

*Do LLMs learn to reason, or are they just memorizing?*🤔 We investigate LLM memorization in logical reasoning with a local inconsistency-based memorization score and a dynamically generated Knights & Knaves (K&K) puzzle benchmark. 🌐: memkklogic.github.io (1/n)


Our paper received a spotlight at @solarneurips! Looking forward to another great workshop this year

🚨Unlearned hazardous knowledge can be retrieved from LLMs 🚨 Our results show that current unlearning methods for AI safety only obfuscate dangerous knowledge, just like standard safety training. Here's what we found👇


Attending @COLM_conf from 10/6 to 10/9! If you want to chat about GenAI security, privacy, safety, or reasoning (I just started exploring it!), DM me :) & My team at @GoogleAI is looking for interns. Email me (yangsibo@google.com) your resume if you are interested.
CoTaEval got accepted by NeurIPS 2024 Datasets and Benchmarks! 🎉 In this work, we make an initial effort to evaluate the feasibility and side effects of copyright takedown methods for language models, showing significant room for research in this unique problem setting.
How to prevent LMs from generating copyrighted content? Strategies like system prompts, decoding interventions, and unlearning may come to your mind. But how effective are they in preventing long verbatim copy while preserving factual knowledge (non-copyrightable)? 🔬Introducing…

An Adversarial Perspective on Machine Unlearning for AI Safety 📖 ArXiv pre-print: arxiv.org/abs/2409.18025 Joint work with @javirandor, @wei_boyi, @YangsiboHuang, @PeterHndrsn and @florian_tramer

I’m deeply concerned about California’s SB-1047, Safe and Secure Innovation for Frontier Artificial Intelligence Models Act. While well intended, this bill will not solve what it is meant to and will deeply harm #AI academia, little tech and the open-source community.…

❗️Our recent paper on liability for AI "speech" was cited in a @nymag column on the topic! Read "Where's the Liability in Harmful AI Speech?": journaloffreespeechlaw.org/hendersonhashi… NYMag article: nymag.com/intelligencer/…

Why are transformers more powerful than fully-connected networks (FCNs) on sequential data (e.g. natural language)? Excited to introduce our #ICML2024 paper: arxiv.org/abs/2406.06893 Joint w/ @stanleyrwei, @djhsu, @jasondeanlee (1/n)

Please stop by if you are interested. See you on July 25th (Thursday) 1:30 p.m. — 3 p.m. in Hall C 4-9 #2309!
I can't make it to #ICML24 due to visa issues, but my awesome coauthors are presenting our 5 papers on AI safety & copyright! 1. [𝐁𝐞𝐬𝐭 𝐩𝐚𝐩𝐞𝐫 @ ICLR'24 SeTLLM] Assessing the Brittleness of Safety Alignment 👨🏫@wei_boyi 📍Poster Session 6 x.com/wei_boyi/statu…

🎁GPT-4o-mini just drops in to replace GPT-3.5-turbo! Well, how has its 🚨safety refusal capability changed over the past year? 📉GPT-3.5-turbo 0613 (2023) ⮕ 1106 ⮕ 0125 ⮕ GPT-4o-mini 0718📈 On 🥺SORRY-Bench, we outline the change of these models' safety refusal behaviors…

Our work (cotaeval.github.io) also shows that unlearning methods can unlearn the blocklisted content but at the cost of the utility. More importantly, the scalability and the offline cost of unlearning methods need to be considered when deploying them in the real world.

Can 𝐦𝐚𝐜𝐡𝐢𝐧𝐞 𝐮𝐧𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 make language models forget their training data? We shows Yes but at the cost of privacy and utility. Current unlearning scales poorly with the size of the data to be forgotten and can’t handle sequential unlearning requests. 🔗:…

Yangsibo is the best mentor I have ever met. If you are interested in collaboration, please do not hesitate to reach out!
I recently joined @GoogleAI in NYC as a research scientist. I'll continue working on 𝐌𝐋 𝐩𝐫𝐢𝐯𝐚𝐜𝐲 & 𝐬𝐞𝐜𝐮𝐫𝐢𝐭𝐲, while exploring new topics like 𝐜𝐨𝐩𝐲𝐫𝐢𝐠𝐡𝐭 & 𝐦𝐞𝐦𝐨𝐫𝐢𝐳𝐚𝐭𝐢𝐨𝐧. Up for coffee, chats & exploring NYC - DM me! (& in the Bay Area in late…
A great concurrent work on benchmarking copyright risks for LMs! Evaluating non-literal copying is indeed challenging. In our work (cotaeval.github.io), we use semantic similarity to assess this risk. CopyBench provides a new perspective and will contribute to a more…

📢Check out CopyBench, the first benchmark to evaluate non-literal copying in language model generation! ❗️Non-literal copying can occur even in models as small as 7B and is overlooked by current copyright risk mitigation methods. 🔗chentong0.github.io/copy-bench/ [1/N]

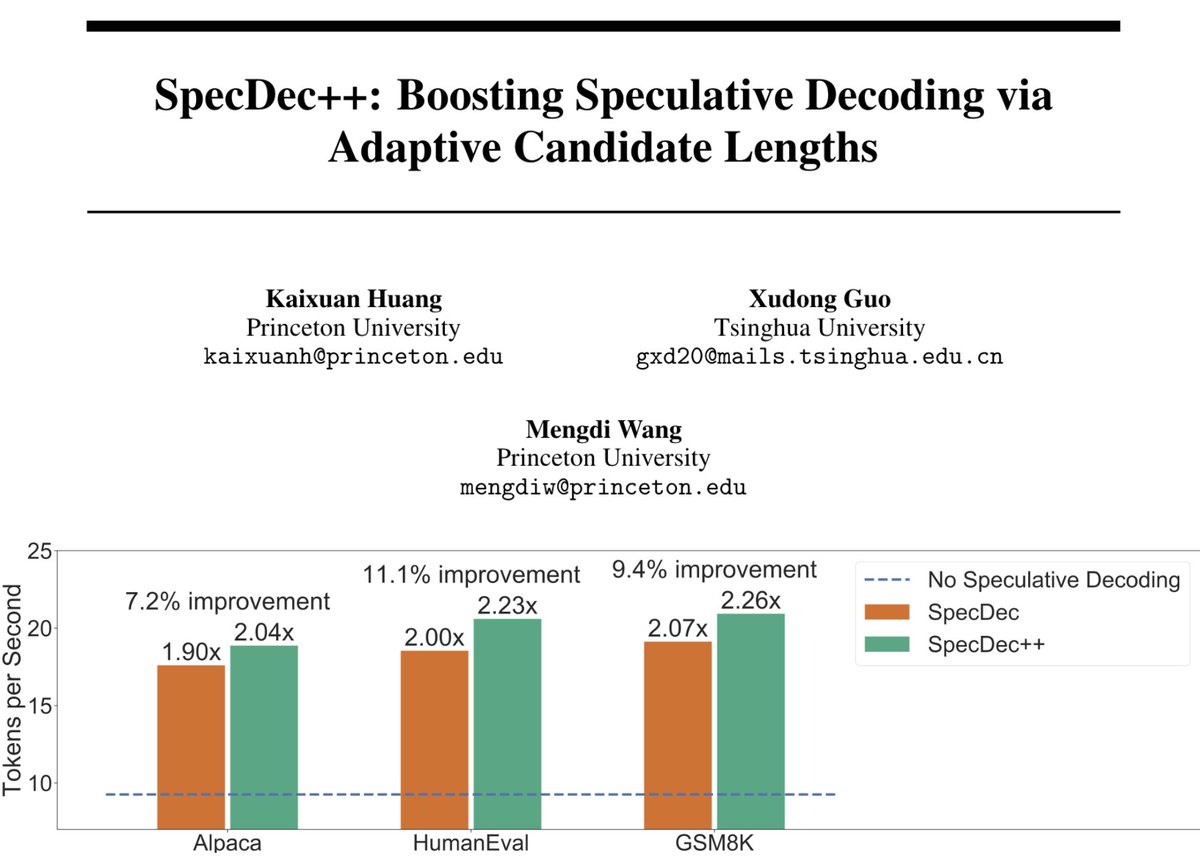
Introducing SpecDec++: Boosting Speculative Decoding via Adaptive Candidate Lengths 📢 (ES-FoMo @ ICML2024) An improved version of Speculative Decoding that further boosts your speedup! 📈 arxiv.org/abs/2405.19715 🧵 [1/n]

























































































United States Trends
- 1. #UFC309 293 B posts
- 2. Jon Jones 164 B posts
- 3. Jon Jones 164 B posts
- 4. Jon Jones 164 B posts
- 5. Chandler 87 B posts
- 6. Oliveira 71,5 B posts
- 7. Kansas 22,6 B posts
- 8. #discorddown 6.742 posts
- 9. Bo Nickal 8.889 posts
- 10. Do Bronx 10,9 B posts
- 11. Arod 2.151 posts
- 12. #BYUFootball 1.381 posts
- 13. Rock Chalk 1.377 posts
- 14. Tennessee 55,3 B posts
- 15. #MissUniverse 433 B posts
- 16. Keith Peterson 1.340 posts
- 17. Tatum 28,2 B posts
- 18. Oregon 34,3 B posts
- 19. #kufball 1.084 posts
- 20. Big 12 1.771 posts
Something went wrong.
Something went wrong.