
Yike Wang
@yikewang_PhD student @uwcse @uwnlp | BA, MS @UCBerkeley
What should be the desirable behaviors of LLMs when knowledge conflicts arise? Are LLMs currently exhibiting those desirable behaviors? Introducing KNOWLEDGE CONFLICT arxiv.org/abs/2310.00935

Curious about copyright implications of LLMs beyond verbatim regurgitation? talk to @tomchen0 about CopyBench @emnlpmeeting! We find that non-literal copying can surface in instruction-tuned models, in some cases even more than base models & more than verbatim copying!…
📢Anyone who talked to me in the past year heard my rant of *LLM memorization is beyond form* & output overlap! ©️Reproducing similar series of events, or character traits also has copyright issues. 👩⚖️In new work we look at non-literal copying in LLMs! arxiv.org/abs/2407.07087


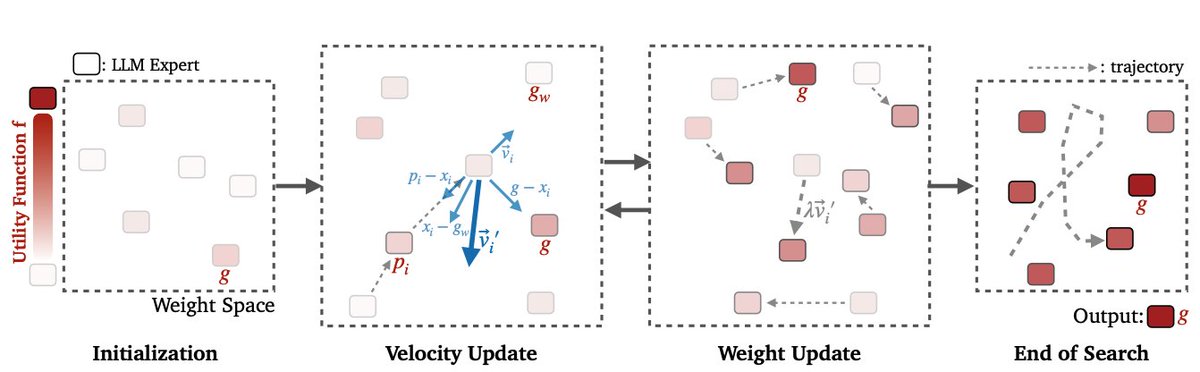
Model Swarms Researchers from Google and UoW propose a new collaborative search algorithm to adapt LLM via swarm intelligence. A pool of LLM experts collaboratively move in the weight space and optimize a utility function representing various adaptation objectives. Top quote:…


Excited to present at #EMNLP next week on personalized LLM. Also, I’m looking for an internship—let’s connect! Personalized PEFT: arxiv.org/abs/2402.04401 Nov 13, 10:30, Riverfront Parameter Composition for Personalized PEFT: arxiv.org/abs/2406.10471 Nov 12, 11:00, Riverfront

Excited to share that I will be at #EMNLP2024 presenting our work Communicate to Play with @sashrika_ ! 🎊 🕑Session 12 14:00 - 15:30 📍Jasmine - Lower Terrace Level Come chat about LLM agents, cultural considerations in NLP, and AI for games!


Excited to share that I will be joining Princeton Computer Science @PrincetonCS as an Assistant Professor in September 2025! I'm looking for students to join me. If you are interested in working with me on VLMs, LLMs, deep learning (vision/LLM) architectures, data, training,…
let’s find better adapted models using swarm intelligence 👻

👀 How to find a better adapted model? ✨ Let the models find it for you! 👉🏻 Introducing Model Swarms, multiple LLM experts collaboratively search for new adapted models in the weight space and discover their new capabilities. 📄 Paper: arxiv.org/abs/2410.11163

For this week’s NLP Seminar, we are thrilled to host @WeijiaShi2 to talk about "Beyond Monolithic Language Models"! When: 10/17 Thurs 11am PT Non-Stanford affiliates registration form (closed at 9am PT on the talk day): forms.gle/PKcLJZ4aYR2gta…

📌 Wed 11:00 Poster Session 5 super glad to attend the very first COLM 🦙! I’ll be presenting a work on knowledge conflicts on wednesday. welcome to stop by and chat 🩵
What should be the desirable behaviors of LLMs when knowledge conflicts arise? Are LLMs currently exhibiting those desirable behaviors? Introducing KNOWLEDGE CONFLICT arxiv.org/abs/2310.00935

very excited to attend the first @COLM_conf!🤩 I will be presenting proxy-tuning as a spotlight talk🔦 on Wed @ 10am. I would love to make new friends and chat about decoding-time algorithms, tokenizers, and whatever is on your mind!
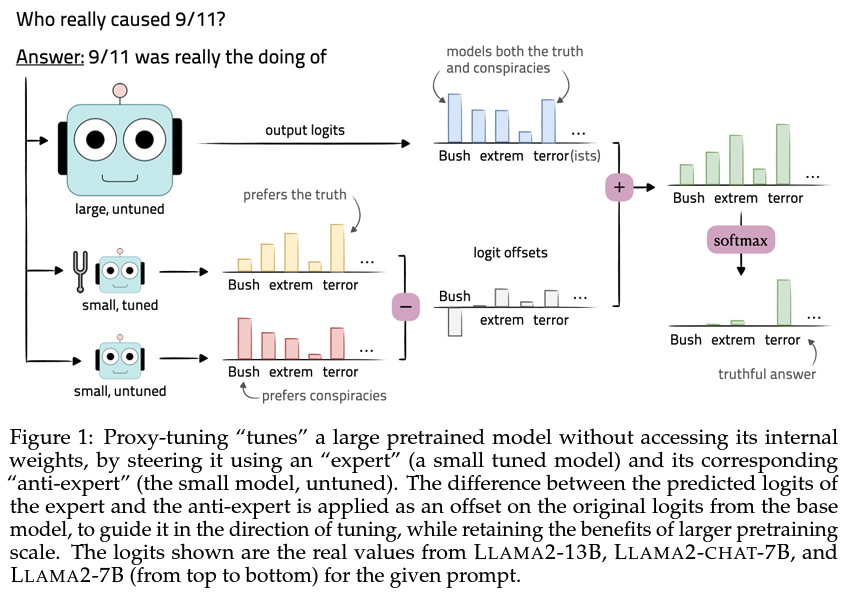
LMs are increasingly large🐘 and proprietary🔒 — what if we could “tune”🔧 them without accessing their internal weights? Enter: proxy-tuning, which operates on only the *outputs* of LMs at decoding-time to achieve the effect of direct tuning! 📄: arxiv.org/abs/2401.08565 1/

I will be at @COLM_conf to give a spotlight talk on infini-gram (Wednesday 10am) and a poster on PPO-MCTS (also Wed morning). Look forward to catch up with old friends and meet new friends! Catch me to chat about text corpora, LM pretraining, scaling laws, decoding, etc.! 😀


I will be @COLM_conf! Reach out if you wanna chat Privacy, Regulations, Memorization, and Reasoning in LLMs! You can also find me presenting: 1. Do Membership Inference Attacks Work on Large Language Models? arxiv.org/abs/2402.07841 2. Discovering Personal Disclosures in…



Molmo, our first open multimodal language model, is here; we've equipped our OLMo with eyes! 👀 ✨ Molmo: Raising the bar and outperforming the latest Llama 3.2 models. 🚀 Molmo-72B: Competes head-to-head with leading proprietary models. 🔥 MolmoE-1B: Ultra-efficient,…


👽Have you ever accidentally opened a .jpeg file with a text editor (or a hex editor)? Your language model can learn from these seemingly gibberish bytes and generate images with them! Introducing *JPEG-LM* - an image generator that uses exactly the same architecture as LLMs…


Presenting this today at #ACL2024/#ACL2024NLP 🐘 🕹️10:30-11:00: Wordplay poster session 📢11:15-11:45: C3NLP Lightning Talk (Lotus 3) 🕹️12:40-13:40: Wordplay poster session 🕹️15:30-16:00: Wordplay poster session ✨16:00-17:10: C3NLP poster session Say hi! 🤩
(1/n) Check out our new paper Communicate to Play! 📜 We study cross-cultural communication and pragmatic reasoning in interactive gameplay 😃 Paper: arxiv.org/abs/2408.04900 Code: github.com/icwhite/codena… Talk: youtube.com/watch?v=r_tNbZ…

💪🏻 thanks @aclmeeting for the Outstanding Paper Award and Area Chair Award (QA track), congrats @shangbinfeng 🪝feel free to check our work on identifying knowledge gaps via multi-LLM collaboration on arxiv.org/abs/2402.00367
Thank you for the double awards! #ACL2024 @aclmeeting Area Chair Award, QA track Outstanding Paper Award huge thanks to collaborators!!! @WeijiaShi2 @YikeeeWang @Wenxuan_Ding_ @vidhisha_b @tsvetshop

Congrats to our team for winning two paper awards at #ACL2024! OLMo won the Best Theme Paper award, and Dolma won a Best Resource Paper award! All the credit goes to the whole team for the massive group effort 🎉🎉





check out our paper Communicate to Play on informing gameplay with culturally conditioned AI at #ACL2024NLP - catch @isadorcw and me on Friday at the Wordplay and C3NLP workshops! 🔗 paper: arxiv.org/abs/2408.04900 🔗 code: github.com/icwhite/codena…

📍Poster Session 6 (wed 10:30-12:00) @Wenxuan_Ding_ and I are waiting for u 🍿
Don't hallucinate, abstain! #ACL2024 "Hey ChatGPT, is your answer true?" Sadly LLMs can't reliably self-eval/self-correct :( Introducing teaching LLMs to abstain via multi-LLM collaboration! A thread 🧵

🌱 Now Accepted to COLM 🌱 Big thanks to all my collaborators and dear @tsvetshop💕 and welcome to check out this work on knowledge conflicts✨
What should be the desirable behaviors of LLMs when knowledge conflicts arise? Are LLMs currently exhibiting those desirable behaviors? Introducing KNOWLEDGE CONFLICT arxiv.org/abs/2310.00935
Don't hallucinate, abstain! #ACL2024 "Hey ChatGPT, is your answer true?" Sadly LLMs can't reliably self-eval/self-correct :( Introducing teaching LLMs to abstain via multi-LLM collaboration! A thread 🧵












































































United States Trends
- 1. #UFC309 306 B posts
- 2. Jon Jones 181 B posts
- 3. Jon Jones 181 B posts
- 4. Jon Jones 181 B posts
- 5. Chandler 88,8 B posts
- 6. Oliveira 73,1 B posts
- 7. Kansas 23,3 B posts
- 8. #discorddown 6.909 posts
- 9. Bo Nickal 9.106 posts
- 10. Do Bronx 11,2 B posts
- 11. ARod 2.190 posts
- 12. #BYUFootball 1.417 posts
- 13. Dana 265 B posts
- 14. Rock Chalk 1.423 posts
- 15. Pereira 11,1 B posts
- 16. #kufball 1.119 posts
- 17. #MissUniverse 442 B posts
- 18. Big 12 16,7 B posts
- 19. Keith Peterson 1.396 posts
- 20. Tennessee 52,7 B posts
Something went wrong.
Something went wrong.