
Yiheng Xu
@yihengxu_digital ai agent research @hkuniversity | ex @msftresearch | layoutlm / lemur / aguvis | from automation to autonomy
Similar User

@TianbaoX

@ikekong

@jinyang34647007

@_TobiasLee

@qx_dong

@MingZhong_

@JiachengYe15

@redoragd

@Siru_Ouyang

@ChenHenryWu

@beichen1019

@ChengZhoujun

@bailin_28

@YifeiLiPKU

@jiahuigao3
Very happy to share that Lemur has been accepted to #ICLR2024 as a spotlight! 🥳 Great thanks to all my amazing coauthors!
1/ 🧵 🎉 Introducing Lemur-70B & Lemur-70B-Chat: 🚀Open & SOTA Foundation Models for Language Agents! The closest open model to GPT-3.5 on 🤖15 agent tasks🤖! 📄Paper: arxiv.org/abs/2310.06830 🤗Model @huggingface : huggingface.co/OpenLemur More details 👇


🚀 Excited to introduce a new member of the OS-Copilot family: OS-Atlas - a foundational action model for GUI agents Paper: huggingface.co/papers/2410.23… Website: osatlas.github.io A thread on why this matters for the future of OS automation 🧵 TL;DR: OS-Atlas offers: 1.…


Splashdown confirmed! Congratulations to the entire SpaceX team on an exciting fifth flight test of Starship!

We're launching SWE-bench Multimodal to eval agents' ability to solve visual GitHub issues. - 617 *brand new* tasks from 17 JavaScript repos - Each task has an image! Existing agents struggle here! We present SWE-agent Multimodal to remedy some issues Led w/ @_carlosejimenez 🧵


Just took a look at the ICLR '25 submissions. 1. 👀 LLMs are still crushing it as the TOP-1 topic this year, with diffusion models in the next position. 2. 🤔 Evaluation & benchmarks might be what we should focus more on in the future, because making something like O1 or…


🚀 Still relying on human-crafted rules to improve pretraining data? Time to try Programming Every Example(ProX)! Our latest efforts use LMs to refine data with unprecedented accuracy, and brings up to 20x faster training in general and math domain! 👇 Curious about the details?

After months of efforts, we are pleased to announce the evolution from Qwen1.5 to Qwen2. This time, we bring to you: ⭐ Base and Instruct models of 5 sizes, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B. Having been trained on data in 27 additional…



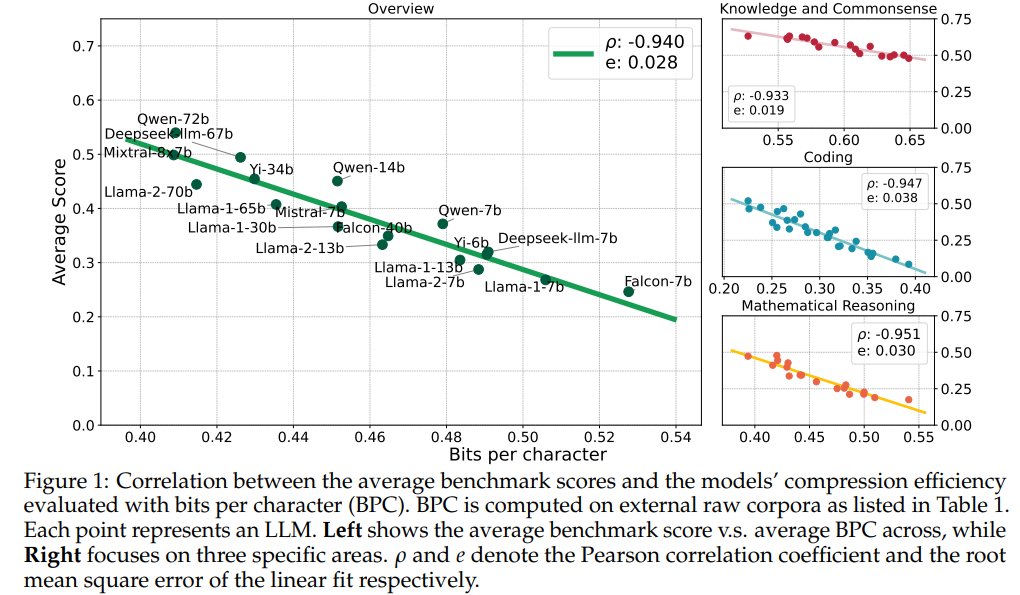
Downstream scores can be noisy. If you wonder about Llama 3's compression perf in this figure, we have tested the BPC: Llama3 8B: 0.427, best at its size, comparable to Yi-34B Llama3 70B: 0.359, way ahead of all the models here Details at github.com/hkust-nlp/llm-…

Compression Represents Intelligence Linearly LLMs' intelligence – reflected by average benchmark scores – almost linearly correlates with their ability to compress external text corpora repo: github.com/hkust-nlp/llm-… abs: arxiv.org/abs/2404.09937

🔥 Do you want an open and versatile code assistant? Today, we are delighted to introduce CodeQwen1.5-7B and CodeQwen1.5-7B-Chat, are specialized codeLLMs built upon the Qwen1.5 language model! 🔋 CodeQwen1.5 has been pretrained with 3T tokens of code-related data and exhibits…


🚀Multimodal agents is on rise in 2024! But even building app/domain-specific agent env is hard😰. Our real computer OSWorld env allows you to define agent tasks about arbitrary apps on diff. OS w.o crafting new envs. 🧐Benchmarked #VLMs on 369 OSWorld tasks: #GPT4V >> #Claude3

🤔Can we assess agents across various apps & OS w.o. crafting new envs? OSWorld🖥️: A unified, real computer env for multimodal agents to evaluate open-ended computer tasks with arbitrary apps and interfaces on Ubuntu, Windows, & macOS. + annotated 369 real-world computer tasks…
🤔Can we assess agents across various apps & OS w.o. crafting new envs? OSWorld🖥️: A unified, real computer env for multimodal agents to evaluate open-ended computer tasks with arbitrary apps and interfaces on Ubuntu, Windows, & macOS. + annotated 369 real-world computer tasks…
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments The first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating…

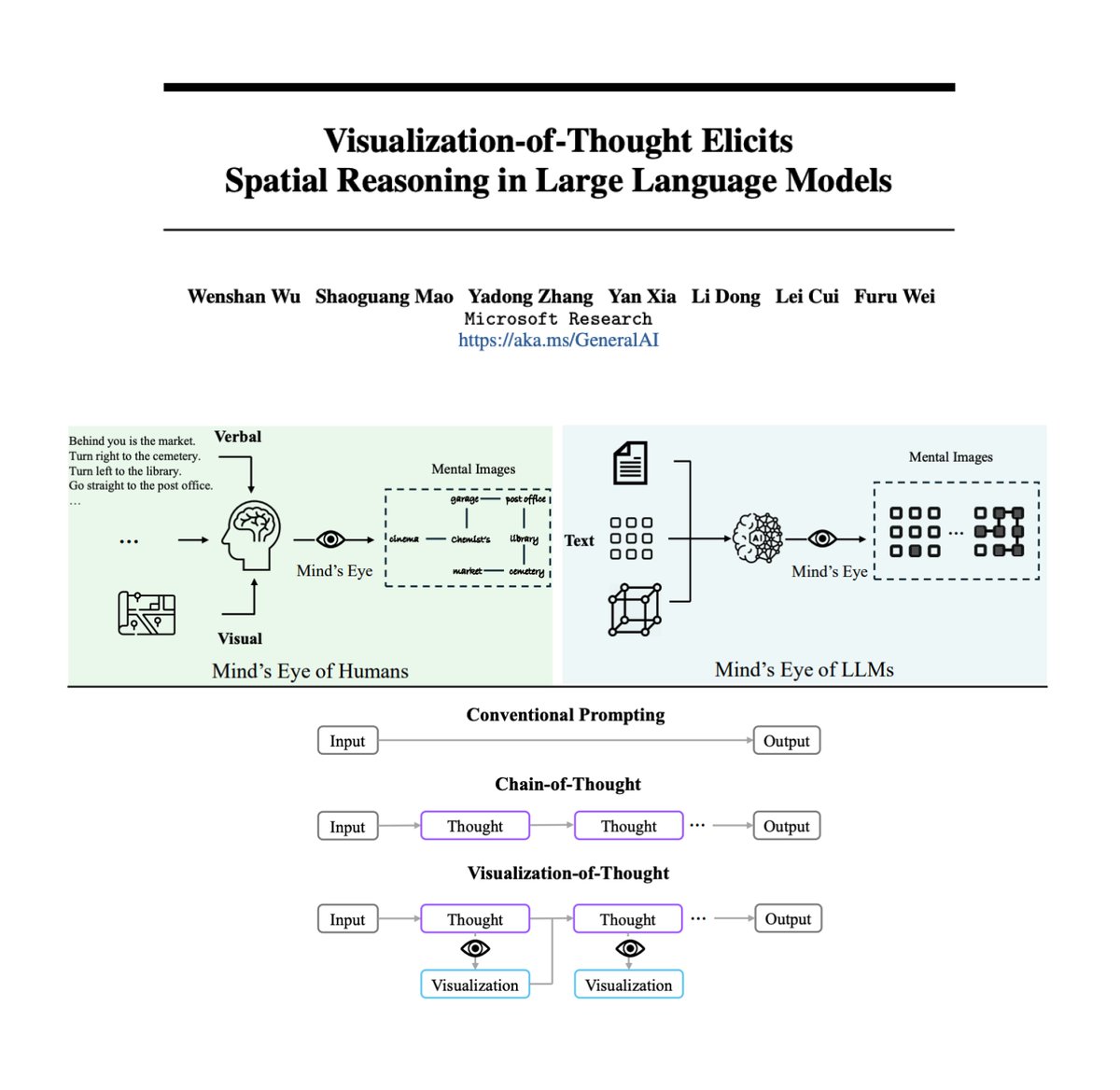
Visualization-of-Thoughts (VoT): Mind's Eye of LLMs

SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source! We designed a new agent-computer interface to make it easy for GPT-4 to edit+run code github.com/princeton-nlp/…


Our arxiv preprint is released now! 🔗: arxiv.org/abs/2403.15452 If you know other awesome papers on tool use in LLMs, please let us know and feel free to open a PR! 👩💻: github.com/zorazrw/awesom…
Tools can empower LMs to solve many tasks. But what are tools anyway? github.com/zorazrw/awesom… Our survey studies tools for LLM agents w/ –A formal def. of tools –Methods/scenarios to use&make tools –Issues in testbeds and eval metrics –Empirical analysis of cost-gain trade-off



Wanna train a SOTA reward model? 🌟New Blog Alert: "Reward Modeling for RLHF" (with @weixiong_1 & @RuiYang70669025) is live this weekend! 🌐✨ We delve into the insights behind achieving groundbreaking performance on the RewardBench (by @natolambert). efficient-unicorn-451.notion.site/Reward-Modelin…


🎉🎉We are excited to release a full package for AI Agent R&D: 1) For Data & Training, 🎙️AgentOhana🎙️: Design Unified Data and Training Pipeline for Effective Agent Learning. 2) For model, 🔥xLAM-v0.1-R🔥: A strong large action model for AI Agent while maintaining abilities on…


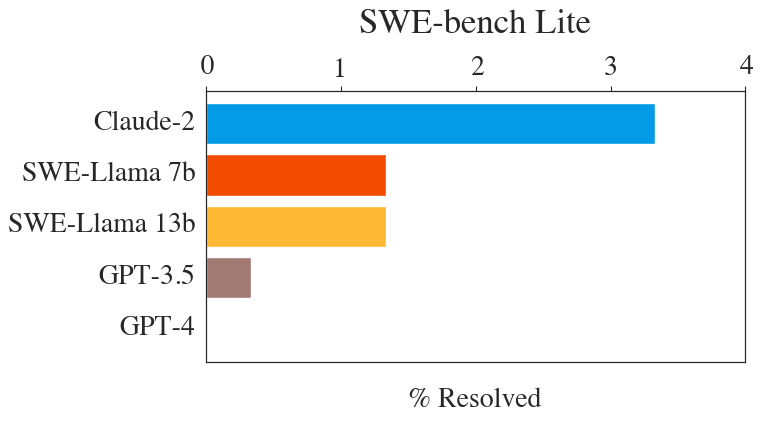
Since we released SWE-bench, we've been asked for a smaller & slightly easier subset of the benchmark, to make it easier to develop and test new ideas in language modeling for code. Today we're releasing SWE-bench Lite. By @_carlosejimenez @jyangballin @JiayiiGeng!

SWE-bench Lite is a smaller & slightly easier *subset* of SWE-bench, with 23 dev / 300 test examples (full SWE-bench is 225 dev / 2,294 test). We hopes this makes SWE-bench evals easier. Special thanks to @JiayiiGeng for making this happen. Download here: swebench.com/lite
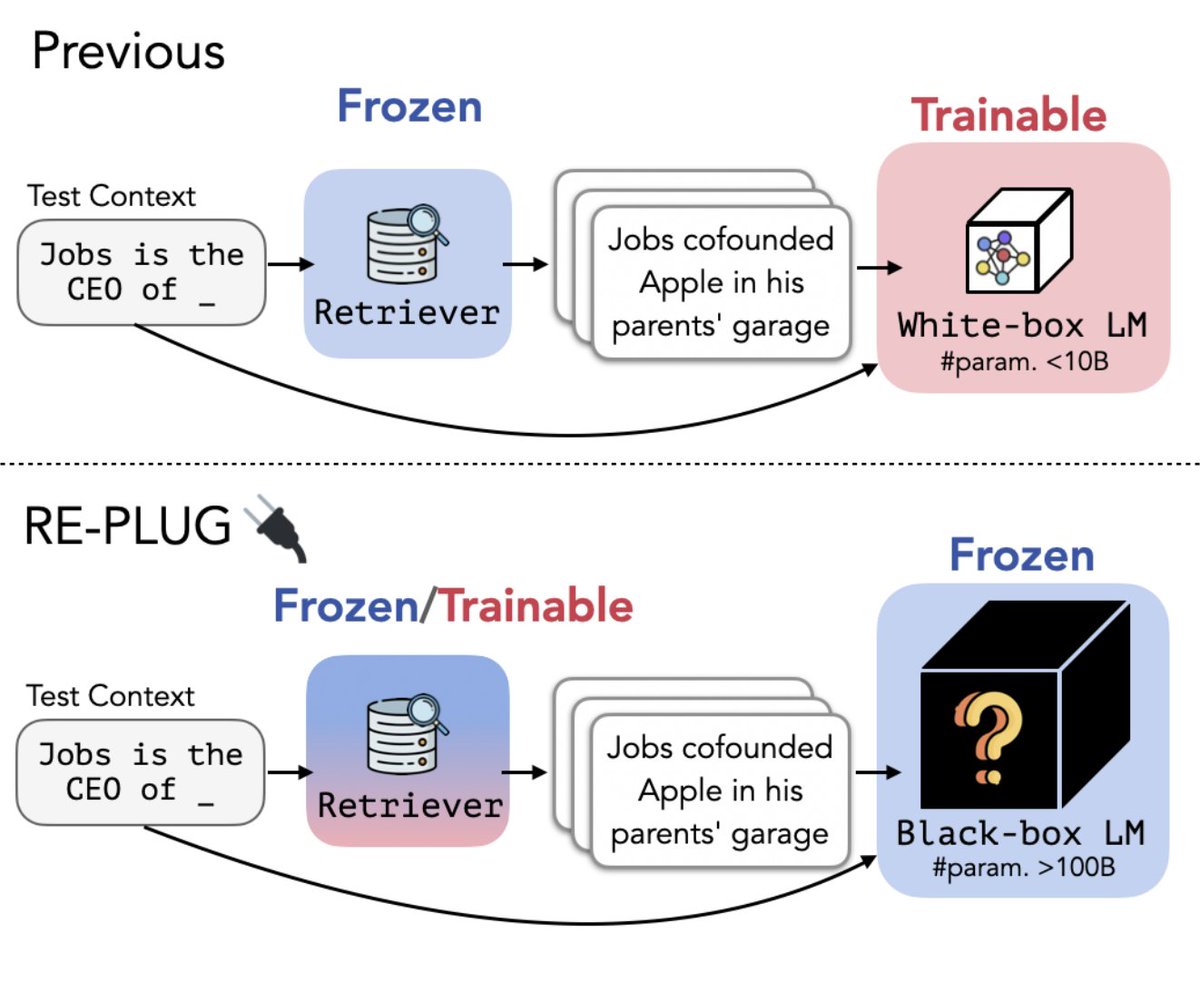
Happy to share REPLUG🔌 is accepted to #NAACL2024 Introduce a retrieval-augmented LM framework that combines a frozen LM with a frozen/tunable retriever. Improving GPT-3 in language modeling & downstream tasks by prepending retrieved docs to LM inputs arxiv.org/abs/2301.12652























































































United States Trends
- 1. Thanksgiving 439 B posts
- 2. $CUTO 7.408 posts
- 3. Custom 69,2 B posts
- 4. #AskJage N/A
- 5. Dodgers 60,5 B posts
- 6. #MigglesArmy 3.549 posts
- 7. #WednesdayMotivation 5.242 posts
- 8. SKZ HOP UNVEIL UNFAIR 22,8 B posts
- 9. UNTITLED UNMASTERED N/A
- 10. FELIX UNFAIR MV UNVEIL 22,7 B posts
- 11. #DeFi 26,1 B posts
- 12. Good Wednesday 28,8 B posts
- 13. Wrecking 15 B posts
- 14. DB Cooper 4.118 posts
- 15. #sociprovider N/A
- 16. Sharon Stone 25,1 B posts
- 17. Landman 3.335 posts
- 18. Dan Crenshaw 3.498 posts
- 19. Lake Michigan N/A
- 20. Hump Day 15,4 B posts
Who to follow
-
 Tianbao Xie
Tianbao Xie
@TianbaoX -
 Lingpeng Kong
Lingpeng Kong
@ikekong -
 jinyang (patrick) li
jinyang (patrick) li
@jinyang34647007 -
 Lei Li
Lei Li
@_TobiasLee -
 Qingxiu Dong
Qingxiu Dong
@qx_dong -
 Ming Zhong
Ming Zhong
@MingZhong_ -
 Jiacheng Ye
Jiacheng Ye
@JiachengYe15 -
 Gordon Lee🍀
Gordon Lee🍀
@redoragd -
 Siru Ouyang
Siru Ouyang
@Siru_Ouyang -
 Chen Wu
Chen Wu
@ChenHenryWu -
 Bei Chen
Bei Chen
@beichen1019 -
 Zhoujun (Jorge) Cheng
Zhoujun (Jorge) Cheng
@ChengZhoujun -
 Bailin Wang
Bailin Wang
@bailin_28 -
 Yifei Li
Yifei Li
@YifeiLiPKU -
 Jiahui Gao
Jiahui Gao
@jiahuigao3
Something went wrong.
Something went wrong.