
Nate Gruver
@gruver_nateMachine learning PhD student at NYU, BS & MS @StanfordAILab, Industry @AIatMeta @Waymo
Similar User

@Pavel_Izmailov

@ZimingLiu11

@nc_frey

@JacobSteinhardt

@kasperglarsen

@cydhsieh

@TomSercu

@ShikaiQiu

@janundnik

@ShikharMurty

@jo_brandstetter

@samuel_stanton_

@MLMazda

@GabriCorso

@yidingjiang
I’m excited to share our latest work on generative models for materials called FlowLLM. FlowLLM combines Large Language Models and Riemannian Flow Matching in a simple, yet surprisingly effective way for generating materials. arxiv.org/abs/2410.23405 @bkmi13 @RickyTQChen @bwood_m
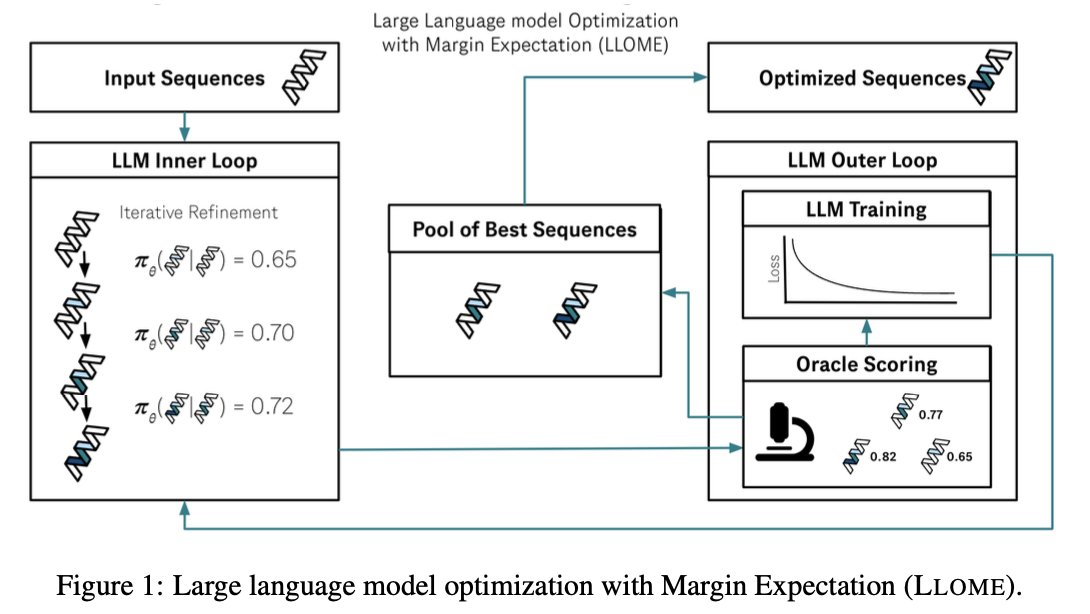
LLMs are highly constrained biological sequence optimizers. In new work led by @_angie_chen & @samuel_stanton_ , we show how to drive an active learning loop for protein design with an LLM. 1/
My ICLR talk “How Do We Build a General Intelligence?” is now online! youtube.com/watch?v=HEp4TO…
📢I’ll be admitting multiple PhD students this winter to Columbia University 🏙️ in the most exciting city in the world! If you are interested in dissecting modern deep learning systems to probe how they work, advancing AI safety, or automating data science, apply to my group.

Introducing Meta’s Open Materials 2024 (OMat24) Dataset and Models! All under permissive open licenses for commercial and non-commercial use! Paper: arxiv.org/abs/2410.12771 Dataset: huggingface.co/datasets/fairc… Models: huggingface.co/fairchem/OMAT24 🧵1/x

Interested in working with a highly collaborative, interdisciplinary team to push the state of the art of generative AI for materials design? Join us as an intern by applying through this link! We are the team behind the MatterGen and MatterSim models from Microsoft Research AI…
🚨 Attention aspiring PhD students: Meta / FAIR is looking for candidates for a joint academic/industry PhD! 🚨 Among others, the CodeGen team is looking for candidates to work on world models for code, discrete search & continuous optimization methods for long-term planning,…

AI molecule design systems are hard to test end-to-end bc experiments are slow and $$$. Approximate feedback from models and simulations is inaccurate and still too slow! In new work we propose closed-form test functions for bio sequence optimization arxiv.org/abs/2407.00236 1
How can we transfer knowledge from large foundation models to a much smaller downstream model? In new ICML work, we show a simple yet conceptually significant modification to knowledge distillation works well with negligible overhead! arxiv.org/abs/2406.07337 1/9

Data in genetics, microbiology, and health have many variables interacting in complex ways. How do we go beyond association? In our new ICML paper, we build a method to quickly and accurately infer causal graphs from large, complex data! arxiv.org/abs/2406.09177 w/@andrewgwils 1/7

Whether LLMs can reliably be used for decision making and benefit society depends on whether they can reliably represent uncertainty over the correctness of their outputs. There's anything but consensus. In new work we find LLMs must be taught to know what they don't know. 1/6
Predictions without reliable confidence are not actionable and potentially dangerous. In new work, we deeply investigate uncertainty calibration of large language models. We find LLMs must be taught to know what they don’t know: arxiv.org/abs/2406.08391 w/ @psiyumm et al. 1/8

If we want to use LLMs for decision making, we need to know how confident they are about their predictions. LLMs don’t output meaningful probabilities off-the-shelf, so here’s how to do it 🧵 Paper: arxiv.org/abs/2406.08391 Thanks @psiyumm and @gruver_nate for leading the charge!

Large Language Models Must Be Taught to Know What They Don't Know abs: arxiv.org/abs/2406.08391 Prompting is not enough for LLMs to produce accurate estimates of its uncertainty of its responses, but can be finetuned with as little as 1000 examples and outperform baselines for…












































































































United States Trends
- 1. #PaulTyson 200 B posts
- 2. #NetflixFight 12,1 B posts
- 3. Ramos 59,2 B posts
- 4. Rosie Perez 5.309 posts
- 5. #SmackDown 60,2 B posts
- 6. Jerry Jones 4.657 posts
- 7. My Netflix 22,8 B posts
- 8. #buffering 1.083 posts
- 9. Cedric 10,3 B posts
- 10. Goyat 21,4 B posts
- 11. #netfix 1.977 posts
- 12. Serrano 23,4 B posts
- 13. Nunes 30,7 B posts
- 14. Michael Irvin N/A
- 15. Holyfield 7.191 posts
- 16. Naomi 24,8 B posts
- 17. Grok 50 B posts
- 18. Bronson 7.251 posts
- 19. Cam Thomas 3.664 posts
- 20. Shinsuke 3.539 posts
Who to follow
-
 Pavel Izmailov
Pavel Izmailov
@Pavel_Izmailov -
 Ziming Liu
Ziming Liu
@ZimingLiu11 -
 Nathan C. Frey
Nathan C. Frey
@nc_frey -
 Jacob Steinhardt
Jacob Steinhardt
@JacobSteinhardt -
 Kasper Green Larsen
Kasper Green Larsen
@kasperglarsen -
 Cheng-Yu Hsieh
Cheng-Yu Hsieh
@cydhsieh -
 Tom Sercu
Tom Sercu
@TomSercu -
 Shikai Qiu
Shikai Qiu
@ShikaiQiu -
 Jannik Kossen
Jannik Kossen
@janundnik -
 Shikhar
Shikhar
@ShikharMurty -
 Johannes Brandstetter
Johannes Brandstetter
@jo_brandstetter -
 Samuel Stanton
Samuel Stanton
@samuel_stanton_ -
 Mazda Moayeri
Mazda Moayeri
@MLMazda -
 Gabriele Corso
Gabriele Corso
@GabriCorso -
 Yiding Jiang
Yiding Jiang
@yidingjiang
Something went wrong.
Something went wrong.