
Richard Diehl Martinez
@richarddm1CS PhD at University of Cambridge. Previously Applied Scientist @Amazon, MS/BS @Stanford.
Similar User

@christinedekock

@ZhijiangG

@dominsta_nlp

@anitaveroe

@RamintaIeva

@HelenaXie_

@CurriedAmanda

@pietro_lesci

@Ramiyaly

@MoyYuan

@guyaglionby

@Eric_chamoun

@Tugelezi

@brianleixia
The golden pacifier has made it back to Cambridge! Big thank you to the #babylm and #connl teams for the award and a great workshop! Checkout the paper: arxiv.org/pdf/2410.22906

Small language models are worse than large models because they have less parameters ... duh! Well not so fast. In a recent #EMNLP2024 paper, we find that small models have WAY less stable learning trajectories which leads them to underperform.📉 arxiv.org/abs/2410.11451
🙋♂️My Lab mates are @emnlpmeeting this week: drop by their posters! If you want to know more about our recent work [1] on small language models, catch @richarddm1 who will answer all your questions! 🧑💻#EMNLP2024 #NLProc [1]: arxiv.org/abs/2410.11451


What's new in NLP this week? Kingma (better known as the Adam Optimizer guy) published a paper showing that Diffusion Models as well as Flow Models are basically combinations of VAE models (Variational Auto-Encoders) behind the scenes. Turns out Kingma also wrote the original…
It’s well known that training and serving AI models requires a lot of energy — what’s less obvious is that they require lots of water for cooling. Karen Hao (whose writing style I like) has a piece out about a server complex in Arizona that hosts OpenAI models. Also, Anthropic’s…
If Gemini wasn’t interesting enough for you, Google this week published a paper where they show how to train a language model as a universal regressor. Regression is the bread-and-butter of machine learning, and they propose that you can use a language model to perform arbitrary…
Last week, Google released it’s new consumer “Gemini” product (what used to be BARD). This week Google released some analysis about its performance - the main headline: it can do context lengths of around 10 million tokens. nlpinsightfilter.substack.com/p/nlp-insight-…
A paper this week analysis the scaling properties of your predictions as you increase the number of LLM agents — the title of the paper makes the conclusion pretty obvious “more agents is all you need”. nlpinsightfilter.substack.com/p/nlp-insight-…
As you might now, state space models like Mamba are the new cool kid on the block. Although they seem to be all the rage, a recent paper shows that these types of models are worse than transformers at tasks that require copying text. open.substack.com/pub/nlpinsight…
Microsoft has a new way of doing PEFT that they call SliceGPT. The idea is to compute the PCA of certain weight matrices, and slice off the ‘un-important’ dimensions (roughly 25% of params can be cut off). I talk about it in my substack this week: nlpinsightfilter.substack.com/p/nlp-insight-…
Ever wonder whether people posting their papers on X really helps them become more popular? Answer: yeah, that’s sort of obvious. But how much more popular? Turns out 2-3 times more popular — kind of crazy. Checkout the details on my bi-weekly substack: nlpinsightfilter.substack.com/p/nlp-insight-…
Check out my substack for this week's hot NLP research takes NLP Insight Filter [Jan 23 2024] open.substack.com/pub/nlpinsight…
To my new X/Twitter friends - I've been publishing a bi-weekly substack newsletter on NLP research papers. Check out my most recent post (and consider subscribing): NLP Insight Filter [Jan 17 2024] open.substack.com/pub/nlpinsight…

🧐 Curious about diverse, human-centered perspectives on cross-lingual models? Join the HumanCLAIM workshop ✨ 📆 11 Jan ‘24 📍Amsterdam We'll dive into boosting diversity in language technology! 🔗clap-lab.github.io/workshop

Best Negative results Curriculum learning methods are hard to get right But their advantages stack Tooons of exps. A thesis could not be summed into a tweet: arxiv.org/abs/2311.08886 @richarddm1 Zebulon Goriely @hope_mcgovern @c_davis90 Paula Buttery @lisabeinborn

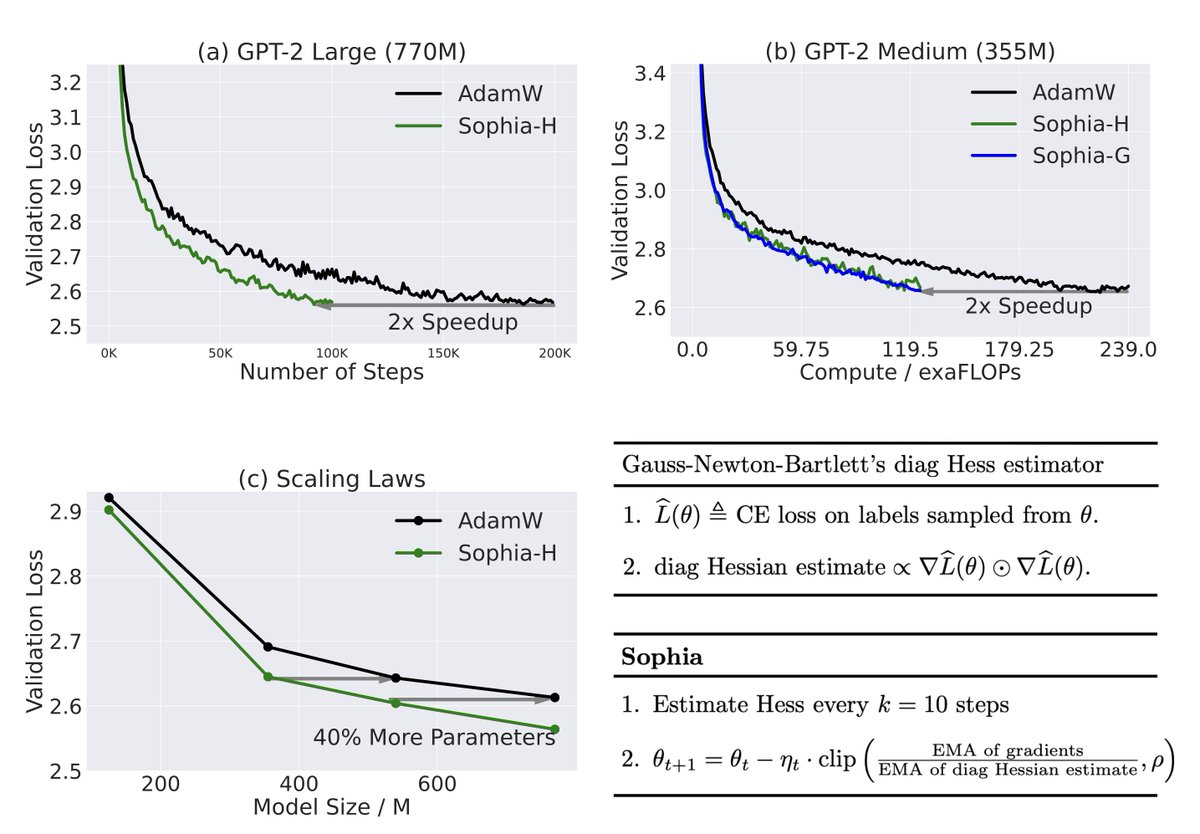
Releasing the code of Sophia 😀, a new optimizer (⬇️). code: github.com/Liuhong99/Soph… twitter.com/tengyuma/statu…
Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA). Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold). arxiv.org/abs/2305.14342 🧵⬇️










































































United States Trends
- 1. Hunter 749 B posts
- 2. Hunter 749 B posts
- 3. Josh Allen 33,5 B posts
- 4. 49ers 43,3 B posts
- 5. 49ers 43,3 B posts
- 6. Niners 9.019 posts
- 7. #BaddiesMidwest 10,5 B posts
- 8. Hardy 13,1 B posts
- 9. #SFvsBUF 17 B posts
- 10. Justin Tucker 31 B posts
- 11. #Married2Med 3.521 posts
- 12. Burisma 25,6 B posts
- 13. Ravens 77,9 B posts
- 14. #RHOP 5.150 posts
- 15. Achilles 5.444 posts
- 16. #FTTB 4.184 posts
- 17. Rockets 18,5 B posts
- 18. Eagles 116 B posts
- 19. Collinsworth 1.729 posts
- 20. Purdy 7.230 posts
Who to follow
-
 Christine de Kock
Christine de Kock
@christinedekock -
 Zhijiang Guo
Zhijiang Guo
@ZhijiangG -
 Dominik Stammbach
Dominik Stammbach
@dominsta_nlp -
 Anita Verő
Anita Verő
@anitaveroe -
 Ieva Raminta @ievaraminta.bsky.social
Ieva Raminta @ievaraminta.bsky.social
@RamintaIeva -
 Helena Xie
Helena Xie
@HelenaXie_ -
 Amanda Cercas Curry
Amanda Cercas Curry
@CurriedAmanda -
 Pietro Lesci
Pietro Lesci
@pietro_lesci -
 Rami Aly
Rami Aly
@Ramiyaly -
 Moy Yuan
Moy Yuan
@MoyYuan -
 Guy Aglionby
Guy Aglionby
@guyaglionby -
 Eric
Eric
@Eric_chamoun -
 JuliusPrince
JuliusPrince
@Tugelezi -
 Lei Xia
Lei Xia
@brianleixia
Something went wrong.
Something went wrong.