
Similar User

@abdielcasanas

@GlennSt39143555

@SilverBay2023

@Amber_quge

@victordevguy

@Hunter2Sun

@EmilyCrewe1

@Christal0616

@AlHassan49186
update: OpenAI-o1 likely system prompt for Multi-Step Reasoning ^^ github.com/Mr-Jack-Tung/J…

"Open-source developer platform to power your entire infra and turn scripts into webhooks, workflows and UIs. Fastest workflow engine (13x vs Airflow). Open-source alternative to Retool and Temporal."
This is song is not created by a real human. It’s made with Suno V4. Now we passed the threshold where we were able to distinguish man made music from AI one. Also the video. It’s over for good old Warner Music and others.
China seems to be in the robot lead. We need to accelerate more. No question about it.
You can finetune Qwen-2.5-Coder-14B for free on Colab now! Unsloth makes finetuning 2x faster & uses 60% less VRAM with no accuracy loss. We extended context lengths from 32K to 128K with YaRN & uploaded GGUFs: huggingface.co/collections/un… Finetuning Colab: colab.research.google.com/drive/18sN803s…
M4 Mac AI Coding Cluster Uses @exolabs to run LLMs (here Qwen 2.5 Coder 32B at 18 tok/sec) distributed across 4 M4 Mac Minis (Thunderbolt 5 80Gbps) and a MacBook Pro M4 Max. Local alternative to @cursor_ai (benchmark comparison soon).
The Rhythm In Anything (TRIA) An AI system to map arbitrary sound to high-fidelity drum recordings! Mind-blowing 🤯 we've probably watched this video a thousand times now 🥁 [SOUND: ON🎵]
Humans can learn to reason in an "unfamiliar" world, like new games. How far are LLMs from this? Check out our recent work @NeurIPS2024 D&B Track: "LogiCity: Advancing Neuro-Symbolic AI with Abstract Urban Simulation". Page: jaraxxus-me.github.io/LogiCity/
.@Microsoft just dropped TinyTroupe! Described as "an experimental Python library that allows the simulation of people with specific personalities, interests, and goals." These agents can listen, reply back, and go about their lives in simulated TinyWorld environments.

💫 Introducing Mixture-of-Transformers (MoT) , our latest work advancing modality-aware sparse architectures for multimodal foundation models, led by @liang_weixin, in collaboration w/ amazing colleagues at @AIatMeta arxiv.org/abs/2411.04996 (1/n)


How can we reduce pretraining costs for multi-modal models without sacrificing quality? We study this Q in our new work: arxiv.org/abs/2411.04996 At @AIatMeta, We introduce Mixture-of-Transformers (MoT), a sparse architecture with modality-aware sparsity for every non-embedding…



At last, a curriculum learning that works, one for pretraining and another for instruction tuning @l__ranaldi @Giuli12P2 @andrenfreitas @znz8 aclanthology.org/2024.lrec-main… aclanthology.org/2023.ranlp-1.1…

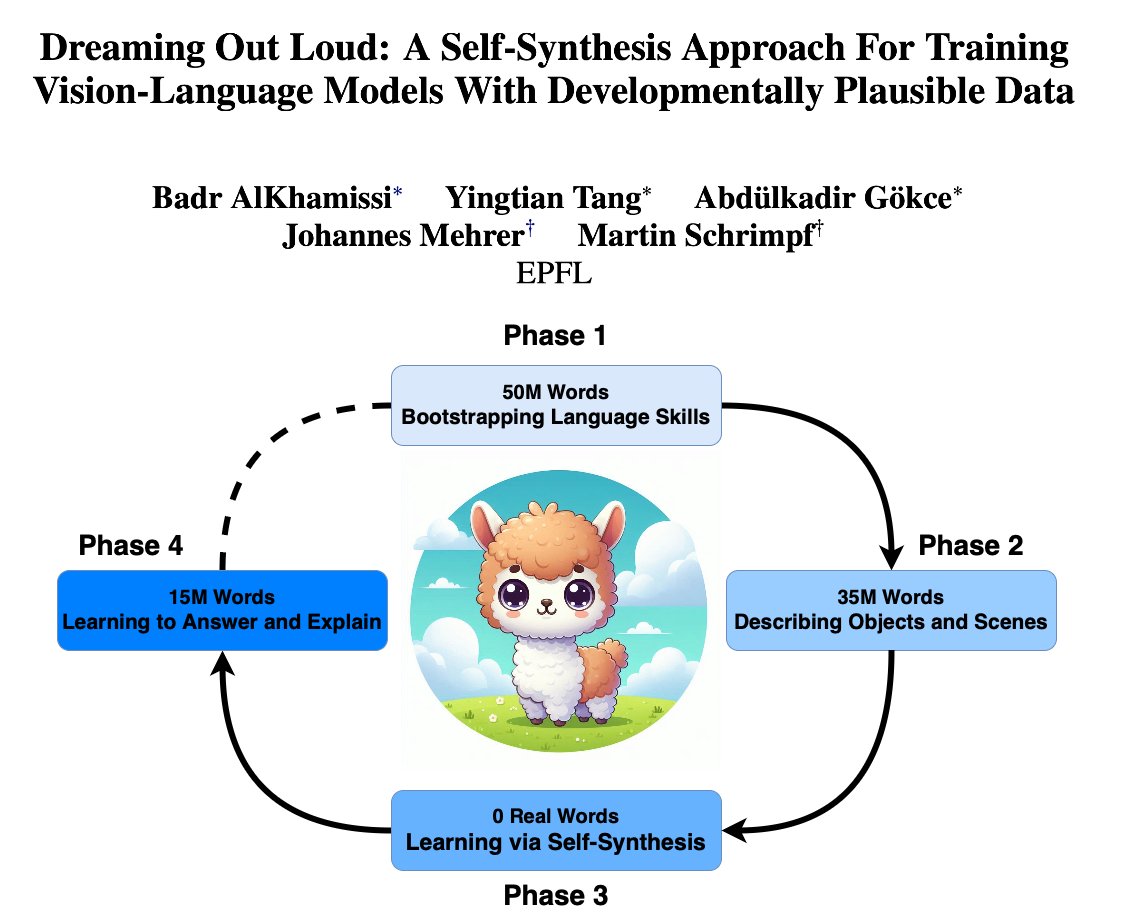
🚨 New Paper!! How can we train LLMs using 100M words? In our @babyLMchallenge paper, we introduce a new self-synthesis training recipe to tackle this question! 🍼💻 This was a fun project co-led by me, @yingtian80536, @akgokce0, w/ @HannesMehrer & @martin_schrimpf 🧵⬇️
"Full stack, modern web application template. Using FastAPI, React, SQLModel, PostgreSQL, Docker, GitHub Actions, automatic HTTPS and more."

Voice-Pro gradio web-ui for transcription, translation and text-to-speech
M4 Mac Mini AI Cluster Uses @exolabs with Thunderbolt 5 interconnect (80Gbps) to run LLMs distributed across 4 M4 Pro Mac Minis. The cluster is small (iPhone for reference). It’s running Nemotron 70B at 8 tok/sec and scales to Llama 405B (benchmarks soon).
✒️Kiroku is a multi-agent system that helps you organize and write documents Really complex agent (see the diagram below!) that HEAVILY involves a "human in the loop" flow Great resource for anyone looking to create a writing agent github.com/cnunescoelho/k…

Model merging is tricky when model weights aren’t aligned Introducing KnOTS 🪢: a gradient-free framework to merge LoRA models. KnOTS is plug-and-play, boosting SoTA merging methods by up to 4.3%🚀 📜: arxiv.org/abs/2410.19735 💻: github.com/gstoica27/KnOTS
👉🏻Thrilled to introduce BitNet a4.8, enabling 4-bit activations for 1.58-bit LLMs!🚀🚀 Paper: arxiv.org/abs/2411.04965 HF page: huggingface.co/papers/2411.04… 🔥🔥2B BitNet a4.8 trained with 2T tokens achieves 50.30% acc on MMLU, almost no degradation to BitNet b1.58.

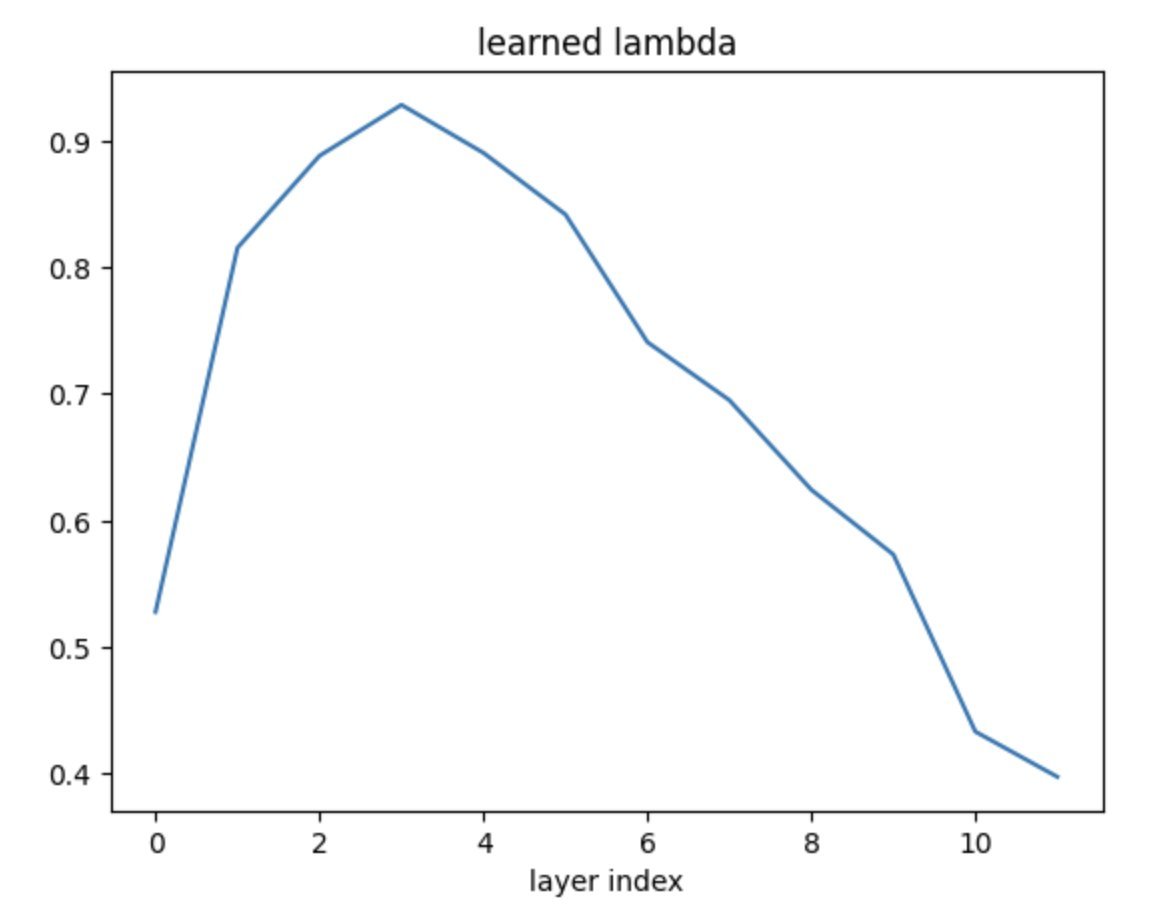
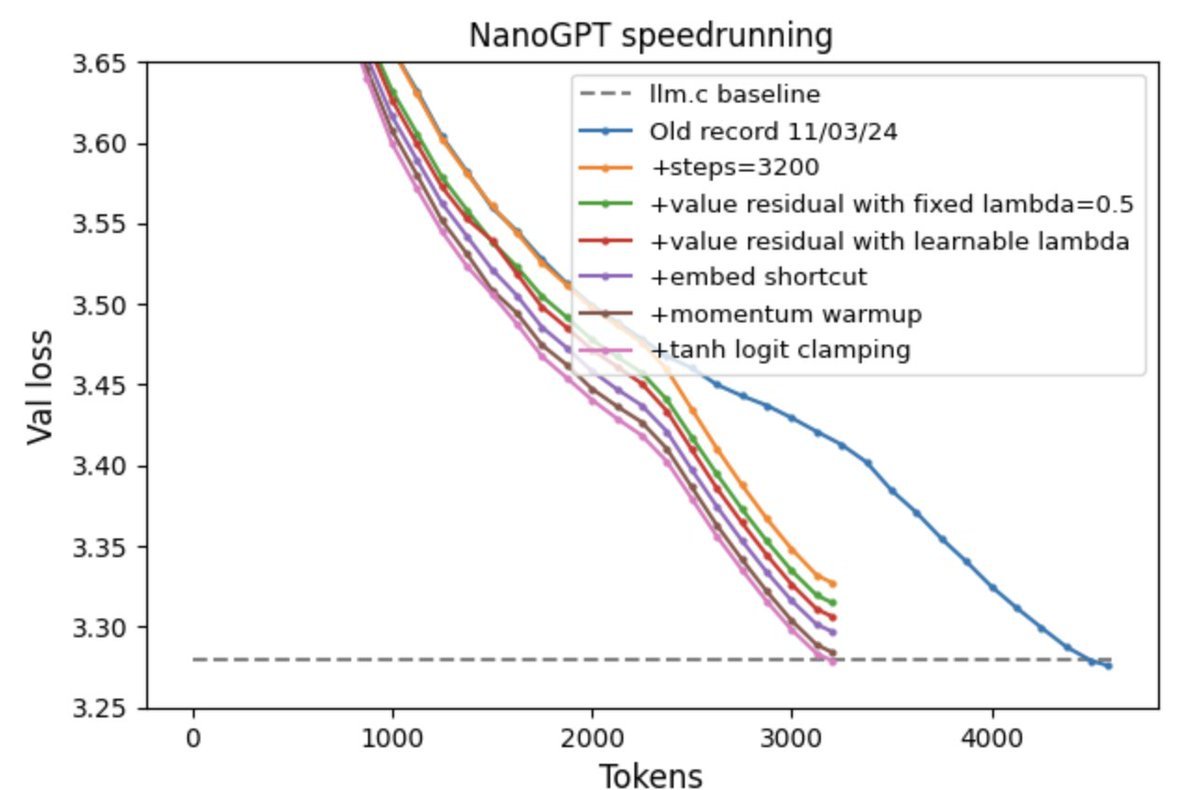
43% of the speedup in the new NanoGPT record is due to a variant of value residual learning that I developed. Value residual learning (recently proposed by arxiv.org/abs/2410.17897) allows all blocks in the transformer to access the values computed by the first block. The paper…
































































































United States Trends
- 1. Jake Paul 1,02 Mn posts
- 2. #Arcane 196 B posts
- 3. Jayce 37,9 B posts
- 4. Serrano 245 B posts
- 5. Vander 12 B posts
- 6. #SaturdayVibes 2.201 posts
- 7. maddie 16,6 B posts
- 8. #HappySpecialStage 60 B posts
- 9. Canelo 17,4 B posts
- 10. Jinx 94,8 B posts
- 11. The Astronaut 25,7 B posts
- 12. Isha 28 B posts
- 13. #NetflixFight 75,8 B posts
- 14. Good Saturday 20,4 B posts
- 15. Father Time 10,8 B posts
- 16. Super Tuna 17,9 B posts
- 17. Logan 80,2 B posts
- 18. Boxing 312 B posts
- 19. He's 58 29,4 B posts
- 20. Ekko 15,2 B posts









Something went wrong.
Something went wrong.