
Nelly Papalampidi
@pinelopip3Research Scientist @GoogleDeepMind working on understanding and generating videos from multimodal inputs. PhD @InfAtEd @EdinburghNLP. Ex @MetaAI
Similar User

@nsaphra

@kayo_yin

@PSH_Lewis

@sjmielke

@sarahwiegreffe

@PontiEdoardo

@machelreid

@tomsherborne

@dan_fried

@PMinervini

@andre_t_martins

@rajammanabrolu

@anjalie_f

@JesseDodge

@raquel_dmg
Large multimodal models understand images/clips, but what about longer contexts? We propose a memory-efficient approach for training on long videos and show that our 1B model outperforms LLMs used as information-aggregator over large image captioners. arxiv.org/abs/2312.07395


We are hiring on the Generative Media team in London: boards.greenhouse.io/deepmind/jobs/… We work on Imagen, Veo, Lyria and all that good stuff. Come work with us! If you're interested, don't delay -- apply before 5PM tomorrow (UK time).
Exciting to see Veo in the hands of creators on YouTube ✨

On @YouTube, we want creators to be able to express their creativity, build community + drive long-lasting businesses. New tools at #MadeOnYouTube are helping: we’re bringing Veo to Dream Screen to create high-quality, custom backgrounds on Shorts + more. blog.youtube/news-and-event…
I'm in Novi Sad 🇷🇸 all week for #EEML2024, where I'll be talking about, you guessed it, diffusion models! Then on to Vienna 🇦🇹 next week for #ICML2024, where I'll be doing more of the same 🤷 at the workshop on controllable video generation.

EEML2024 is fast approaching! The school starts on Monday July 15th, in Novi Sad Serbia 🇷🇸, with an Intro to Deep Learning by @alfcnz, Generative AI+SSL by @sedielem, AI for Science by @weballergy, and Reasoning tutorial by @PetarV_93 and @backprop2seed 🎉. See thread for details

✨PaliGemma report will hit arxiv tonight. We tried hard to make it interesting, and not "here model. sota results. kthxbye." So here's some of the many interesting ablations we did, check the paper tomorrow for more! 🧶


Our PaliGemma tech report is out! 🚀 arxiv.org/abs/2407.07726 WebLI -> SigLIP -> PaliGemma, what an incredible journey it's been with my amazing colleagues!
✨PaliGemma report will hit arxiv tonight. We tried hard to make it interesting, and not "here model. sota results. kthxbye." So here's some of the many interesting ablations we did, check the paper tomorrow for more! 🧶

We're excited to release TAPVid-3D: an evaluation benchmark of 4,000+ real world videos and 2.1 million metric 3D point trajectories, for the task of Tracking Any Point in 3D!

Excited to share our new preprint on data curation for large scale multimodal learning (arxiv.org/abs/2406.17711)! TLDR; 1) we show that picking good batches of data is more important than selecting data points independently, 2) online model approximation can be used to filter…

We are going to present PaliGemma demo 2:30pm today, come to the Google booth and talk to me, @giffmana and @__kolesnikov__ in person about any topics around multimodal data, models and fairness.



🚀 Excited to share our latest work @GoogleDeepMind: "Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings" 🧵 #VLM #Synthetic #AI arxiv.org/abs/2403.07750
In Seattle for @CVPR and we will present our work on long video-language pre-training w/ @pathak__shreya and Joe Heyward on Thursday 10:30 am PDT @ Arch 4A-E Poster #458. Stop by to discuss about long video pre-training and understanding or ping me if you are around at the conf!
Large multimodal models understand images/clips, but what about longer contexts? We propose a memory-efficient approach for training on long videos and show that our 1B model outperforms LLMs used as information-aggregator over large image captioners. arxiv.org/abs/2312.07395

MC-ViT will appear as a spotlight paper at #ICML2024! Come chat to @olivierhenaff, @pinelopip3, @YugeTen and myself in Vienna if you’re interested in simple and effective long-context video understanding.

Humans and animals reason about events spanning days, weeks, and years, yet current CV systems live largely in the present. Introducing Memory-Consolidated ViT, whose context extends far into the past and sets a new SOTA in long-video understanding with a 10x smaller model
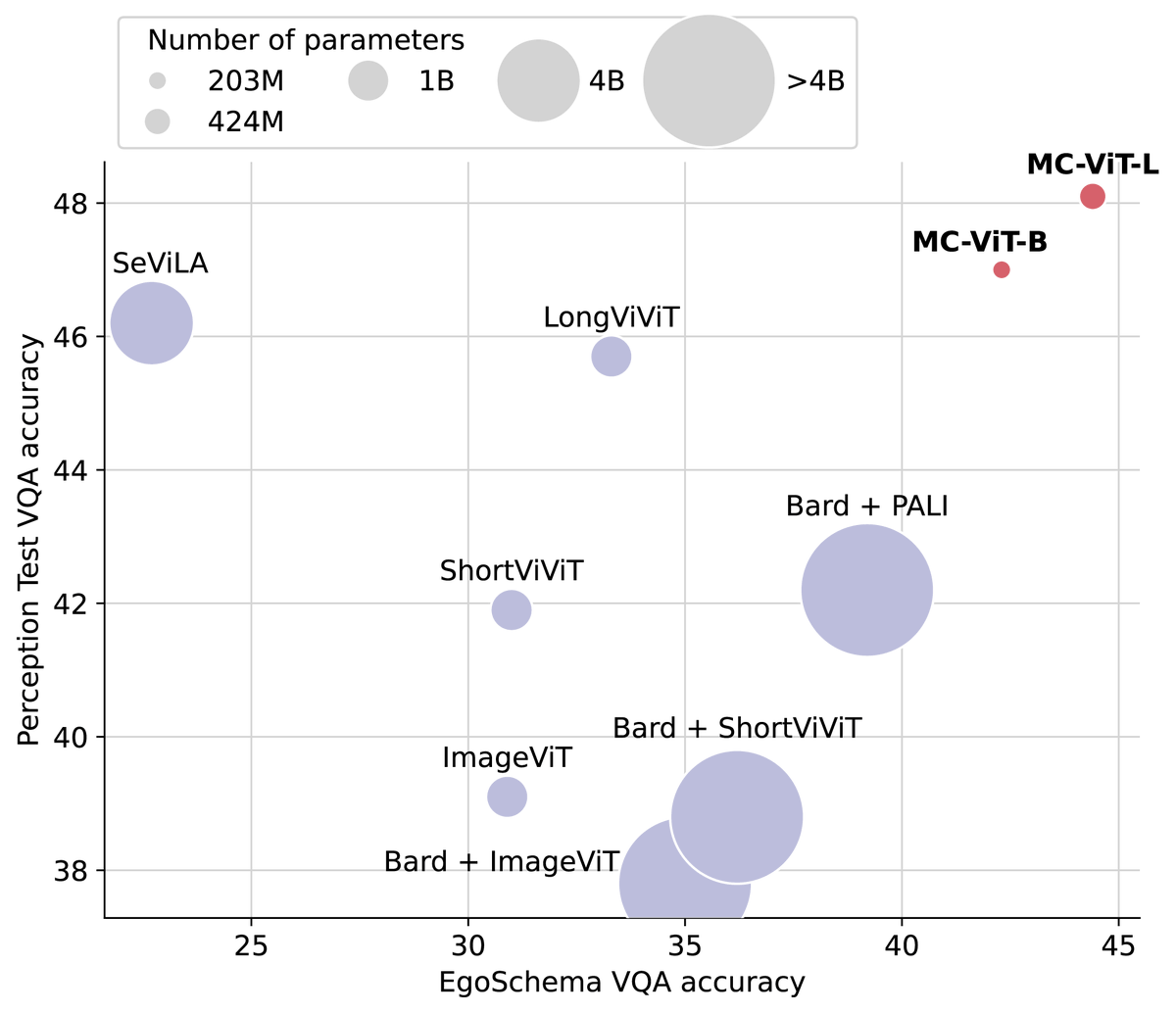

Last week at NYU graduation, @ebetica asked me: So is Gemini any good? I’ve been hearing this question a lot, and decided to show you myself! 🙌 I made a colab for you to try out our spatial understanding capabilities using the API key from AI Studio. Currently FREE! 🧵
Highly recommend to check out this work! Given the impressive image gen quality nowadays, text alignment is often overlooked. But testing alignment to users' intentions should be top priority and now there is a robust benchmark and metric to do so.

Check out Gecko 🦎: @GoogleDeepMind's latest work looking at how to evaluate text-to-image technology with: 📊 a new benchmark 🕵️ 100K+ human ratings of state-of-the-art T2I models 🤖 a better human-correlated auto-eval metric arxiv.org/abs/2404.16820

Looking forward to AthNLP 2024! Thanks to the fantasic speakers who will join us: @anas_ant @raquel_dmg @fhuszar @MKrallinger Mirella Lapata Ryan McDonald @aidanematzadeh @vnfrombucharest @barbara_plank @annargrs ! Deadline for applications 20th of June! athnlp.github.io/2024/cfp.html

📢Speakers announced for #AthNLP2024 International Summer School! ❗️Don't miss the opportunity to meet in person with the roster of ✨tutors in the field of #NaturalLanguageProcessing at the upcoming Athens Natural Language Processing Summer School! athnlp.github.io/2024/speakers.…


We evaluate the 3 main aspects involved in the evaluation of MM/image generative models: (1) the prompt set (2) the metric (3) the human data. Will be releasing our benchmark soon, including a subset with high human agreement to be used to evaluate image--text alignment metrics!
Check out Gecko 🦎: @GoogleDeepMind's latest work looking at how to evaluate text-to-image technology with: 📊 a new benchmark 🕵️ 100K+ human ratings of state-of-the-art T2I models 🤖 a better human-correlated auto-eval metric arxiv.org/abs/2404.16820
Very excited to see Veo out 🚀

Introducing Veo: our most capable generative video model. 🎥 It can create high-quality, 1080p clips that can go beyond 60 seconds. From photorealism to surrealism and animation, it can tackle a range of cinematic styles. 🧵 #GoogleIO
We’re introducing new additions to Gemma: our family of open models built with the same technology as Gemini. 🔘 PaliGemma: a powerful open vision-language model 🔘 Gemma 2: coming soon in various sizes, including 27 billion parameters → dpmd.ai/3QKEteK #GoogleIO

We release PaliGemma. I'll keep it short, still on vacation: - sota open base VLM designed to transfer quickly, easily, and strongly to a wide range of tasks - Also does detection and segmentation - We provide lots of examples - Meaty tech report later! ai.google.dev/gemma/docs/pal…

Congrats Tom 🥳 I wish I was in Edi to celebrate with you!
I passed my PhD viva today! Thanks to @iatitov and @LukeZettlemoyer for examining me. See you at Doctor’s @ 6PM

Super excited about the new SIMA agent and very happy that our work on SPARC is powering the SIMA image encoders! 🥳🚀🕹️SPARC 🌟provides both fine-grained image-text alignment and it also enables the agent to utilize the knowledge gained through internet-scale pretraining.

Introducing SIMA: the first generalist AI agent to follow natural-language instructions in a broad range of 3D virtual environments and video games. 🕹️ It can complete tasks similar to a human, and outperforms an agent trained in just one setting. 🧵 dpmd.ai/3TiYV7d









































































































United States Trends
- 1. Kendrick 212 B posts
- 2. Daniel Jones 37,2 B posts
- 3. Luther 21,6 B posts
- 4. #TSTTPDSnowGlobe 4.515 posts
- 5. $CUTO 4.769 posts
- 6. Squabble Up 10,5 B posts
- 7. Giants 69,6 B posts
- 8. Kdot 4.035 posts
- 9. TV Off 14,3 B posts
- 10. Kenny 20,2 B posts
- 11. Wayne 31,2 B posts
- 12. Reincarnated 11,2 B posts
- 13. Dodger Blue 4.026 posts
- 14. Danny Dimes 1.265 posts
- 15. Muppets 6.939 posts
- 16. One Mic 3.522 posts
- 17. Jack Antonoff 2.081 posts
- 18. #StrayKids_dominATE 5.872 posts
- 19. Heart Pt 7.752 posts
- 20. Wacced Out Murals 13,6 B posts
Who to follow
-
 Naomi Saphra 🧈🪰
Naomi Saphra 🧈🪰
@nsaphra -
 Kayo Yin @ EMNLP
Kayo Yin @ EMNLP
@kayo_yin -
 Patrick Lewis
Patrick Lewis
@PSH_Lewis -
 Sabrina J. Mielke
Sabrina J. Mielke
@sjmielke -
 Sarah Wiegreffe (on faculty job market!)
Sarah Wiegreffe (on faculty job market!)
@sarahwiegreffe -
 Edoardo Ponti
Edoardo Ponti
@PontiEdoardo -
 Machel Reid
Machel Reid
@machelreid -
 Tom Sherborne
Tom Sherborne
@tomsherborne -
 Daniel Fried
Daniel Fried
@dan_fried -
 Pasquale Minervini
Pasquale Minervini
@PMinervini -
 Andre Martins
Andre Martins
@andre_t_martins -
 Prithviraj (Raj) Ammanabrolu
Prithviraj (Raj) Ammanabrolu
@rajammanabrolu -
 Anjalie Field
Anjalie Field
@anjalie_f -
 Jesse Dodge
Jesse Dodge
@JesseDodge -
 Raquel Fernández
Raquel Fernández
@raquel_dmg
Something went wrong.
Something went wrong.