
Seonghyeon Ye
@SeonghyeonYePhD student KAIST AI (@kaist_ai) & Research intern at Microsoft Research
Similar User

@jefffhj

@dongkeun_yoon

@jang_yoel

@seo_minjoon

@jinheonbaek

@soheeyang_

@_dongkwan_kim

@SungdongKim4

@hoyeon_chang

@hyeonmin_Lona

@GrantSlatton

@raymin0223

@hyunji_amy_lee

@jshin491

@jaeh0ng_yoon
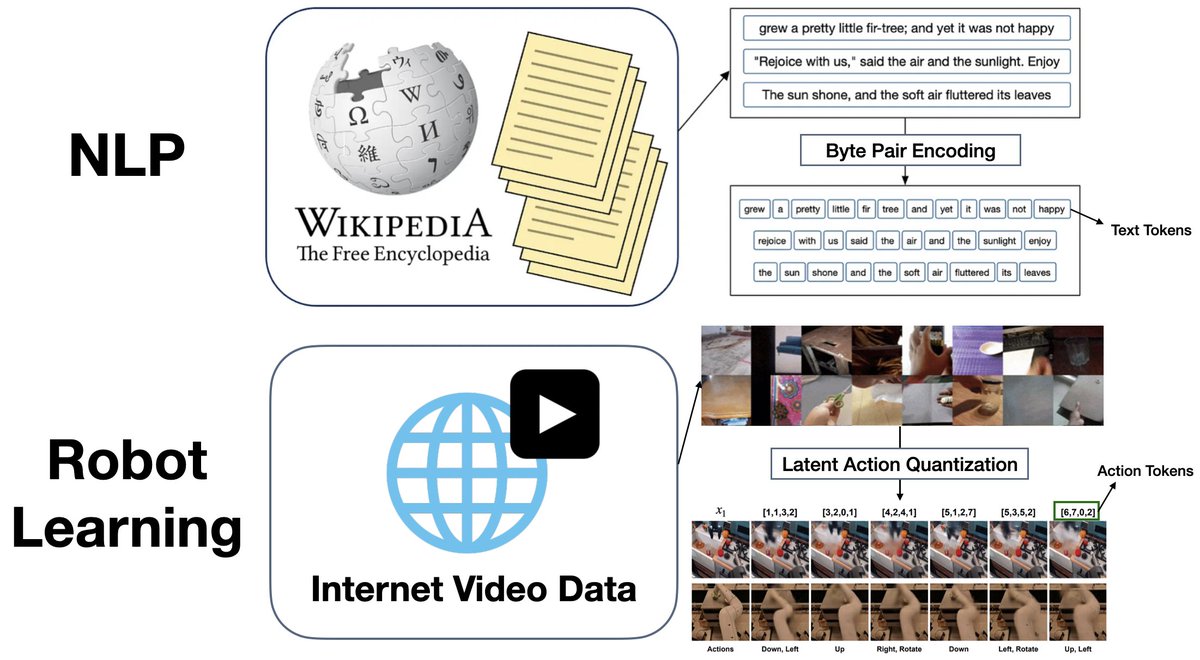
🚀 First step to unlocking Generalist Robots! Introducing 🤖LAPA🤖, a new SOTA open-sourced 7B VLA pretrained without using action labels. 💪SOTA VLA trained with Open X (outperforming OpenVLA on cross and multi embodiment) 😯LAPA enables learning from human videos, unlocking…
We won the 🏆Best Paper Award at #Corl2024 LangRob workshop! Also check out our updated codebase: github.com/LatentActionPr…
Excited to share that 𝐋𝐀𝐏𝐀 has won the Best Paper Award at the CoRL 2024 Language and Robot Learning workshop, selected among 75 accepted papers! Both @SeonghyeonYe and I come from NLP backgrounds, where everything is built around tokenization. Drawing inspiration from…

Really excited to share what I've been working on with my colleagues at Physical Intelligence! We've developed a prototype robotic foundation model that can fold laundry, assemble a box, bus a table, and many other things. We've written a paper and blog post about it. 🧵👇
D4RL is a great benchmark, but is saturated. Introducing OGBench, a new benchmark for offline goal-conditioned RL and offline RL! Tasks include HumanoidMaze, Puzzle, Drawing, and more 🙂 Project page: seohong.me/projects/ogben… GitHub: github.com/seohongpark/og… 🧵↓
Mobile AI assistants (like Apple Intelligence) offer useful features using personal information. But how can we ensure they’re safe to use? Introducing MobileSafetyBench—a benchmark to assess the safety of mobile AI assistants. PDF & Code: mobilesafetybench.github.io 1/N 🧵
Tired of endlessly teleoperating your robot in order to train it? Introducing SkillMimicGen, a data generation system that automatically scales robot imitation learning by synthesizing demos through integrating motion planning and demo adaptation. skillgen.github.io 1/
Excited to introduce 𝐋𝐀𝐏𝐀: the first unsupervised pretraining method for Vision-Language-Action models. Outperforms SOTA models trained with ground-truth actions 30x more efficient than conventional VLA pretraining 📝: arxiv.org/abs/2410.11758 🧵 1/9
LAPA: Latent Action Pretraining from Videos - Proposes a method to learn from internet-scale videos w/o action labels - Outperforms the SotA VLA model trained with robotic action labels on real-world manipulation tasks proj: latentactionpretraining.github.io abs: arxiv.org/abs/2410.11758
❓Do LLMs maintain the capability of knowledge acquisition throughout pretraining? If not, what is driving force behind it? ❗Our findings reveal that decreasing knowledge entropy hinders knowledge acquisition and retention as pretraining progresses. 📄arxiv.org/abs/2410.01380

I wrote a little blog post about robotic foundation models (generalist robotic policies): sergeylevine.substack.com/p/the-promise-…
Meet Molmo: a family of open, state-of-the-art multimodal AI models. Our best model outperforms proprietary systems, using 1000x less data. Molmo doesn't just understand multimodal data—it acts on it, enabling rich interactions in both the physical and virtual worlds. Try it…
Evaluation in robot learning papers, or, please stop using only success rate a paper and a 🧵 arxiv.org/abs/2409.09491
Humans learn and improve from failures. Similarly, foundation models adapt based on human feedback. Can we leverage this failure understanding to enhance robotics systems that use foundation models? Introducing AHA—a vision-language model for detecting and reasoning over…































































































United States Trends
- 1. $CUTO 8.107 posts
- 2. Northwestern 4.914 posts
- 3. Sheppard 2.608 posts
- 4. Denzel Burke N/A
- 5. #collegegameday 4.441 posts
- 6. Jeremiah Smith N/A
- 7. $CATEX N/A
- 8. DeFi 108 B posts
- 9. Broden N/A
- 10. Jim Knowles N/A
- 11. Jahdae Barron N/A
- 12. #Caturday 8.841 posts
- 13. #Buckeyes N/A
- 14. Ewers N/A
- 15. #SkoBuffs 2.556 posts
- 16. #HookEm 2.163 posts
- 17. Renji 5.564 posts
- 18. Wrigley 2.833 posts
- 19. $XDC 1.626 posts
- 20. Jayce 99,6 B posts
Who to follow
-
 Jie Huang
Jie Huang
@jefffhj -
 Dongkeun Yoon
Dongkeun Yoon
@dongkeun_yoon -
 Joel Jang
Joel Jang
@jang_yoel -
 Minjoon Seo
Minjoon Seo
@seo_minjoon -
 Jinheon Baek
Jinheon Baek
@jinheonbaek -
 Sohee Yang @ ACL 2024
Sohee Yang @ ACL 2024
@soheeyang_ -
 Dongkwan Kim
Dongkwan Kim
@_dongkwan_kim -
 Sungdong Kim
Sungdong Kim
@SungdongKim4 -
 Hoyeon Chang
Hoyeon Chang
@hoyeon_chang -
 Hyeon min Yun
Hyeon min Yun
@hyeonmin_Lona -
 Grant Slatton
Grant Slatton
@GrantSlatton -
 Sangmin Bae
Sangmin Bae
@raymin0223 -
 hyunji amy lee
hyunji amy lee
@hyunji_amy_lee -
 Jay Shin
Jay Shin
@jshin491 -
 Jaehong Yoon
Jaehong Yoon
@jaeh0ng_yoon
Something went wrong.
Something went wrong.