
Emanuele Bugliarello
@ebugliarelloMultimodal researcher @GoogleDeepMind. He/him
Similar User

@delliott

@EdinburghNLP

@CopeNLU

@royschwartzNLP

@ybisk

@boknilev

@anas_ant

@PontiEdoardo

@annargrs

@licwu

@sarahwiegreffe

@dan_fried

@KreutzerJulia

@iatitov

@byryuer
Wouldn’t it be cool if AI could help us generate movies?🎬 We built a new benchmark to measure progress in this direction🍿 “StoryBench: A Multifaceted Benchmark for Continuous Story Visualization” 📄 arxiv.org/abs/2308.11606 👩💻 github.com/google/storybe… 📈 paperswithcode.com/dataset/storyb…


Our team at Google DeepMind is seeking a Research Scientist with a strong publication record (multiple first-author papers) on multi-modal LLMs in top ML venues like NeurIPS, ICLR, CVPR. Email me at af_hiring@google.com @CordeliaSchmid

Embrace cultural diversity in your large-scale data! 🌎🌍🌏 @angelinepouget’s study shows that (quantitatively) you have no reason not to 🌸

PSA: Stop pretraining your VLMs on EN-filtered data, even if it improves ImageNet and COCO‼️ Doing so impairs the model's understanding of non-English cultures❗️ I argued for years, now finally publish concrete results for this (imo) intuitively obvious recommendation A🧾🧶
PSA: Stop pretraining your VLMs on EN-filtered data, even if it improves ImageNet and COCO‼️ Doing so impairs the model's understanding of non-English cultures❗️ I argued for years, now finally publish concrete results for this (imo) intuitively obvious recommendation A🧾🧶

Want your VLM to reflect the world's rich diversity 🌍? We’re very excited to share our recent research on this topic. TLDR: to build truly inclusive models that work for everyone, don’t filter by English, and check out our recommended evaluation benchmarks. (1/7)


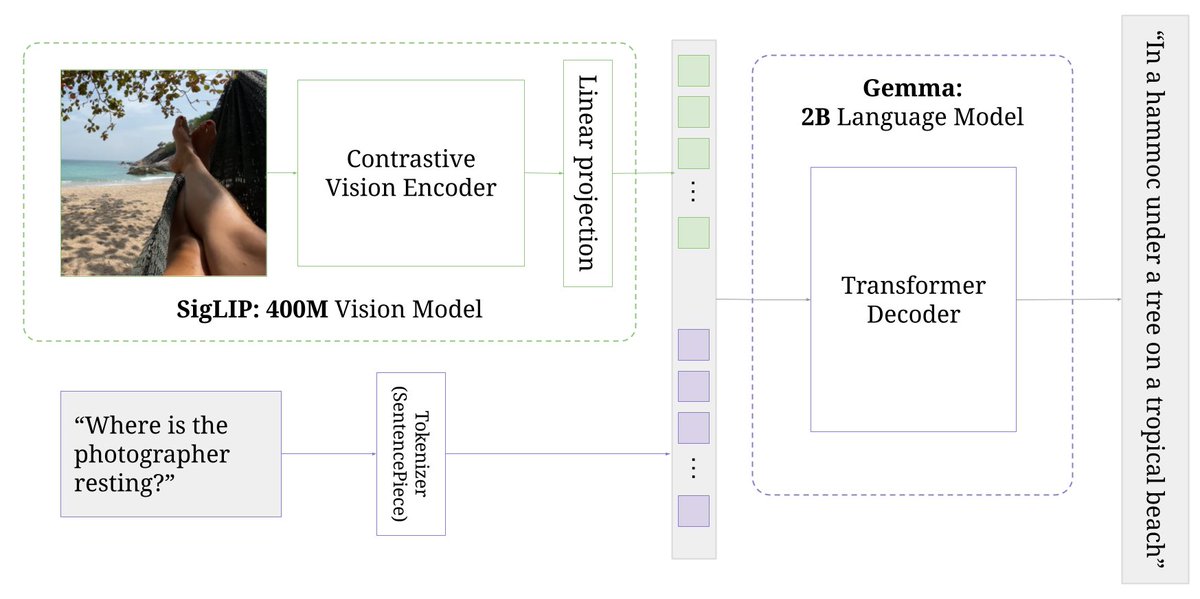
PaliGemma - Open Vision Model from Google! 💎 > 3B parameter model - SigLiP + Gemma 2B > Supports images upto 896 x 896 resolution > Capable of Document understanding, Image detection, visual question answering, captioning and more > In addition to general purpose checkpoints…
And of course, it's multilingual! 🗺️
We release PaliGemma. I'll keep it short, still on vacation: - sota open base VLM designed to transfer quickly, easily, and strongly to a wide range of tasks - Also does detection and segmentation - We provide lots of examples - Meaty tech report later! ai.google.dev/gemma/docs/pal…

About a year ago we put "A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision" on arxiv. We call it "LiT-decoder". It's been rejected (NoT sOtA!!1) but the lessons learned have guided us, and we've use it as a benchmark in many works. A🧶about the lessons


Google presents Revisiting Text-to-Image Evaluation with Gecko On Metrics, Prompts, and Human Ratings While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has

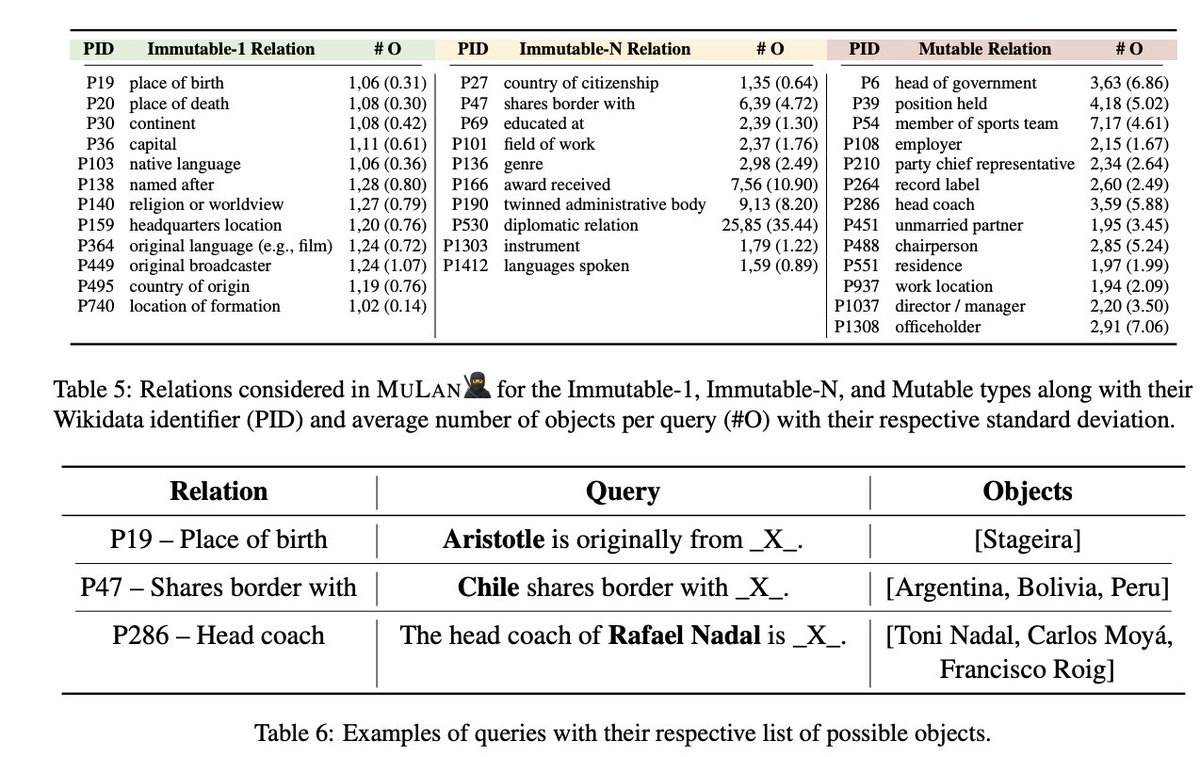
"MULAN 🥷: A Study of Fact Mutability in Language Models" a benchmark to evaluate the ability of English language models to anticipate time-contingency, containing 35 relations extracted from @Wikidata, each with up to 1,500 queries. (Fierro et al, 2024) arxiv.org/pdf/2404.03036…
Are you interested in video generation? Come intern with @laoreja001, @alirezafathi and me @GoogleAI 🇺🇸! 📨 CV + brief intro to: video-gen-internship@google.com 👀 Preferably PhD candidates with papers in computer vision 🗺️ Candidates from underrepresented groups, do apply!

Our team at Google Research is hiring a research intern working on video generation, please email xiuyegu@google.com if you are interested.

Are you a PhD student interested in memorisation, generalisation and the role of data in the era of LLMs? Come do an internship with me at @AIatMeta! metacareers.com/jobs/704140718… (Send me a ping if you apply)

✴ Hiring a Postdoctoral Researcher ✴ I am hiring a postdoc with a background in *vision and language processing*, on a 2/3 year contract. Application deadline: 15 Feb 2024 Start: ASAP Apply here: mbzuai.ac.ae/vacancy/postdo… and contact me here or via email. #NLProc #hiring
Fascinated by video generation? Come check out StoryBench: A benchmark aimed at pushing the capabilities of text-to-video models to generate stories 🎞️ Today, Poster 211 at #NeurIPS2023's 10:45-12:45 session 🎷
Wouldn’t it be cool if AI could help us generate movies?🎬 We built a new benchmark to measure progress in this direction🍿 “StoryBench: A Multifaceted Benchmark for Continuous Story Visualization” 📄 arxiv.org/abs/2308.11606 👩💻 github.com/google/storybe… 📈 paperswithcode.com/dataset/storyb…

Student researcher position applications are open at Google Deepmind! I'm hosting a SR in the intersection of bias and generative models. If you're an interested PhD student please reach out! google.com/about/careers/…






















































































































United States Trends
- 1. Kendrick 55,8 B posts
- 2. #AskShadow 23,3 B posts
- 3. MSNBC 214 B posts
- 4. Drake 87,7 B posts
- 5. Luther 48,6 B posts
- 6. Brandon Allen 2.112 posts
- 7. Wayne 60,1 B posts
- 8. Daniel Jones 47,9 B posts
- 9. Kdot 7.283 posts
- 10. LinkedIn 42,3 B posts
- 11. TV Off 40,9 B posts
- 12. Squabble Up 29,1 B posts
- 13. Dobbs 1.968 posts
- 14. NASA 73 B posts
- 15. Purdy 7.117 posts
- 16. Dodger Blue 15,3 B posts
- 17. Reincarnated 38,2 B posts
- 18. Gloria 48,3 B posts
- 19. Giants 80 B posts
- 20. Jack Antonoff 10,5 B posts
Who to follow
-
 Desmond Elliott
Desmond Elliott
@delliott -
 EdinburghNLP
EdinburghNLP
@EdinburghNLP -
 CopeNLU
CopeNLU
@CopeNLU -
 Roy Schwartz
Roy Schwartz
@royschwartzNLP -
 Yonatan Bisk
Yonatan Bisk
@ybisk -
 Yonatan Belinkov
Yonatan Belinkov
@boknilev -
 Antonis Anastasopoulos @EMNLP
Antonis Anastasopoulos @EMNLP
@anas_ant -
 Edoardo Ponti
Edoardo Ponti
@PontiEdoardo -
 Anna Rogers
Anna Rogers
@annargrs -
 Ivan Vulić
Ivan Vulić
@licwu -
 Sarah Wiegreffe (on faculty job market!)
Sarah Wiegreffe (on faculty job market!)
@sarahwiegreffe -
 Daniel Fried
Daniel Fried
@dan_fried -
 Julia Kreutzer
Julia Kreutzer
@KreutzerJulia -
 Ivan Titov
Ivan Titov
@iatitov -
 Shiyue Zhang
Shiyue Zhang
@byryuer
Something went wrong.
Something went wrong.