
Xueguang Ma
@xueguang_maPhD student at @uwaterloo. Working on encoding the world into vectors. Current part-time intern at @Meta. Prev. intern at @MSFTResearch, @amazon
Similar User

@luyu_gao

@dylan_wangs

@macavaney

@beirmug

@NegarEmpr

@rpradeep42

@crystina_z

@XiongChenyan

@alexlimh23

@thibault_formal

@EYangTW

@cadurosar

@mattlease

@joelmmackenzie

@XinyuShi9825
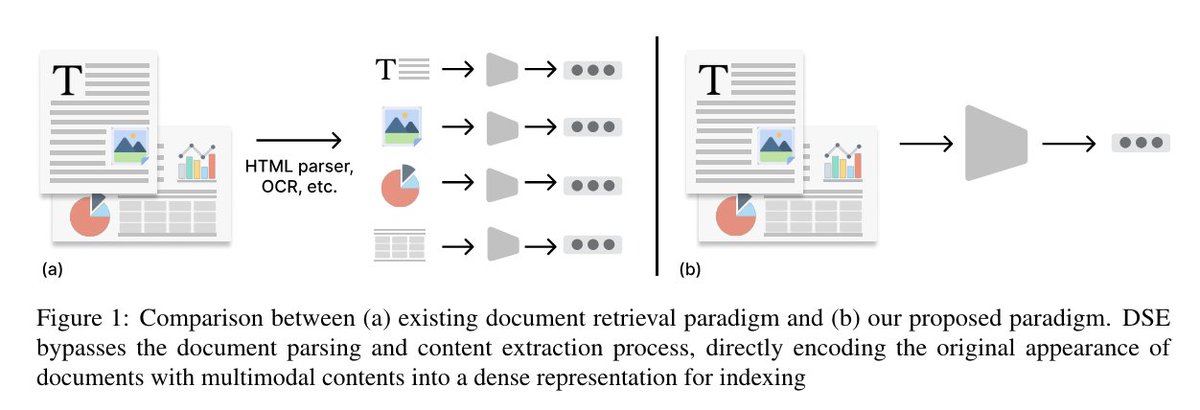
Introducing Document Screenshot Embedding (DSE): a new retrieval paradigm that unifies various formats and modalities into a single form for direct document encoding. paper: arxiv.org/abs/2406.11251 work done with amazing co-authors: @jacklin_64 @alexlimh23 @WenhuChen @lintool
Glad to see over 100 packages and repositories depending on BM25S (bm25s.github.io)! My main goal was to make a BM25 library that was easy to use but fast enough, so I'm glad it's useful 100+ public projects :)

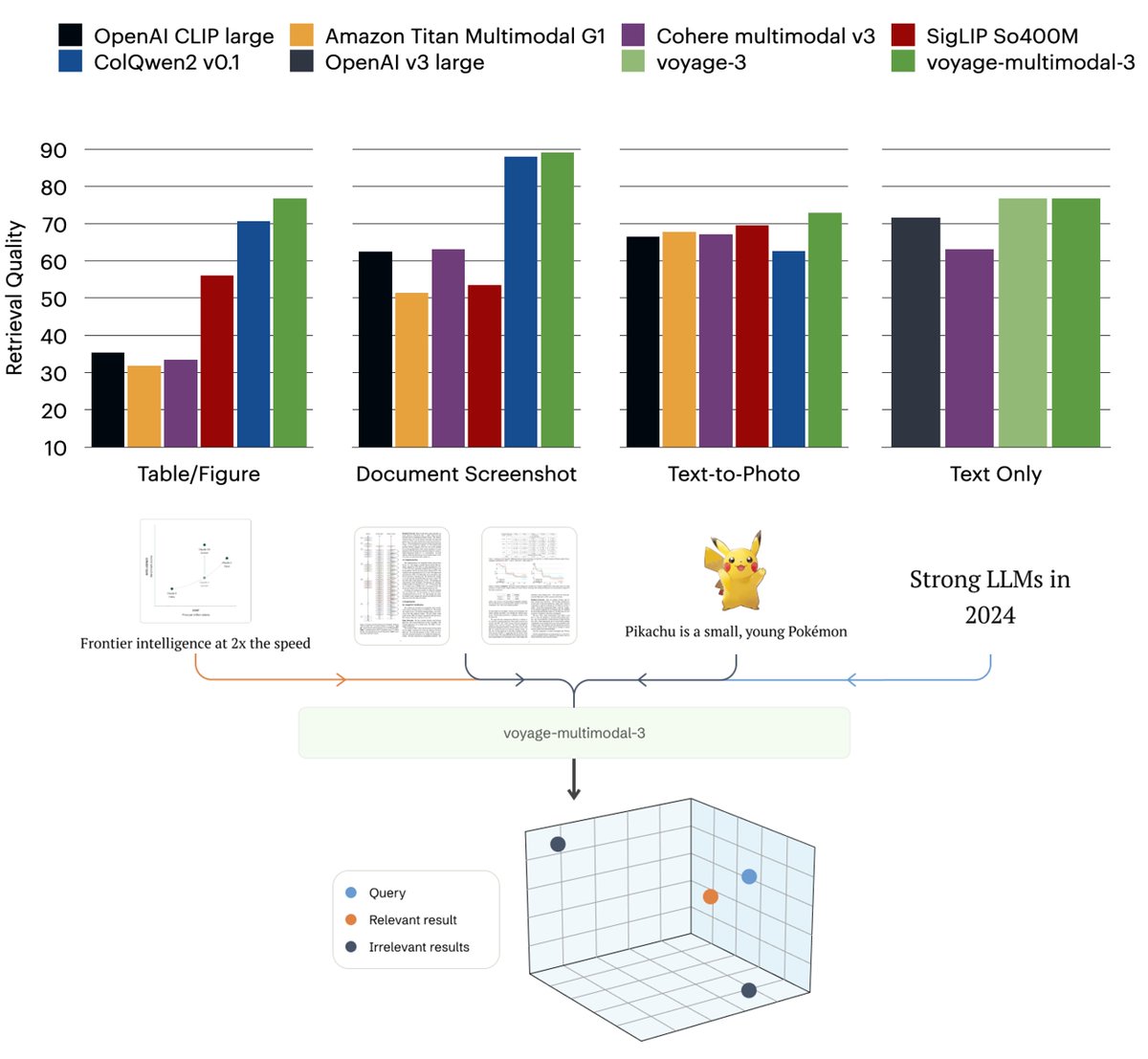
If you are looking for an open-source model that can do the same thing. e.g. represent image docs, pictures, or text only with a single vector. try or fine-tune our ckpt. huggingface.co/MrLight/dse-qw…


Congrats @ralph_tang and @crystina_z et. al. for getting outstanding paper award!

Attending the #EMNLP2024 award ceremony virtually was fun. Many thanks to my collaborators @crystina_z @Ulienida @yaolu_nlp @Wenyan62 Pontus @lintool @ferhanture, without whom the award would not have been possible. Check out the paper here: w1kp.com


Our #EMNLP2024 work OneGen now supports using Faiss as the vector retrieval engine! 🎉 Just set use_faiss to true in the inference section of the config.json file, and you’re all set! 🚀 #AI #NLP #RAG #LLM #OneGen Paper: arxiv.org/abs/2409.05152 Code: github.com/zjunlp/OneGen


Introducing our latest work, OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs 🚀. OneGen enables LLMs to perform retrieval during generation, utilizing less training data while achieving impressive performance and efficiency. #NLP #LLMs #RAG #Generation…




🤖Are multilingual LLMs able to understand "relevance" across languages? 🥼 Can we construct a reliable dataset to evaluate this? #EMNLP2024 Stop by our poster on Nov 14 (Thu), 10:30-12:00 @ Riverfront Hall by @crystina_z! Paper🎉: aclanthology.org/2024.findings-… @UWCheritonCS @Huawei

github.com/vllm-project/v… I just saw the ckpt is integrated to vllm by the community! appreciate it a lot!

💡Check MAIR at #EMNLP2024 A large-scale IR benchmark! Highlights: - Task Diversity: 126 realistic tasks, 8x than BEIR 📈 - Domain Coverage: 6 domains and heterogeneous sources 📚 - Instruction Following: 805 relevance criterions - Lightweight & Fast: optimized data sampling ⚡️

Not able to go Miami #EMNLP2024 due to visa issues. But @ShengyaoZhuang will present the work in person today. Chat with him and @dwzhu128, they know the details of our DSE work 😁 They will also present their amazing work PromptReps and LongEmbed on LLM IR and LongCtx IR.
Now accepted by #EMNLP2024 Main! What is the best way to process a document to be indexed for search? HTML parsing? OCR? Our answer is: don’t do any processing. Directly encode document original look with VLM to vector for search. Flow the gradients to its real appearance.
@sunweiwei12 will present our work about a massive benchmark for evaluating instructed retrieval at #EMNLP2024, joint work with Baidu search team @lingyongyan @xinyuma8 @Yiding_tanh @yindawei @Zhengliang_Shi

💡Check MAIR at #EMNLP2024 A large-scale IR benchmark! Highlights: - Task Diversity: 126 realistic tasks, 8x than BEIR 📈 - Domain Coverage: 6 domains and heterogeneous sources 📚 - Instruction Following: 805 relevance criterions - Lightweight & Fast: optimized data sampling ⚡️
This week at #EMNLP2024, I’ll be presenting our PromptReps and proxy presenting DSE for @xueguang_ma at poster session A (Riverfront Hall) from 11:00 to 12:30 on November 12th. After EMNLP, I’m off to DC for TREC. Come say hi!
1/7 🚨non-LLM paper alert!🚨 Human's perception of the sentence is quite robust against interchanging words with similar meanings, not even mentioning the semantically equivalent words across different languages. How about the language models? In our recent work, we measure the…

Introducing MM-Embed, the first multimodal retriever achieving SOTA results on the multimodal M-BEIR benchmark and compelling results (among top-5 retrievers) on the text-only MTEB retrieval benchmark. Paper: arxiv.org/abs/2411.02571 🤗 Model: huggingface.co/nvidia/MM-Embed

For multimodal RAG enthusiasts📣 mcdse-2b is a new performant, scalable and efficient multilingual document retrieval model ✨ 🪆 you can shrink it 6x with tiny degradation 🤏🏻 embed 100M pages in 10GB! 💨 run with transformers or vLLM

Introducing mcdse-2b-v1: a multilingual (🇮🇹 🇪🇸 🇬🇧 🇫🇷 🇩🇪) embedding model for flexible visual document retrieval. Trained on MrLight/dse-qwen2-2b-mrl-v1 (Qwen2-VL) using the DSE approach. It's like ColPali but multilingual and single-vector. - MRL: shrink embeddings from 1536 to…

🌍 I’ve always had a dream of making AI accessible to everyone, regardless of location or language. However, current open MLLMs often respond in English, even to non-English queries! 🚀 Introducing Pangea: A Fully Open Multilingual Multimodal LLM supporting 39 languages! 🌐✨…

Are you running out of money to run LLM as a Judge evals? 📉 Introducing 🏜️ MIRAGE-Bench, a multilingual RAG benchmark using heuristic metrics to train a *surrogate* judge to approximate LLM as a Judge evals for a synthetic RAG-based leaderboard! Paper: arxiv.org/abs/2410.13716



















































































United States Trends
- 1. $CATEX N/A
- 2. $CUTO 7.551 posts
- 3. #collegegameday 2.724 posts
- 4. $XDC 1.458 posts
- 5. #Caturday 7.974 posts
- 6. DeFi 107 B posts
- 7. Henry Silver N/A
- 8. Jayce 85,1 B posts
- 9. #saturdaymorning 3.163 posts
- 10. #Arcane 309 B posts
- 11. Good Saturday 37,1 B posts
- 12. Renji 4.062 posts
- 13. #MSIxSTALKER2 6.203 posts
- 14. Senior Day 2.999 posts
- 15. Pence 86,2 B posts
- 16. Fritz 9.149 posts
- 17. Cavuto N/A
- 18. Clyburn 1.167 posts
- 19. Zverev 7.330 posts
- 20. Bessent 2.370 posts
Who to follow
-
 Luyu Gao
Luyu Gao
@luyu_gao -
 Wang shuai (Dylan)
Wang shuai (Dylan)
@dylan_wangs -
 Sean MacAvaney
Sean MacAvaney
@macavaney -
 Nandan Thakur
Nandan Thakur
@beirmug -
 Negar Arabzadeh
Negar Arabzadeh
@NegarEmpr -
 Ronak Pradeep ✈️🌊EMNLP24
Ronak Pradeep ✈️🌊EMNLP24
@rpradeep42 -
 Xinyu Crystina Zhang @EMNLP🏝️
Xinyu Crystina Zhang @EMNLP🏝️
@crystina_z -
 Chenyan Xiong
Chenyan Xiong
@XiongChenyan -
 Minghan
Minghan
@alexlimh23 -
 Thibault Formal
Thibault Formal
@thibault_formal -
 Eugene Yang
Eugene Yang
@EYangTW -
 Carlos Lassance
Carlos Lassance
@cadurosar -
 Matt Lease
Matt Lease
@mattlease -
 Joel Mackenzie
Joel Mackenzie
@joelmmackenzie -
 Xinyu Shi
Xinyu Shi
@XinyuShi9825
Something went wrong.
Something went wrong.