
Caiming Xiong
@CaimingXiongVP of AI at @Salesforce Research: AI for CRM, AI for good.
Similar User

@YejinChoinka

@jacobandreas

@cocoweixu

@Zhou_Yu_AI

@hllo_wrld

@sleepinyourhat

@uwnlp

@riedelcastro

@xiangrenNLP

@kaiwei_chang

@sewon__min

@lmthang

@tejasdkulkarni

@danqi_chen

@hhexiy

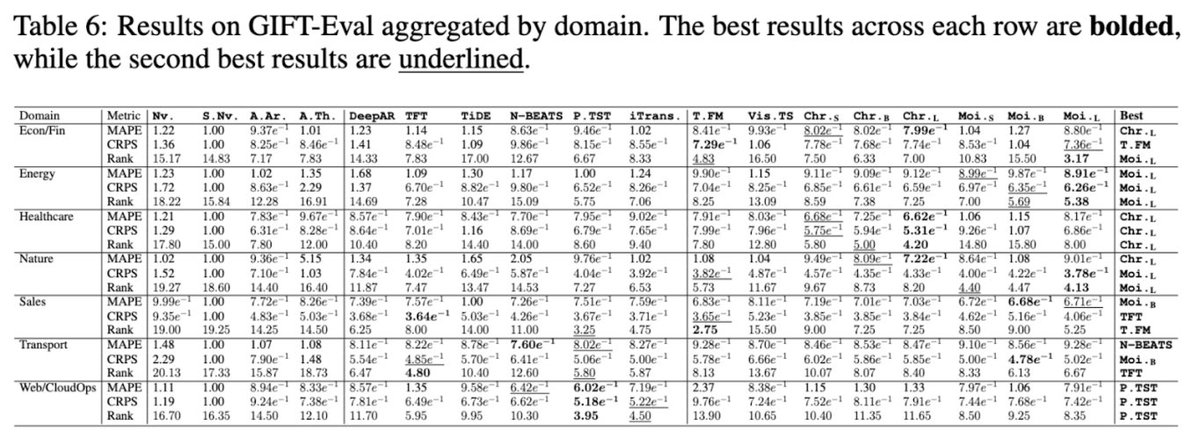
Introducing GIFT-Eval: A groundbreaking AI benchmark for time series forecasting models! 🌐 GIFT-Eval offers 28 diverse AI datasets, over 144,000 time series, and 177M data points, enabling fair and robust evaluation of models across domains, frequencies, and prediction horizons.…



Build your agents to solve CRM tasks, how to test them in the real-like environment? Excited to announce CRMArena, a benchmark for enterprise LLM agents to navigate real-world business challenges! CRMArena offers nine top-classes of tasks on three personas in complex business…

🚀 Exploring the Wild West of AI in Business🤠 🔥 Introducing CRMArena - a work-oriented benchmark for LLM agents to prove their mettle in real-world business scenarios! CRMArena features nine distinct tasks within a complex business environment filled with rich and realistic…


🍅Excited to see @AnthropicAI using 🚀our OSWorld🚀(NeurIPS'24) to benchmark computer use! 🍋OSWorld will soon support parallel cloud running, much faster! 🍓More multimodal agent open-source big projects coming soon from @XLangNLP in Nov- stay tuned! 👇os-world.github.io


Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking, and typing text.

xGen-MM-Vid (BLIP-3-Video)

📢📢📢Introducing xGen-MM-Vid (BLIP-3-Video)! This highly efficient multimodal language model is laser-focused on video understanding. Compared to other models, xGen-MM-Vid represents a video with a fraction of the visual tokens (e.g., 32 vs. 4608 tokens). Paper:…
Data & Benchmarks truly are the fuel powering our AI innovations! Very excited to share that five of our papers have been accepted at NeurIPS 2024 D&B track! I'm so proud to have contributed to these groundbreaking projects: 1. Consent in Crisis: The Rapid Decline of the AI…
🧨🧨We release the Fineweb-deduplicated dataset.
👇UPDATED DATASET👇Fineweb training dataset just got leaner! We've tackled the ~70% duplication issue in this valuable 93.4TB dataset. Same great data, now more efficient and cost-effective. bit.ly/3XI3wlB #AIResearch #DataEfficiency

Large Language Model Agents is the next frontier. Really excited to announce our Berkeley course on LLM Agents, also available for anyone to join as a MOOC, starting Sep 9 (Mon) 3pm PT! 📢 Sign up & join us: llmagents-learning.org



























































































































United States Trends
- 1. Brian Kelly 5.918 posts
- 2. Gators 9.346 posts
- 3. Louisville 4.938 posts
- 4. Feds 33,1 B posts
- 5. Nuss 3.029 posts
- 6. #UFC309 35,6 B posts
- 7. Stanford 8.173 posts
- 8. Billy Napier 1.528 posts
- 9. Nebraska 8.982 posts
- 10. Mizzou 3.918 posts
- 11. Lagway 3.995 posts
- 12. Brohm N/A
- 13. #Huskers 1.346 posts
- 14. Tyler Warren 1.948 posts
- 15. Raiola N/A
- 16. Ron English N/A
- 17. #MostRequestedLive 4.582 posts
- 18. Baylor 3.282 posts
- 19. Heisman 13,2 B posts
- 20. Moura 6.773 posts
Who to follow
-
 Yejin Choi
Yejin Choi
@YejinChoinka -
 Jacob Andreas
Jacob Andreas
@jacobandreas -
 Wei Xu
Wei Xu
@cocoweixu -
 zhou Yu
zhou Yu
@Zhou_Yu_AI -
 Victor Zhong
Victor Zhong
@hllo_wrld -
 Sam Bowman
Sam Bowman
@sleepinyourhat -
 UW NLP
UW NLP
@uwnlp -
 Sebastian Riedel (@[email protected])
Sebastian Riedel (@[email protected])
@riedelcastro -
 Sean (Xiang) Ren
Sean (Xiang) Ren
@xiangrenNLP -
 Kai-Wei Chang
Kai-Wei Chang
@kaiwei_chang -
 Sewon Min
Sewon Min
@sewon__min -
 Thang Luong
Thang Luong
@lmthang -
 Tejas Kulkarni
Tejas Kulkarni
@tejasdkulkarni -
 Danqi Chen
Danqi Chen
@danqi_chen -
 He He
He He
@hhexiy
Something went wrong.
Something went wrong.