
Akhil Mathur
@akhilmathursResearch Scientist in Generative AI @MetaAI | ex-@BellLabs
Similar User

@niclane7

@ubicomp

@ACMSIGMOBILE

@earcomp

@tanzeemc

@CaMLSys

@a_montanari

@cecim

@ProfJosiah

@pulkitology

@SougataSen_

@risingodegua

@VedantNeedMoEdu

@tingdang513

@monojitchou
The SIGCHI community is now more inclusive, caring, and global than ever before, thanks to the tireless efforts of @nehakumar and her team. Please vote for them to continue this important work. Voting ends on June 10. acm.org/elections/sigs…

It has been a tremendous honor and a privilege to serve as @sigchi President over the last three years. It took time, energy, commitment, a whole lot of love (and undoubtedly some tears), to pull us out of the pandemic to the point that we are at today. [1/6]



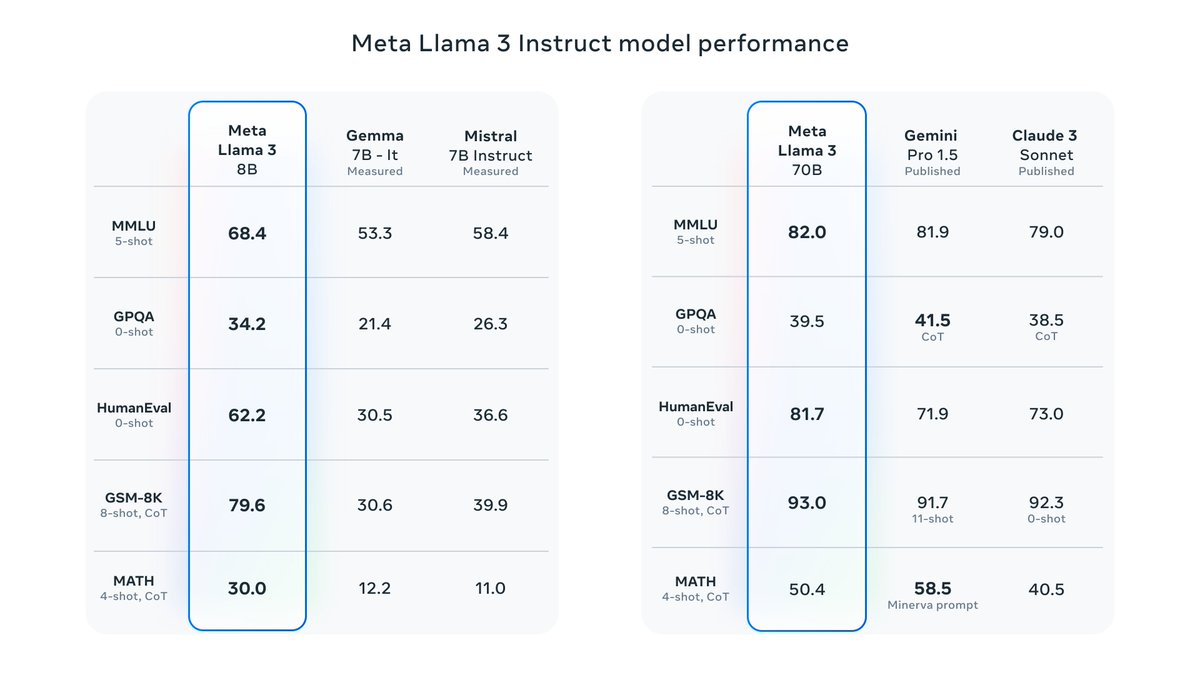
It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs. Key highlights • 8B and 70B parameter openly available pre-trained and fine-tuned models. • Trained on more…
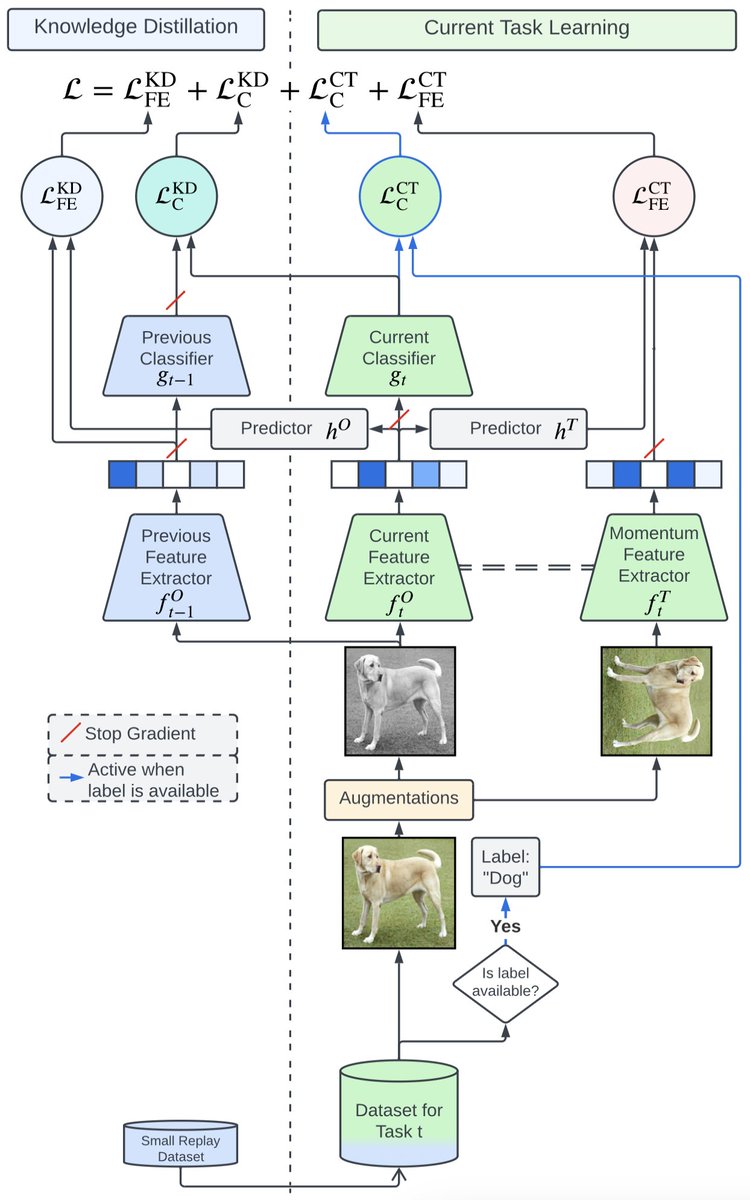
1/5 Tired of self-supervised models that can't adapt to new data? In our #WACV2024 paper, we propose Kaizen - an end-to-end approach for continual learning that performs knowledge distillation across both the pre-training and fine-tuning steps. 👉 arxiv.org/abs/2303.17235
🤿 What is latent masking and why is it relevant to multimodal learning? In our paper in ML4MHD at #ICML2023 we presented CroSSL, a new model that masks intermediate embeddings to improve multimodal learning. 📖 Paper: arxiv.org/abs/2307.16847 🎥 Video: drive.google.com/file/d/1lF5GsQ…

This is huge: Llama-v2 is open source, with a license that authorizes commercial use! This is going to change the landscape of the LLM market. Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face and other providers Pretrained and fine-tuned…
So happy to see this important work published. Model fairness should be a key consideration when we optimize machine learning pipelines for edge devices. Our paper offers a framework to approach on-device ML fairness, along with extensive experimental findings for speech models.

Better late than never. Really proud of this work that I started during an internship @BellLabs and that is finally published in #ACM #TOSEM. doi.org/10.1145/3591867 The paper investigates how design choices during model training & optimization of ondevice ML can lead to bias.
Great progress towards efficient and adaptive FL on ultra-constrained devices. Work led by @VincentMo6 during his internship at @BellLabs

Federated Learning for constrained edge devices need to become more efficient and adaptive. In this preprint, we offer Centaur: a framework that adaptively partitions FL training across multiple clients owned by each user. PDF: arxiv.org/abs/2211.04175 1/4

🥁🥁 Join us for ACM SIGCHI Symposium for 𝐇𝐂𝐈 𝐚𝐧𝐝 𝐅𝐫𝐢𝐞𝐧𝐝𝐬 at IIT Bombay, India, 9-11 December 2022!🧵 Speakers: namastehci.in/#speakers November 9th: Applications due namastehci.in/#registration 🙏 Anupriya, @akhilmathurs, Anirudha Joshi, @Pushpendra_S__, @nehakumar

All train services between London and Cambridge are delayed because there is a swan 🦢 sitting on the track 🤷🏻♂️🤦♂️
Charlie Dean was outside the crease for more than 85% of all balls she started at the non-striker's end. "Spirit of cricket!" 🙄

Went back to the full match replay. Charlie Dean was leaving her crease early starting with her 2nd ball at the non-striker's end in the 18th over. Ball still in bowler's hand. Dean is never looking at the bowler to see if/when the ball has been released. Basic lack of awareness.

Shohreh Deldari (@ShohrehDeldari) from RMIT is now presenting her super cool work on cross modal self supervised learning. #UbiComp2022

Hyunsung Cho (@hciresearcher) is presenting her work FLAME 🔥 which shows how to make federated learning work in multi-device environments #UbiComp2022

Brilliant talk today by @IanTangC on our collaborative self-supervised work aimed at making HAR training data-efficient. #UbiComp2022 @ubicomp

In our upcoming paper at #IMWUT @ubicomp, we present ColloSSL: a technique for collaborative self-supervised learning among a group of devices. 🧵 (1/n) arxiv.org/abs/2202.00758

"At the stroke of the midnight hour, when the world sleeps, India will awake to life and freedom. Happy 75th Independence Day! The journey has just begun #IndiaAt75
Looking forward to presenting our work and learning more about ML efficiency @ Deep Learning Indaba. Kudos to the incredible organizing team for putting this event together.

The exciting part is the incredible in-person talks and lineups we have planned in Tunis. Including: - @KateKallot, Head of emerging areas at NVIDIA - @akhilmathurs, Principal Research Scientist at Bell Labs - @zngu, Associate Professor, University of Edinburgh

If you are attending #ICML2022, please join our spotlight talk on self-supervised FL on July 19 and poster presentation on July 21. Please feel free to DM if you are up for a chat on FL, self-supervision, and embedded ML. icml.cc/virtual/2022/s…
Glad to share that our work FLAME has been accepted to IMWUT '22. We explore algorithmic & system challenges for federated learning in the presence of multiple data-generating devices on a user. Proud of our intern @hciresearcher who led this work. arxiv.org/abs/2202.08922 @raswak

An excellent summary of our upcoming ICML paper on unsupervised FL. The paper is out on arXiv arxiv.org/abs/2205.11506. Also, a big thank you to the Flower framework flower.dev which helped us scale our FL experiments.

Hello, world! We present to you 🎶Orchestra🎶, an unsupervised framework for federated learning! The paper was recently accepted at #ICML. Abs: arxiv.org/abs/2205.11506
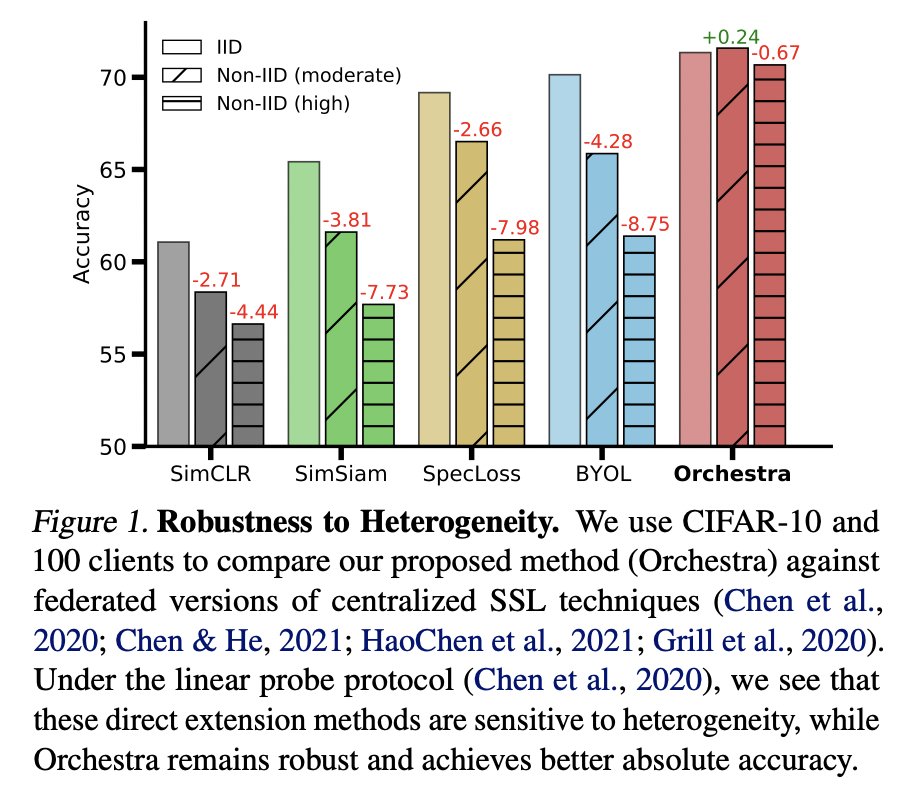

Very happy to share that our work on self-supervised federated learning in resource-constrained settings has been accepted at #ICML 2022. A fantastic outcome for the internship work by @EkdeepL in collaboration with @IanTangC @raswak Arxiv link and more details are coming soon.
We have met some terrific talents lately and we want to meet more. Shout out to lateral thinkers and bright engineers to join a talented, fearless and relentless team @BellLabs Cambridge to do career-defining work on devices that matter. Researchers & engineers, tell us why you?











































































































United States Trends
- 1. Mike 1,84 Mn posts
- 2. Serrano 239 B posts
- 3. #NetflixFight 72,1 B posts
- 4. Canelo 16,5 B posts
- 5. Father Time 10,7 B posts
- 6. #netflixcrash 15,8 B posts
- 7. Logan 78,6 B posts
- 8. He's 58 25,7 B posts
- 9. Rosie Perez 14,9 B posts
- 10. ROBBED 101 B posts
- 11. Boxing 299 B posts
- 12. #buffering 10,9 B posts
- 13. Shaq 16,1 B posts
- 14. My Netflix 83,1 B posts
- 15. Roy Jones 7.168 posts
- 16. Tori Kelly 5.240 posts
- 17. Cedric 21,9 B posts
- 18. Ramos 69,8 B posts
- 19. Barrios 50,5 B posts
- 20. Muhammad Ali 18,3 B posts
Who to follow
-
 nic lane
nic lane
@niclane7 -
 UbiComp
UbiComp
@ubicomp -
 ACM SIGMOBILE
ACM SIGMOBILE
@ACMSIGMOBILE -
 EarComp 2024
EarComp 2024
@earcomp -
 tanzeem
tanzeem
@tanzeemc -
 Cambridge ML Systems Lab
Cambridge ML Systems Lab
@CaMLSys -
 Alessandro Montanari
Alessandro Montanari
@a_montanari -
 Cecilia Mascolo🇪🇺🇬🇧
Cecilia Mascolo🇪🇺🇬🇧
@cecim -
 Josiah Hester
Josiah Hester
@ProfJosiah -
 Pulkit Agrawal
Pulkit Agrawal
@pulkitology -
 Sougata Sen
Sougata Sen
@SougataSen_ -
 RO2⚡️
RO2⚡️
@risingodegua -
 Vedant (on the Job Market!) Das Swain
Vedant (on the Job Market!) Das Swain
@VedantNeedMoEdu -
 Ting Dang
Ting Dang
@tingdang513 -
 Monojit Choudhury
Monojit Choudhury
@monojitchou
Something went wrong.
Something went wrong.