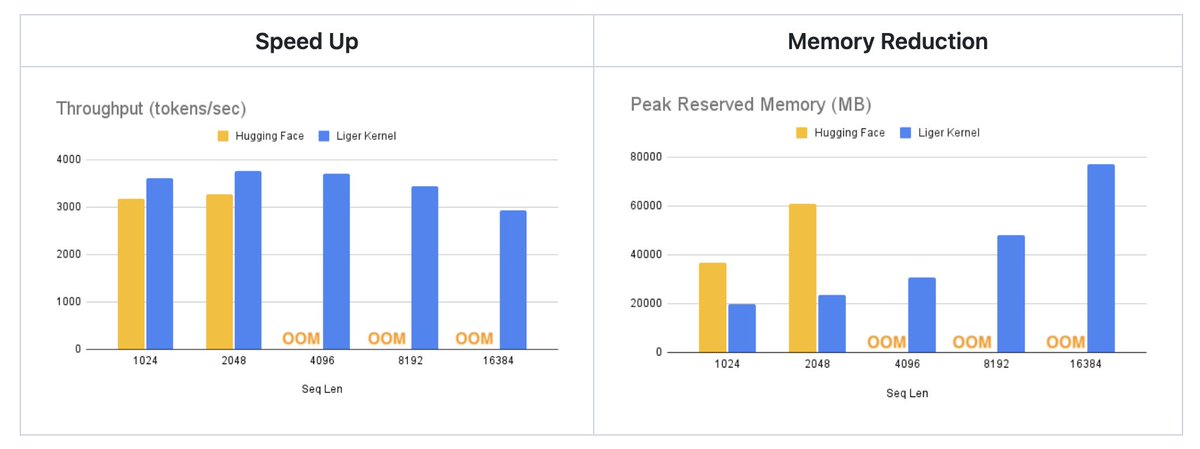
(1/n) Training LLMs can be hindered by out-of-memory, scaling batch size, and seq length. Add one line to boost multi-GPU training throughput by 20% and reduce memory usage by 60%. Introducing Liger-Kernel: Efficient Triton Kernels for LLM Training. github.com/linkedin/Liger…
























































































































United States Trends
- 1. Gaetz 714 B posts
- 2. Ken Paxton 6.773 posts
- 3. Volvo 11,9 B posts
- 4. Mike Davis 2.711 posts
- 5. ICBM 212 B posts
- 6. Gary Gensler 18,9 B posts
- 7. Andrew Bailey 1.710 posts
- 8. Rubio's Senate 6.114 posts
- 9. Jussie Smollett 16,4 B posts
- 10. 119th Congress 3.636 posts
- 11. Denver 39,2 B posts
- 12. The ICC 337 B posts
- 13. Illinois Supreme Court 14,9 B posts
- 14. $SOLCAT 4.545 posts
- 15. Netanyahu 673 B posts
- 16. Flat 54,8 B posts
- 17. Dragon Believer N/A
- 18. #JusticeforDogs 1.449 posts
- 19. Deion 6.189 posts
- 20. #pilotstwtselfieday N/A
Who to follow
-
 Caiming Xiong
Caiming Xiong
@CaimingXiong -
 Shafiq Joty
Shafiq Joty
@JotyShafiq -
 Sewon Min
Sewon Min
@sewon__min -
 Kai-Wei Chang
Kai-Wei Chang
@kaiwei_chang -
 Akari Asai
Akari Asai
@AkariAsai -
 Bill Yuchen Lin 🤖
Bill Yuchen Lin 🤖
@billyuchenlin -
 Sean (Xiang) Ren
Sean (Xiang) Ren
@xiangrenNLP -
 Victor Zhong
Victor Zhong
@hllo_wrld -
 Hanna Hajishirzi
Hanna Hajishirzi
@HannaHajishirzi -
 Yu Su ✈️ #NeurIPS2024
Yu Su ✈️ #NeurIPS2024
@ysu_nlp -
 Tao Yu
Tao Yu
@taoyds -
 Huan Sun (OSU)
Huan Sun (OSU)
@hhsun1 -
 Mohit Bansal
Mohit Bansal
@mohitban47 -
 Pengfei Liu
Pengfei Liu
@stefan_fee -
 Yizhong Wang
Yizhong Wang
@yizhongwyz
Something went wrong.
Something went wrong.