↑ Michael Bukatin ↩🇺🇦
@ComputingByArtsDataflow matrix machines (neuromorphic computations with linear streams). Julia, Python, Clojure, C, Processing. Shaders, ambient, psytrance, 40hz sound.
Similar User

@shahdhruv_

@ait_eth

@XingyouSong

@oren_ai

@lowrank_adrian

@MokadyRon

@VSehwag_

@gbarthmaron

@josephdviviano

@kkahatapitiy

@algroznykh

@thefillm

@shamangary

@davidrd123

@rampasek
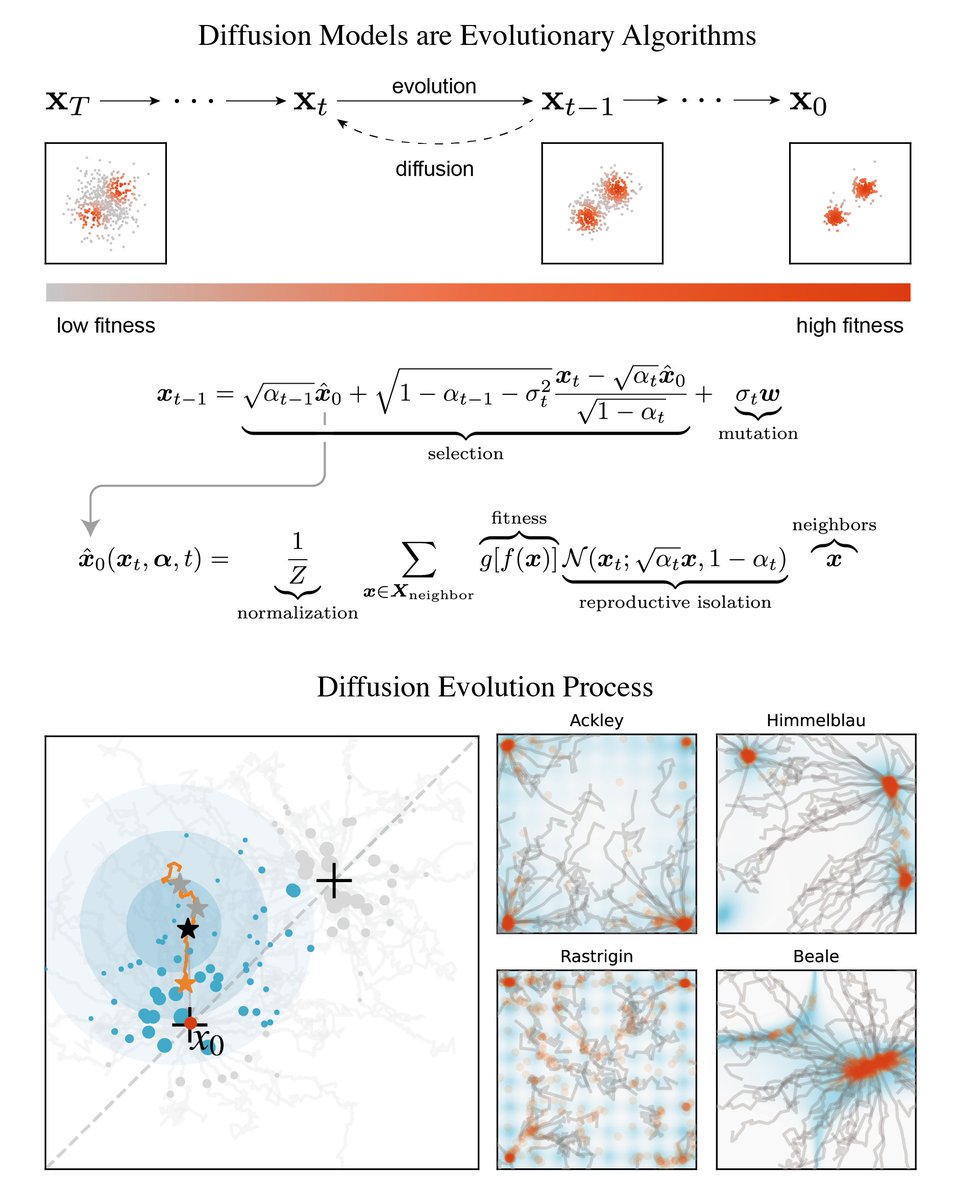
"Diffusion Models are Evolutionary Algorithms" This is an overview by Grigory Sapunov: gonzoml.substack.com/p/diffusion-mo…

Check out our new preprint! arxiv.org/abs/2410.02543 We find that Diffusion Models are Evolutionary Algorithms! By viewing evolution as denoising, we show they share the same mathematical foundation. We then propose Diffusion Evolution (1/n)


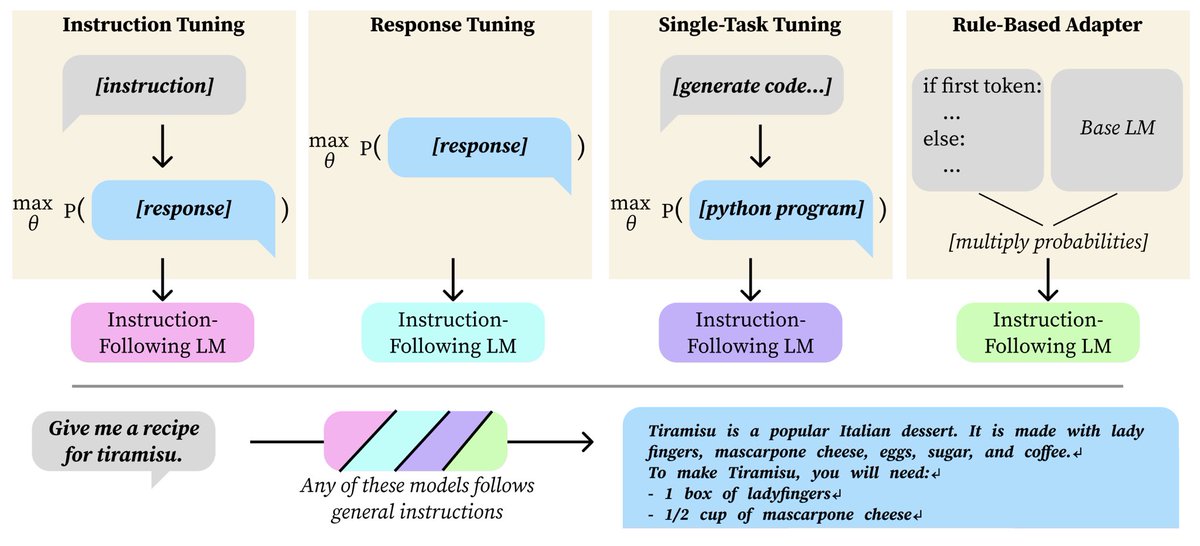
If I finetune my LM just on responses, without conditioning on instructions, what happens when I test it with an instruction? Or if I finetune my LM just to generate poems from poem titles? Either way, the LM will roughly follow new instructions! Paper: arxiv.org/pdf/2409.14254
This is today. This is one of the strongest illustrations of the thesis, "LLMs already know almost everything and can do almost everything, they just need to be unhobbled". I'll repost a twitter thread by the author which is a good starting point.

📢 Join us tomorrow at 10 AM PST for the next DLCT talk featuring @johnhewtt! He’ll dive into "Instruction Following without Instruction Tuning"—exploring innovative approaches to model training and task generalization.

"We recorded this conversation in person. In order to protect Gwern’s anonymity, we created this avatar. This isn’t his voice. This isn’t his face. But these are his words." dwarkeshpatel.com/p/gwern-branwen

dwarkesh's attention to detail is why his podcasts stand out so much. here gwern brings up his essay from 2009 and dwarkesh references a quote from it to transition to the next question



People learning JAX, feel free to reach out if the learning feels too steep, hopefully we can flatten it out. Also, checkout the JAX LLM for help from the community: discord.gg/m9NDrmENe2

This has been and will continue to be my recommendation for anyone in this position. Learn jax and sign up for sites.research.google/trc/about/ Its one of the best things Google has ever done. You can do meaningful research for free, but the learning curve is steep. strap in
"Convolutional Differentiable Logic Gate Networks", NeurIPS oral, arxiv.org/abs/2411.04732

I am thrilled to announce that we have 3 accepted papers @NeurIPSConf, including an Oral 🎉. As of today, they are all available on arXiv. A big thanks to my co-authors @StefanoErmon @HildeKuehne @sutter_tobias @OliverDeussen @julianwelzel0 and Christian Borgelt! @StanfordAILab

Is there a prediction market for the @arcprize coming top score when it closes on Nov 10? (It's currently at 55.5 out of 85 and keeps increasing at a solid clip, but one week does not seem to be enough to close the remaining gap.)
Looks great! "Project Sid: Many-agent simulations toward AI civilization" The paper etc in the github repository:

What will a world look like with 100 billion digital human beings? Today we share our tech report on Project Sid – a glimpse at the first AI agent civilization (powered by our new PIANO architecture). github.com/altera-al/proj… 1/8
This looks really cool ("Fourier Head: Helping Large Language Models Learn Complex Probability Distributions"):

LLMs are powerful sequence modeling tools! They not only can generate language, but also actions for playing video games, or numerical values for forecasting time series. Can we help LLMs better model these continuous "tokens"? Our answer: Fourier series! Let me explain… 🧵(1/n)
Discussion: news.ycombinator.com/item?id=420170…

TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters paper: arxiv.org/abs/2410.23168 repo: github.com/Haiyang-W/Toke… 🤗: huggingface.co/Haiyang-W TokenFormer introduces a scalable Transformer architecture that uses attention not only between input tokens but…
It looks like this is the new text-to-image leader: recraft.ai/blog/recraft-i… @recraftai

Select comparisons between Recraft V3, FLUX1.1 [pro], Midjourney v6.1 and Stable Diffusion 3.5 Large. All images sourced from the Artificial Analysis Image Arena.




Please release the large expensive models! We would appreciate 3.5 Opus @AnthropicAI
New Claude 3.5 Sonnet is weird. Stellar official results, but... The most discerning users are unhappy. Has something bad happened AFTER the progress measurements were taken, or is it the case that discerning users are always in conflict with averages?
So, it's really weird. I am also seeing this degradation report: x.com/VictorTaelin/s… The most discerning users are unhappy. Has something bad happened AFTER the progress measurements were taken, or is it the case that discerning users are always in conflict with averages?
Nice result: arxiv.org/abs/2410.11081

Introducing sCMs: our latest consistency models with a simplified formulation, improved training stability, and scalability. sCMs generate samples comparable to leading diffusion models but require only two sampling steps. openai.com/index/simplify…
"Decomposing The Dark Matter of Sparse Autoencoders" arxiv.org/abs/2410.14670 github.com/JoshEngels/SAE… By @JoshAEngels, Logan Riggs lesswrong.com/users/elriggs, and @tegmark

I’m excited about our new paper on mapping concepts in artificial neural networks with sparse autoencoders: we find that map errors exhibit remarkable structure, splitting into categories, which I’m optimistic can be leveraged to further improve “artificial neuroscience”:
Looks great! And here is, "Depth dweller: translating art code between Processing and Wolfram languages using ChatGPT o1 and 4o" by @superflow: community.wolfram.com/groups/-/m/t/3…

a=(x,y,d=5*cos(o=mag(k=x/8-25,e=y/8-25)/3))=>[(q=x/2+k/atan(9*cos(e))*sin(d*4-t))*sin(c=d/3-t/8)+200,(y/4+5*o*o+q)/2*cos(c)+200] t=0,draw=$=>{t||createCanvas(w=400,w);background(6).stroke(255,96);for(t+=PI/60,y=99;++y<300;)for(x=99;++x<300;)point(...a(x,y))} //#つぶやきProcessing





































































































United States Trends
- 1. #JusticeforDogs N/A
- 2. ICBM 173 B posts
- 3. $EFR 2.127 posts
- 4. The ICC 200 B posts
- 5. #AcousticGuitarCollection 1.997 posts
- 6. #KashOnly 34,8 B posts
- 7. Netanyahu 452 B posts
- 8. Denver 29,5 B posts
- 9. $CUTO 9.304 posts
- 10. Katie Couric 1.746 posts
- 11. chenle 112 B posts
- 12. #ATSD 8.723 posts
- 13. #AtinySelcaDay 8.372 posts
- 14. DeFi 129 B posts
- 15. Bezos 37,3 B posts
- 16. International Criminal Court 95,2 B posts
- 17. CPAP N/A
- 18. GM Elon N/A
- 19. Unvaccinated 12,5 B posts
- 20. Volvo 4.029 posts
Who to follow
-
 Dhruv Shah
Dhruv Shah
@shahdhruv_ -
 AIT Lab
AIT Lab
@ait_eth -
 Richard Song
Richard Song
@XingyouSong -
 Eris (Discordia, הרס, Sylvie, Lilith, blahblah, 🙄
Eris (Discordia, הרס, Sylvie, Lilith, blahblah, 🙄
@oren_ai -
 Adrian Valente
Adrian Valente
@lowrank_adrian -
 Ron Mokady
Ron Mokady
@MokadyRon -
 Vikash Sehwag
Vikash Sehwag
@VSehwag_ -
 Gabriel Barth-Maron
Gabriel Barth-Maron
@gbarthmaron -
 Joseph Viviano
Joseph Viviano
@josephdviviano -
 Kumara Kahatapitiya
Kumara Kahatapitiya
@kkahatapitiy -
 Alex Groznykh
Alex Groznykh
@algroznykh -
 Jan Feyereisl
Jan Feyereisl
@thefillm -
 Tsun-Yi Yang 楊存毅 🇹🇼🏳️🌈
Tsun-Yi Yang 楊存毅 🇹🇼🏳️🌈
@shamangary -
 ~D
~D
@davidrd123 -
 Ladislav Rampasek
Ladislav Rampasek
@rampasek
Something went wrong.
Something went wrong.