
Zefan Cai @ EMNLP 2024
@Zefan_CaiNow Ph.D student @UWMadison Previous @PKU1898
Similar User

@Baris19051974

@Red0541927155

@farzy04506692

@BlaineF74

@oscarcuanto

@astoldbyphoebe

@jorgegarciacam

@BigBleuOx

New Anthropic research: Adding Error Bars to Evals. AI model evaluations don’t usually include statistics or uncertainty. We think they should. Read the blog post here: anthropic.com/research/stati…


Excited to present my paper on role-playing LLM agents at #EMNLP2024! 🎉 Paper Title: “Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks” Come say hi and let's chat about some exciting research! 🤖🧠✨ TL;DR: How can we make LLM agents…


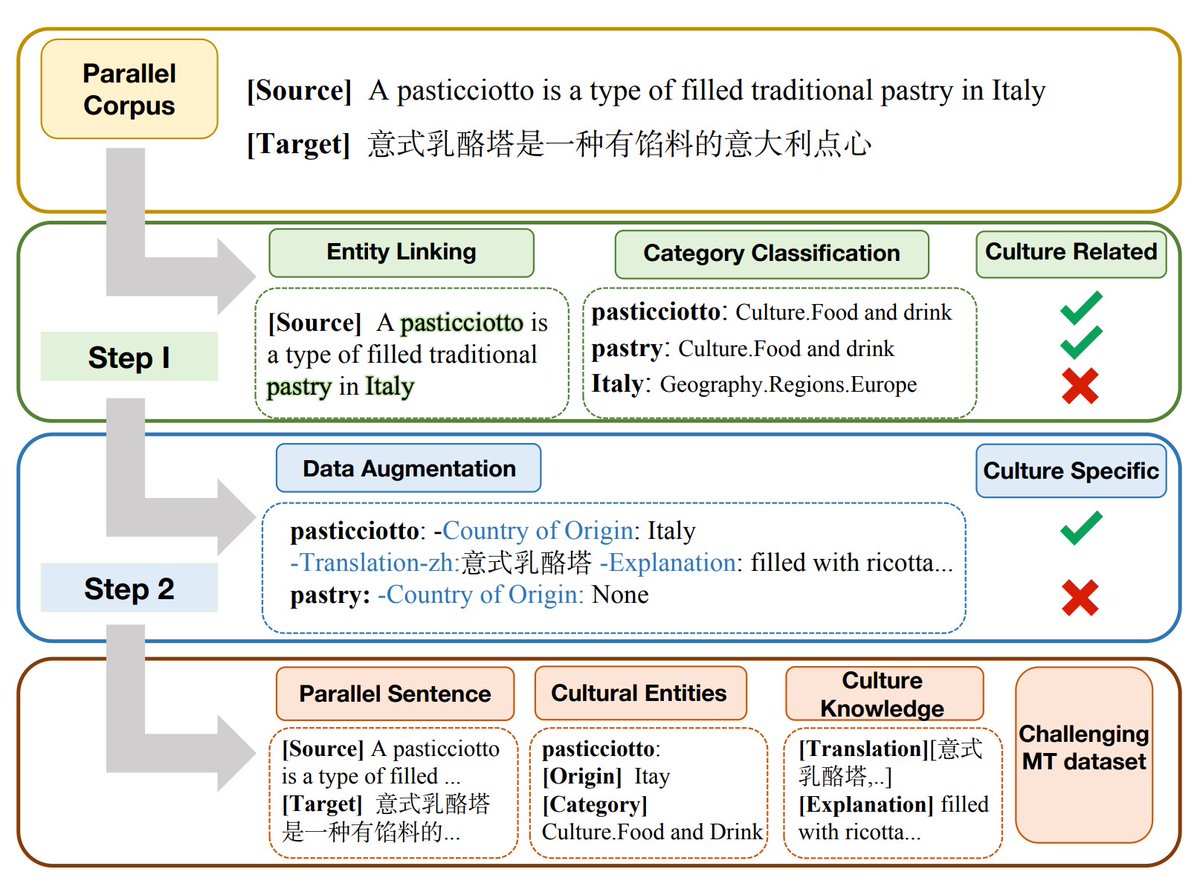
We are excited to share our latest work on benchmarking current LLM-based machine translation and traditional NMT on culture-specific concepts. Chat with us at 4-5:30pm on the poster session #EMNLP2024! Joint work w/ @Binnie8545 @SeleenaJiang @Diyi_Yang

🚀 Excited to present our paper "Benchmarking Machine Translation with Cultural Awareness" at #EMNLP2024! We build CAMT, a novel parallel corpus enriched with culture-specific item annotations, and evaluate how well NMT and LLM-MT systems handle cultural entities.
Arriving in #Miami for #EMNLP2024! Excited to see friends! Would like to chat about inference acceleratoon —feel free to reach out!

About to arrive in #Miami 🌴 after a 30-hour flight for #EMNLP2024! Excited to see new and old friends :) I’d love to chat about data synthesis and deep reasoning for LLMs (or anything else) —feel free to reach out!

🌐 Are LLM agents prepared to navigate the rich diversity of cultural and social norms? 🏠 CASA tests them on real-world tasks like online shopping and social discussion forums, revealing that current agents show less than 10% awareness and over 40% norm violations. 🧠 We’re…

Thanks for sharing! Our new work HeadKV intelligently compresses LLM memory by identifying and prioritizing crucial attention heads. Specifically, this is the first work that targets at global memory allocation aross 32 heads in 32 layers inside Llama-3 model.

Not all brain cells are equal - same goes for LLM attention heads! 💡 Why store everything when you can just remember the important stuff? Smart KV cache compression that knows which attention heads matter most. Hence, HeadKV intelligently compresses LLM memory by identifying…


@OpenAI @junshernchan @ChowdhuryNeil Thank you for your work on MLE-bench. I wanted to bring to your attention our highly relevant work in 2023: "ML-BENCH: Evaluating Large Language Models and Agents for Machine Learning Tasks" (arxiv.org/abs/2311.09835). We'd appreciate…

We’re releasing a new benchmark, MLE-bench, to measure how well AI agents perform at machine learning engineering. The benchmark consists of 75 machine learning engineering-related competitions sourced from Kaggle. openai.com/index/mle-benc…

Progress in this field is truly rapid!

🔥 MovieChat recently received its 100th citation. Thank you all for your support! A year after its release, we’ve updated MovieChat in CVPR 2024, the first large multimodal model designed for long video understanding. Thanks to its training-free design, we’ve upgraded the…


🌍 I’ve always had a dream of making AI accessible to everyone, regardless of location or language. However, current open MLLMs often respond in English, even to non-English queries! 🚀 Introducing Pangea: A Fully Open Multilingual Multimodal LLM supporting 39 languages! 🌐✨…

Looking forward to see how Lex react to Anthropic

I'm doing a podcast with Dario Amodei, CEO of Anthropic (creator of Claude) soon, all about AI. Let me know if you have questions/topic suggestions. Also, I'll stop by SF for a bit. Let me know if you have suggestions of who I should talk to.
Thanks for sharing!

6/ **Large Language Models are not Fair Evaluators** Want to use LLMs as evaluators? There are many things to be aware of, one of them is positional bias! This paper not only shows that but also develops simple yet effective calibration mechanisms to align LLM judgments more…

(Perhaps a bit late) Excited to announce our survey on ICL has been accepted to #EMNLP2024 main conf and been cited 1,000+ times! Thanks to all collaborators and contributors to this field! We've updated the survey arxiv.org/abs/2301.00234. Excited to keep pushing boundaries!
Our previous work ML-Bench also evaluates how well agents perform ML developments! Super excited that this high-quality dataset is released to help develop code agents! ARXIV: arxiv.org/abs/2311.09835 Code: github.com/gersteinlab/ML…
We’re releasing a new benchmark, MLE-bench, to measure how well AI agents perform at machine learning engineering. The benchmark consists of 75 machine learning engineering-related competitions sourced from Kaggle. openai.com/index/mle-benc…

How can we guide LLMs to continually expand their own capabilities with limited annotation? SynPO: a self-boosting paradigm training LLM to auto-learn generative rewards and synthesize preference data. After 4 iterations, Llama3&Mistral achieve over 22.1% win rate improvements



🤔How much potential do LLMs have for self-acceleration through layer sparsity? 🚀 🚨 Excited to share our latest work: SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration. Arxiv: arxiv.org/abs/2410.06916 🧵1/n


Need to address my earlier tweet: the #ACL2025 deadline has now been updated to February 15. Be sure to check out the updated CFP for all the details at 2025.aclweb.org/calls/main_con…. Thank you for your understanding as we navigate these changes! 📝✨
Do you still think VQ can not do text reconstruction? DND-Transformer can definitely change your mind! We empirically prove that Auto-Regressive Transformers can generate images with rich text and graphical elements.

✨A Spark of Vision-Language Intelligence! We introduce DnD-Transformer, a new auto-regressive image gen model beats GPT/Llama w/o extra cost. AR gen beats diffusion in joint VL modeling in a self-supervised way! Github: github.com/chenllliang/Dn… Paper: huggingface.co/papers/2410.01…






































































United States Trends
- 1. Thanksgiving 497 B posts
- 2. #Overwatch2Sweepstakes 1.515 posts
- 3. #iubb 1.757 posts
- 4. $CUTO 7.627 posts
- 5. Custom 72,8 B posts
- 6. Woodson 1.369 posts
- 7. Louisville 5.111 posts
- 8. Vindman 4.695 posts
- 9. UNTITLED UNMASTERED 1.446 posts
- 10. Darnold 4.628 posts
- 11. Deleted 55,1 B posts
- 12. The IRS 40,5 B posts
- 13. Drew Lock 1.334 posts
- 14. Standard Time 8.801 posts
- 15. Dodgers 69,6 B posts
- 16. Section 80 2.770 posts
- 17. CFPB 4.241 posts
- 18. Nissan 9.743 posts
- 19. Daylight Savings Time 1.814 posts
- 20. Happy Birthday Steve 1.502 posts








Something went wrong.
Something went wrong.