
Luke Muehlhauser
@lukeprogOpen Philanthropy Senior Program Officer, AI Governance and Policy
Similar User

@KatjaGrace

@slatestarcodex

@ajeya_cotra

@jkcarlsmith

@KelseyTuoc

@rohinmshah

@michael__aird

@vkrakovna

@AmandaAskell

@robbensinger

@So8res

@EAForumPosts

@OwainEvans_UK

@tobyordoxford

@anderssandberg
AI skeptics: LLMs are copy-paste engines, incapable of original thought, basically worthless. Professionals who track AI progress: We've worked with 60 mathematicians to build a hard test that modern systems get 2% on. Hope this benchmark lasts more than a couple of years.

.@Miles_Brundage has been doing smart work on AI safety policy for more than a decade and is looking for potential co-founders for a new AI strategy/policy org! milesbrundage.substack.com/p/why-im-leavi…
🚨 🚨 🚨 We are looking for someone great to lead a new program focused on accelerating economic growth in developing countries.🚨 🚨 🚨 If we find the right person, they'll oversee at least $30M of spending over the next few years. Here's why we think this is a great bet:
Our Systemic AI Safety Fast Grants scheme is open for applications. In partnership with @UKRI_News, we’re working to advance this new area of research, building the resilience of our society and infrastructure to AI-related hazards. Find out more: aisi.gov.uk/work/advancing…

Great post from @DarioAmodei on many of the huge benefits we could plausibly get from powerful AI if we mitigate the risks successfully! darioamodei.com/machines-of-lo…

At @open_phil, we see a lot of our work as hits-based giving: high-risk, hopefully high-reward, and built on the understanding that a few exceptional successes can offset a lot of failures. After a decade of grantmaking, we’re beginning to see some of our early bets pay off. 🧵
Repurposing generic drugs to treat additional diseases has great potential, but there's no incentive for the private sector to fund that research or clinical trials. We @Arnold_Ventures are thrilled to join other funders to raise $60 mil for Every Cure to advance these efforts.
Great to see this much funding going into frontier AI evaluations work! metr.org/blog/2024-10-0…

Update: we’re hiring for multiple positions! Join GDM to shape the frontier of AI safety, governance, and strategy. Priority areas: forecasting AI, geopolitics and AGI efforts, FSF risk management, agents, global governance. More details below: 🧵

We are hiring! Google DeepMind's Frontier Safety and Governance team is dedicated to mitigating frontier AI risks; we work closely with technical safety, policy, responsibility, security, and GDM leadership. Please encourage great people to apply! 1/ boards.greenhouse.io/deepmind/jobs/…
It's been fun watching papers start to come out of this RFP on benchmarking LLM agents on consequential real world tasks that @ajeya_cotra ran: openphilanthropy.org/rfp-llm-benchm… Bunch of cool ones so far: 🧵

Today, we're excited to announce ForecastBench: a new benchmark for evaluating AI and human forecasting capabilities. Our research indicates that AI remains worse at forecasting than expert forecasters. 🧵 Arxiv: arxiv.org/abs/2409.19839 Website: forecastbench.org
New RFP for LLM-focused AI safety work, application deadline is Nov. 8th! schmidtsciences.org/safe-ai/
Love this call to action -- think it's a very high priority to figure out "if-then" policies that people with widely varying views on the timeline to dangerous capabilities can agree on, and in parallel to develop a rigorous science to assess whether those conditions are met.


Debates over AI Policy like CA SB-1047 highlight fragmentation in the AI community. How can we develop AI policies that help foster innovation while mitigating risks? We propose a path for science- and evidence-based AI policy: understanding-ai-safety.org

Joe Biden tells the UN that we will see more technological change in the next 2-10 years than we have seen in the last 50 and AI will change our ways of life, work and war so urgent efforts are needed on AI safety
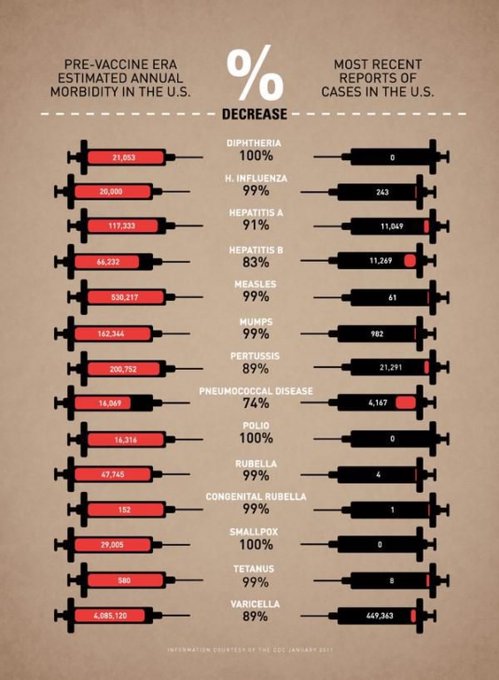
Before vs after the vaccines introduction
An interesting case study in reward hacking. Would like to see what happens with bigger models. Paper: arxiv.org/abs/2409.12822

RLHF is a popular method. It makes your human eval score better and Elo rating 🚀🚀. But really❓Your model might be “cheating” you! 😈😈 We show that LLMs can learn to mislead human evaluators via RLHF. 🧵below

Very exciting news on lead from @PowerUSAID & @albrgr ! washingtonpost.com/opinions/2024/…




















































































































United States Trends
- 1. Tyson 458 B posts
- 2. $MAYO 12,7 B posts
- 3. #wompwomp 4.018 posts
- 4. Pence 54,4 B posts
- 5. Debbie 29,7 B posts
- 6. Kash 92,2 B posts
- 7. Dora 23,7 B posts
- 8. Whoopi 92,5 B posts
- 9. Ronaldo 146 B posts
- 10. Connor Williams 1.076 posts
- 11. The FBI 251 B posts
- 12. Mike Rogers 17,4 B posts
- 13. Iron Mike 19,2 B posts
- 14. #LetsBONK 12,4 B posts
- 15. Gabrielle Union 1.846 posts
- 16. National Energy Council 4.968 posts
- 17. #FursuitFriday 16,7 B posts
- 18. Pepsi 20,9 B posts
- 19. Laken Riley 57,4 B posts
- 20. AFCON 33 B posts
Who to follow
-
 Katja Grace 🔍
Katja Grace 🔍
@KatjaGrace -
 Scott Alexander
Scott Alexander
@slatestarcodex -
 Ajeya Cotra
Ajeya Cotra
@ajeya_cotra -
 Joe Carlsmith
Joe Carlsmith
@jkcarlsmith -
 Kelsey Piper
Kelsey Piper
@KelseyTuoc -
 Rohin Shah
Rohin Shah
@rohinmshah -
 Michael Aird
Michael Aird
@michael__aird -
 Victoria Krakovna
Victoria Krakovna
@vkrakovna -
 Amanda Askell
Amanda Askell
@AmandaAskell -
 Rob Bensinger ⏹️
Rob Bensinger ⏹️
@robbensinger -
 Nate Soares ⏹️
Nate Soares ⏹️
@So8res -
 EA Forum Posts
EA Forum Posts
@EAForumPosts -
 Owain Evans
Owain Evans
@OwainEvans_UK -
 Toby Ord
Toby Ord
@tobyordoxford -
 Anders Sandberg
Anders Sandberg
@anderssandberg
Something went wrong.
Something went wrong.