
Negin Raoof
@NeginRaoof_Ph.D. student @UTAustin advised by @AlexGDimakis. Ex: SWE @microsoft, collaborator @PyTorch
Similar User

@VITAGroupUT

@xue_yihao65785

@YatingWu96

@_sdbuchanan

@romy_luo

@JalalAjil

@sam_hrvth

@kalina_slavkova

@HaoningTimothy

@AGerstlauer

@AlliotNagle

@MMondelli

@zhangjiyang6

@ajayjaiswal1994

@Douglas74706081

Are you using ESM2 for your sequence embeddings? Try out ISM, a one-line code change that will incorporate improved structure and sequence information, without a structure as input. (1/7)


How much is a noisy image worth? 👀 We show that as long as a small set of high-quality images is available, noisy samples become extremely valuable, almost as valuable as clean ones. Buckle up for a thread about dataset design and the value of data 💰


Wow, I just realized that our Datacomp datasets have 800k downloads last month on HF! Excited to see this project come so far. (if you don't know it already, Datacomp is the largest public multimodal dataset of images and captions).


💥 LLAMA Models: 1B IS THE NEW 8B 💥 📢 Thrilled to open-source LLAMA-1B and LLAMA-3B models today. Trained on up to 9T tokens, we break many new benchmarks with the new-family of LLAMA models. Jumping right from my PhD at Berkeley, to train these models at @AIatMeta has been an…
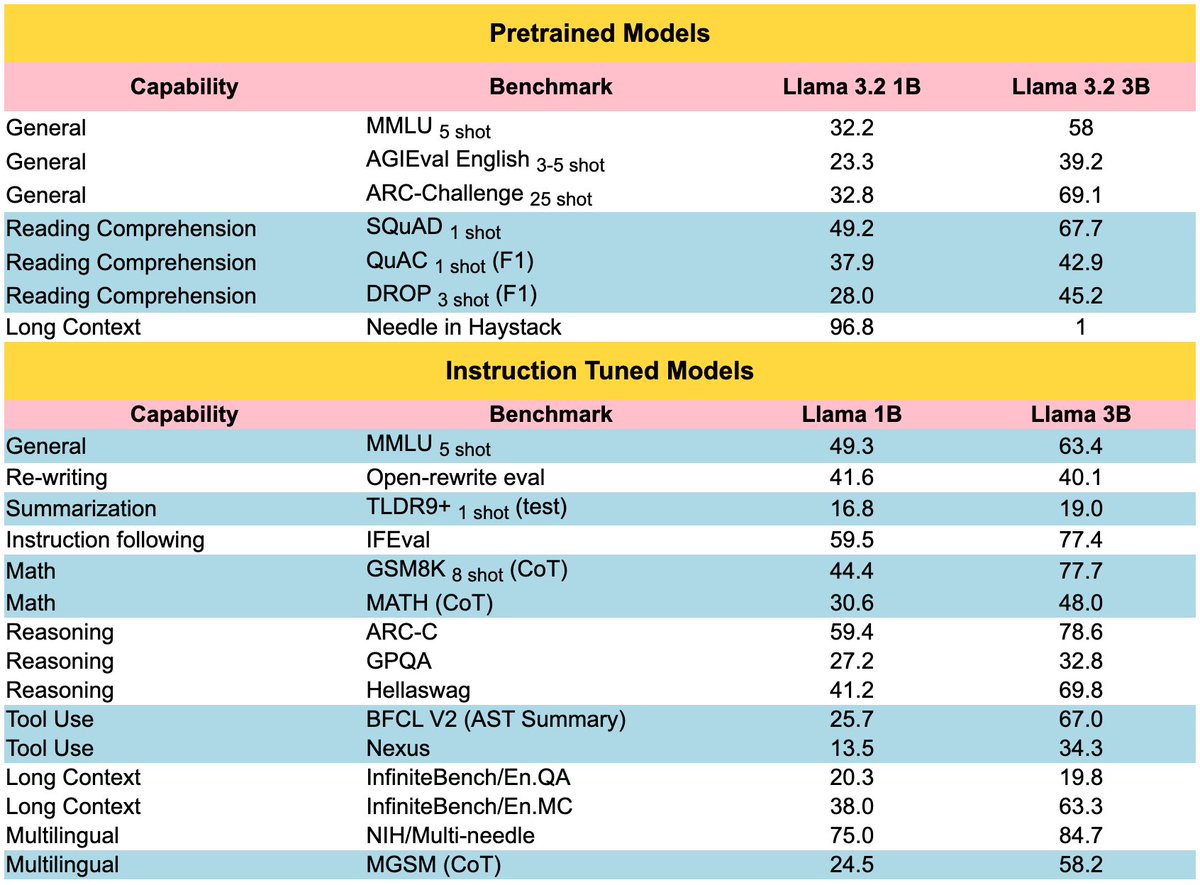
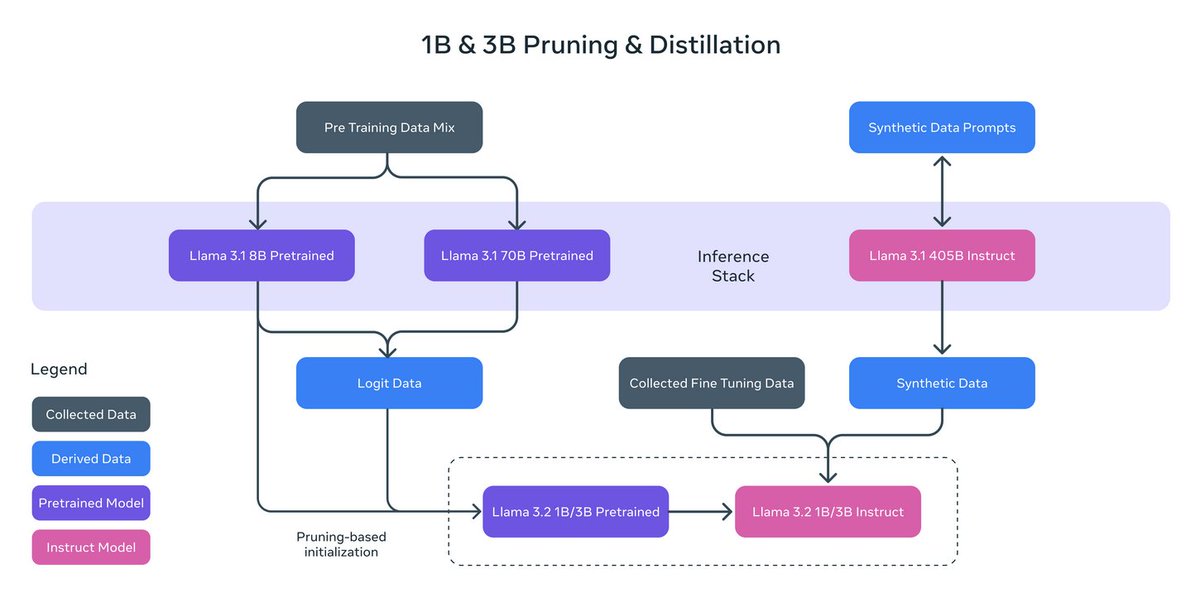
Such a nice pipeline for eval data curation
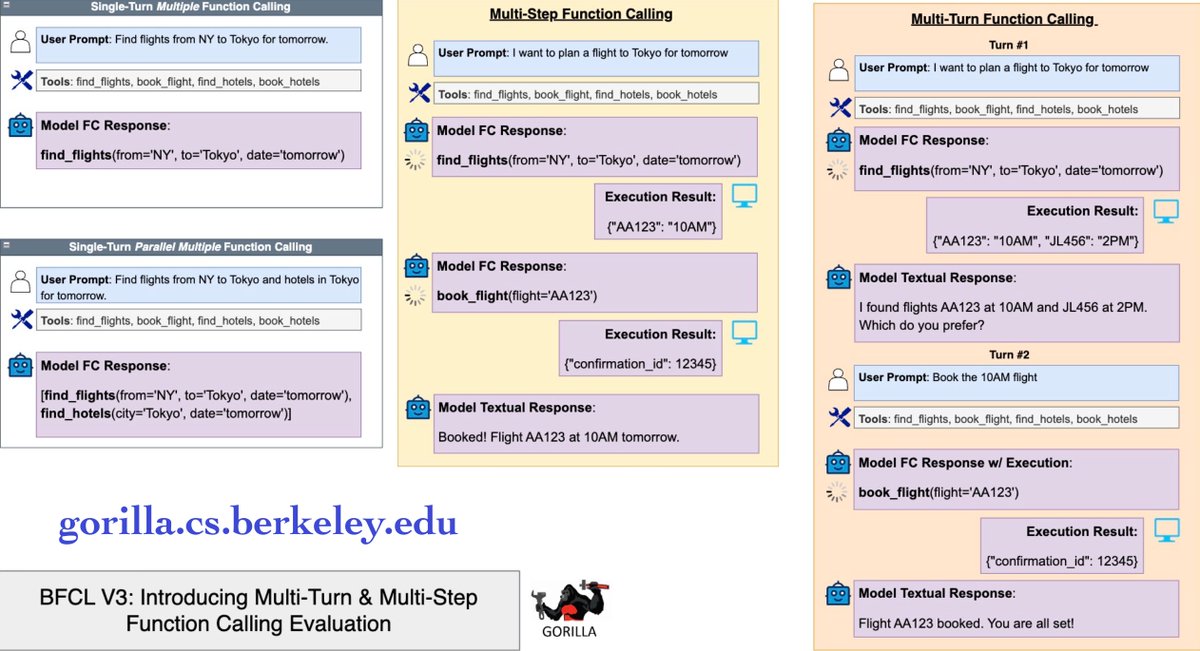
📣 Announcing BFCL V3 - evaluating how LLMs handle multi-turn, and multi-step function calling! 🚀 For agentic systems, function calling is critical, but a model needs to do more than single-turn tasks. Can it manage multi-turn workflows, handle sequential functions, and adapt to…

Super excited that Ollama has launched our model on their main library, right next to the Llamas and Gemmas. ollama.com/library/bespok… ollama.com/blog/reduce-ha…

ollama run bespoke-minicheck .@bespokelabsai released Bespoke-Minicheck, a 7B fact-checking model is now available in Ollama! It answers with Yes / No and you can use it to fact check claims on your own documents. How to use the model with examples: ollama.com/blog/reduce-ha…
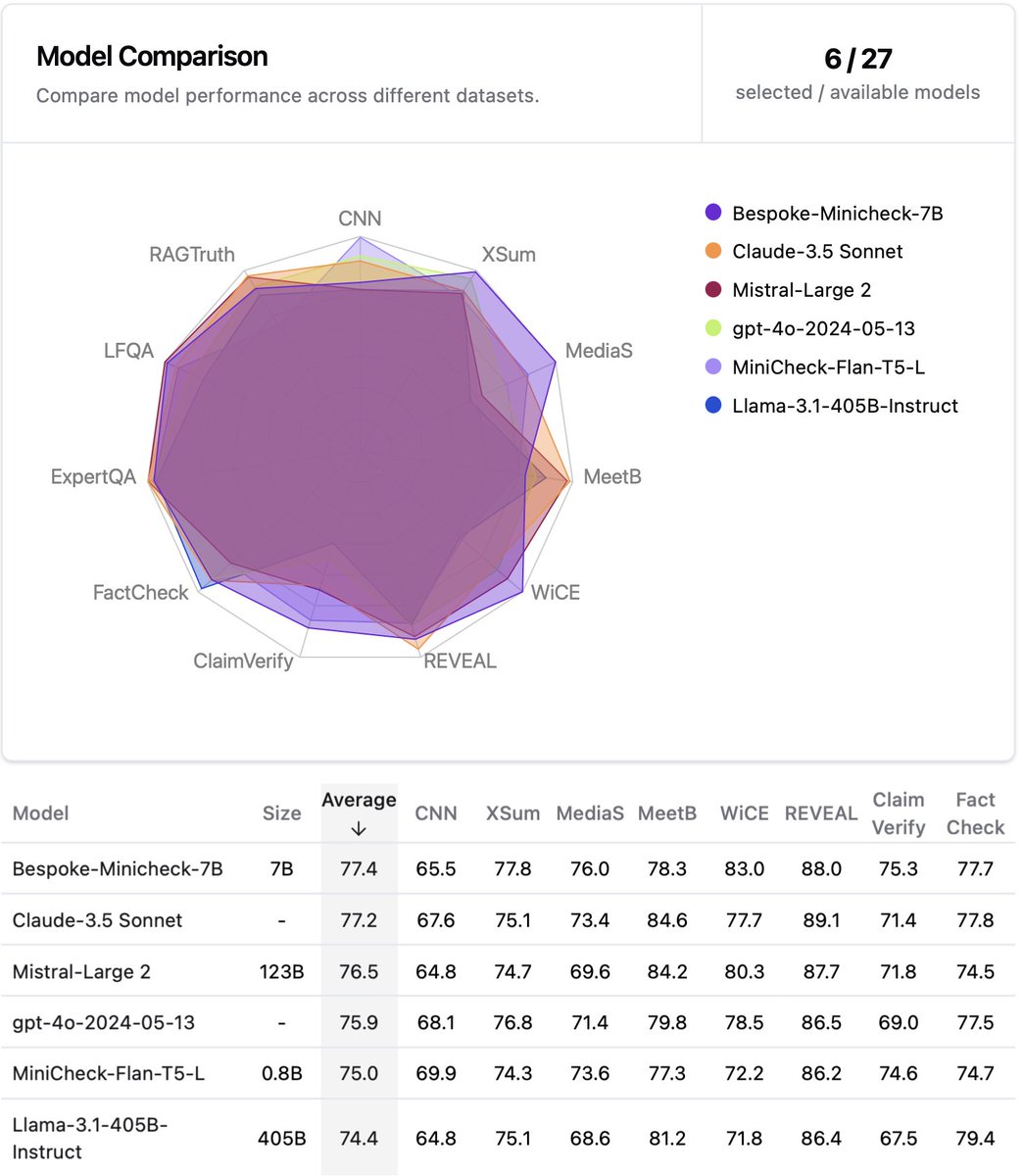

GPT-o1-preview is better than GPT-4o on grounded factuality checking (78.5 raised to 79.7 on WiCE). But more expensive and slow. Gladly, our 7B model Bespoke-minicheck gets 83 on this benchmark. playground.bespokelabs.ai


Automating AI research is exciting! But can LLMs actually produce novel, expert-level research ideas? After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.


closing out the week with a very special announcement we're thrilled to launch @bespokelabsai's SOTA Hallucination detection model Minicheck-7B on Guardrails Hub there's a lot of noise about hallucinations, but Bespoke comes with receipts (i.e. benchmarks)


Excited to announce an addition to the Guardrails Hub through a collaboration with @bespokelabsai! Bespoke’s minicheck is fantastic at detecting hallucinations by identifying sentences in LLM outputs that are not supported by a given context. Use it today by running…

🔗 Thoughts on Research Impact in AI. Grad students often ask: how do I do research that makes a difference in the current, crowded AI space? This is a blogpost that summarizes my perspective in six guidelines for making research impact via open-source artifacts. Link below.


Check out the blog post by @bespokelabsai understanding the nuances between hallucination and grounded factuality, and Bespoke-MiniCheck model can efficiently help improve RAG systems by preventing hallucinations.
One of the big problems in AI is that the systems often hallucinate. What does that mean exactly and how do we mitigate this problem, especially for RAG systems? 1. Hallucinations and Factuality Factuality refers to the quality of being based on generally accepted facts. For…


Does style matter over substance in Arena? Can models "game" human preference through lengthy and well-formatted responses? Today, we're launching style control in our regression model for Chatbot Arena — our first step in separating the impact of style from substance in…

Excited to launch the first model from our startup: Bespoke Labs. Bespoke-Minicheck-7B is a grounded factuality checker: super lightweight and fast. Outperforms all big foundation models including Claude 3.5 Sonnet, Mistral-Large m2 and GPT 4o and its only 7B. Also, I want to…

🤔 Want to know if your LLMs are factual? You need LLM fact-checkers. 📣 Announcing the LLM-AggreFact leaderboard to rank LLM fact-checkers. 📣 Want the best model? Check out @bespokelabsai’s’ Bespoke-Minicheck-7B model, which is the current SOTA fact-checker and is cheap and…



Excited to offer a sneak peek at what we have been working on. Check out the LLM-AggreFact leaderboard [1] for factuality and hallucination detection, and the demo of our model that tops the leaderboard [2]. [1] llm-aggrefact.github.io [2] playground.bespokelabs.ai More info to…
🤔 Want to know if your LLMs are factual? You need LLM fact-checkers. 📣 Announcing the LLM-AggreFact leaderboard to rank LLM fact-checkers. 📣 Want the best model? Check out @bespokelabsai’s’ Bespoke-Minicheck-7B model, which is the current SOTA fact-checker and is cheap and…

Why does deep learning work? How do scientific experiments shed light on the inner workings of deep nets? Come to our workshop at #NeurIPS2024 if you’re interested in these questions and consider sending your work or participate in the challenge!

📢Excited to announce the Workshop on Scientific Methods for Understanding Deep Learning #NeurIPS2024 🥳 ➡️Submission Deadline: Sep 10 ‘24 ➡️Speaker lineup: scienceofdlworkshop.github.io ➡️Call for paper: scienceofdlworkshop.github.io/submissions/ ➡️Our ✨Debunking ✨ challenge: scienceofdlworkshop.github.io/challenge/


thank you authors, reviewers and speakers for your contributions to a great DMLR @icmlconf presentations by @AdtRaghunathan @BlancheMinerva @giffmana @AlexGDimakis @nomic_ai @MGerstgrasser @angelinepouget at icml.cc/virtual/2024/w… join & contribute at discord.com/invite/FswYXMv…


We received a lot of interest in #textgrad, so we wrote a blog explaining how it works + how to use it to solve cool problems like optimizing code and finding new drug-like molecules👇. All w/ a few lines of code! hai.stanford.edu/news/textgrad-… Try it out github.com/zou-group/text…
































































United States Trends
- 1. Brian Kelly 7.946 posts
- 2. #UFC309 4.115 posts
- 3. Mizzou 6.029 posts
- 4. Feds 2.228 posts
- 5. Louisville 6.501 posts
- 6. Gators 10,6 B posts
- 7. Nebraska 11,2 B posts
- 8. Luther Burden 1.181 posts
- 9. Stanford 8.953 posts
- 10. #MissUniverse 40,3 B posts
- 11. Nuss 3.307 posts
- 12. Antifa 31,3 B posts
- 13. Arian Smith N/A
- 14. Brohm N/A
- 15. Herb Dean N/A
- 16. Locke 3.578 posts
- 17. Napier 5.474 posts
- 18. #AEWCollision 5.536 posts
- 19. #MostRequestedLive 11,4 B posts
- 20. Lagway N/A
Who to follow
-
 VITA Group
VITA Group
@VITAGroupUT -
 Yihao Xue
Yihao Xue
@xue_yihao65785 -
 Yating Wu
Yating Wu
@YatingWu96 -
 Sam Buchanan
Sam Buchanan
@_sdbuchanan -
 Romy Mi Luo
Romy Mi Luo
@romy_luo -
 Ajil Jalal
Ajil Jalal
@JalalAjil -
 Samuel Horváth
Samuel Horváth
@sam_hrvth -
 Kalina P. Slavkova
Kalina P. Slavkova
@kalina_slavkova -
 Haoning Wu
Haoning Wu
@HaoningTimothy -
 Andreas Gerstlauer
Andreas Gerstlauer
@AGerstlauer -
 AlliotNagle
AlliotNagle
@AlliotNagle -
 Marco Mondelli
Marco Mondelli
@MMondelli -
 Jiyang Zhang
Jiyang Zhang
@zhangjiyang6 -
 Ajay Jaiswal
Ajay Jaiswal
@ajayjaiswal1994 -
 douglasX
douglasX
@Douglas74706081
Something went wrong.
Something went wrong.