
Similar User

@janundnik

@barret_zoph

@m__dehghani

@XiaohuaZhai

@noahdgoodman

@DaniYogatama

@PreetumNakkiran

@vansteenkiste_s

@OlivierBachem

@liuzhuang1234

@KL_Div

@SadhikaMalladi

@adam_golinski

@brainshawn

@xiuyu_l

Vision LM inference without accelerators: Gemma.cpp (open source inference for CPU) now supports PaliGemma! If you're at #ECCV2024, @AndreasPSteiner will demo it tomorrow (Thu Oct 3) at 10:30 at the Google booth. Github: github.com/google/gemma.c…

How is next-token prediction capable of such intelligent behavior? I’m very excited to share our work, where we study the fractal structure of language. TLDR: thinking of next-token prediction in language as “word statistics” is a big oversimplification! arxiv.org/abs/2402.01825


Excited to share that @Google's OWLv2 model is now available in 🤗 Transformers! This model is one of the strongest zero-shot object detection models out there, improving upon OWL-ViT v1 which was released last year🔥 How? By self-training on web-scale data of over 1B examples⬇️

I'll give a talk on object-centric models for video and 3D at the @ICCVConference Workshop on Large-scale Video Object Segmentation! Today @ 3:30pm (Room S02) Website: youtube-vos.org/challenge/2023/ I'll cover DORSal (see below) & recent work from our team on structured video models.
Excited to announce DORSal: a 3D structured diffusion model for generation and object-level editing of 3D scenes. DORSal is “geometry-free” and learns 3D scene structure purely from data – no expensive volume rendering! 🖥️ sjoerdvansteenkiste.com/dorsal/ 📜 arxiv.org/abs/2306.08068 1/6
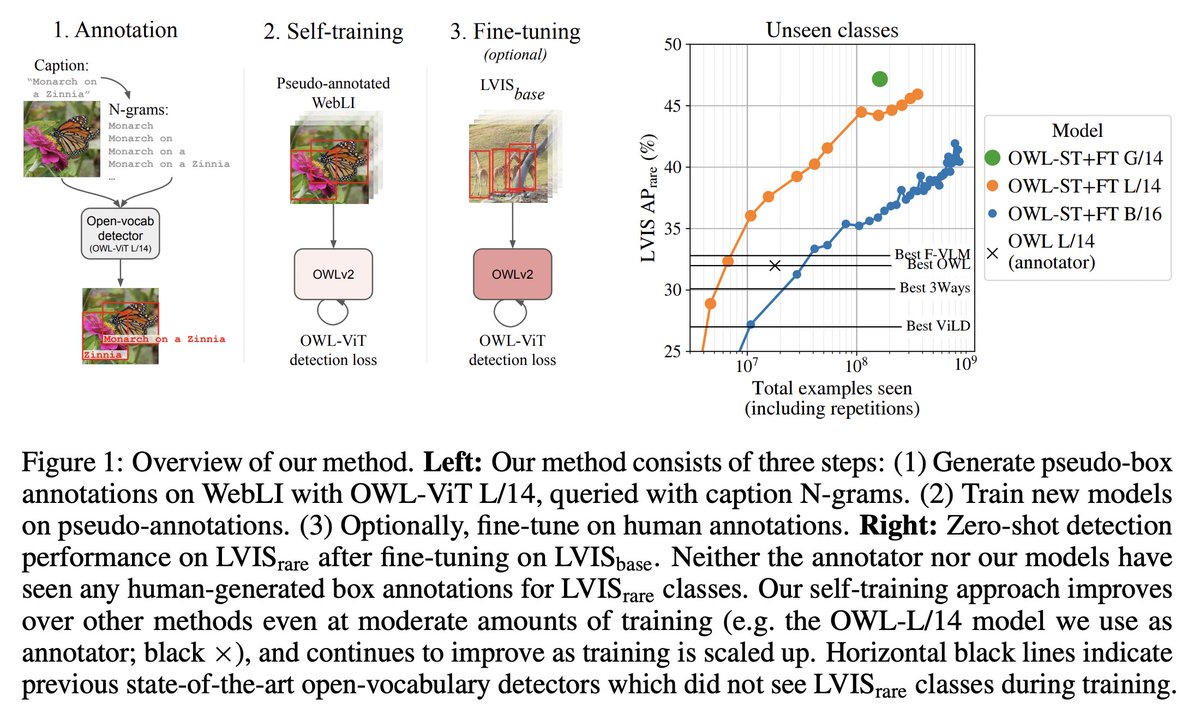
We just open-sourced OWL-ViT v2, our improved open-vocabulary object detector that uses self-training to reach >40% zero-shot LVIS APr. Check out the paper, code, and pretrained checkpoints: arxiv.org/abs/2306.09683 github.com/google-researc…. With @agritsenko and @neilhoulsby

Check out NaViT, a Vision Transformer that processes images at their native resolution. Apart from improving efficiency and performance of image-level tasks, pretraining at native resolution also produces better backbones for localization tasks like object detection.


Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution paper page: huggingface.co/papers/2307.06… The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been…

Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution paper page: huggingface.co/papers/2307.06… The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been…

Scaling Open-Vocabulary Object Detection Proposes OWLv2, which achieves SotA open-vocabulary detection already at 10M examples and further large improvement by scaling to over 1B examples. arxiv.org/abs/2306.09683

Scaling Open-Vocabulary Object Detection paper page: huggingface.co/papers/2306.09… Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can…

1/ There is a huge headroom for improving capabilities of our vision models and given the lessons we've learned from LLMs, scaling is a promising bet. We are introducing ViT-22B, the largest vision backbone reported to date: arxiv.org/abs/2302.05442

FlexiViT: One Model for All Patch Sizes abs: arxiv.org/abs/2212.08013 github: github.com/google-researc…


Transformers now supports image-guided object detection with OWL-ViT - find similar objects within an image using a query image of your target object. 🔥 Check it out, share it around and let me know what you think! Colab: colab.research.google.com/github/hugging… Demo: huggingface.co/spaces/adirik/…


Stop by the Google booth at #ECCV2022 at 3:30 pm today to see a demo presented by Austin Stone, @MJLM3 and @agritsenko about OWL-ViT, a simple and scalable approach for open-vocabulary object detection and image-conditioned detection. Try it yourself at bit.ly/owl-vit-demo.
OWL-ViT by @GoogleAI is now available @huggingface Transformers. The model is a minimal extension of CLIP for zero-shot object detection given text queries. 🤯 🥳 It has impressive generalization capabilities and is a great first step for open-vocabulary object detection! (1/2)

Announcing decoder denoising pretraining for semantic segmentation: arxiv.org/abs/2205.11423 Take a U-Net, pretrain the encoder on classification, pretrain the decoder on denoising, and fine-tune on semantic segmentation. This achieves a new SoTA on label efficient segmentation.
Simple Open-Vocabulary Object Detection with Vision Transformers abs: arxiv.org/abs/2205.06230

If you are interested in neural network calibration, please join us now at #NeurIPS2021 poster 27728: eventhosts.gather.town/app/DOlsyaA92T…
A few weeks ago, we open-sourced SCENIC, a JAX library/codebase that we like it a lot and wanted to share our joy with the community. GitHub: github.com/google-researc… Paper: arxiv.org/abs/2110.11403

SCENIC: A JAX Library for Computer Vision Research and Beyond abs: arxiv.org/abs/2110.11403 github: github.com/google-researc…











































































































United States Trends
- 1. #UFC309 125 B posts
- 2. Bo Nickal 6.512 posts
- 3. #MissUniverse 74,7 B posts
- 4. Tatum 24,2 B posts
- 5. Tennessee 51,3 B posts
- 6. Beck 20,3 B posts
- 7. Oregon 32,8 B posts
- 8. Paul Craig 3.638 posts
- 9. #GoDawgs 10,3 B posts
- 10. Georgia 95,3 B posts
- 11. Dinamarca 32,9 B posts
- 12. Nigeria 255 B posts
- 13. Locke 5.705 posts
- 14. Wisconsin 47,7 B posts
- 15. Venezuela 216 B posts
- 16. Dan Lanning 1.244 posts
- 17. gracie 19,9 B posts
- 18. Mike Johnson 43,2 B posts
- 19. Heupel 1.624 posts
- 20. Denmark 32,2 B posts
Who to follow
-
 Jannik Kossen
Jannik Kossen
@janundnik -
 Barret Zoph
Barret Zoph
@barret_zoph -
 Mostafa Dehghani
Mostafa Dehghani
@m__dehghani -
 Xiaohua Zhai
Xiaohua Zhai
@XiaohuaZhai -
 noahdgoodman
noahdgoodman
@noahdgoodman -
 Dani Yogatama
Dani Yogatama
@DaniYogatama -
 Preetum Nakkiran
Preetum Nakkiran
@PreetumNakkiran -
 Sjoerd van Steenkiste
Sjoerd van Steenkiste
@vansteenkiste_s -
 Olivier Bachem
Olivier Bachem
@OlivierBachem -
 Zhuang Liu
Zhuang Liu
@liuzhuang1234 -
 Ke Li 🍁
Ke Li 🍁
@KL_Div -
 Sadhika Malladi
Sadhika Malladi
@SadhikaMalladi -
 Adam Golinski
Adam Golinski
@adam_golinski -
 Xiao Wang
Xiao Wang
@brainshawn -
 Xiuyu Li
Xiuyu Li
@xiuyu_l
Something went wrong.
Something went wrong.