
Sho Yokoi
@sho_yokoi_Researcher at #NLProc team @NlpTohoku & at #statistics team @RIKEN_AIP_EN | interested in geometry of word embedding space and optimal transport | Ja:@sho_yokoi
Similar User

@blankeyelephant
@yans_official

@tohoku_nlp

@nlp_colloquium

@jqk09a

@futsaludy

@shot4410

@goro_koba

@rtokuhisa

@esindurmusnlp

@moguranosenshi

@yuji_research

@hmtd223

@KaoriAbe11

@shunkiyono
This is a good piece of work (finally online): arxiv.org/abs/2411.00680 Word embeddings typically assume uniform word frequencies, but in reality, they follow Zipf’s law. Simply applying PCA whitening weighted by empirical word frequencies can improve task performance.
Interested in word frequency / geometry of language representations / contrastive learning? Check out our paper “Zipfian Whitening” at #NerIPS2024! See you all in Vancouver! 🇨🇦
Our paper “Zipfian Whitening” got accepted to #NeurIPS2024🎉 Joint work w/ amazing @levelfour_ @hiroto_kurita (@tohoku_nlp) & @hshimodaira! A simple idea—consider word frequency when taking expectations—yields rich empirical/theoretical insights into language representation🔬




Our paper “Zipfian Whitening” got accepted to #NeurIPS2024🎉 Joint work w/ amazing @levelfour_ @hiroto_kurita (@tohoku_nlp) & @hshimodaira! A simple idea—consider word frequency when taking expectations—yields rich empirical/theoretical insights into language representation🔬
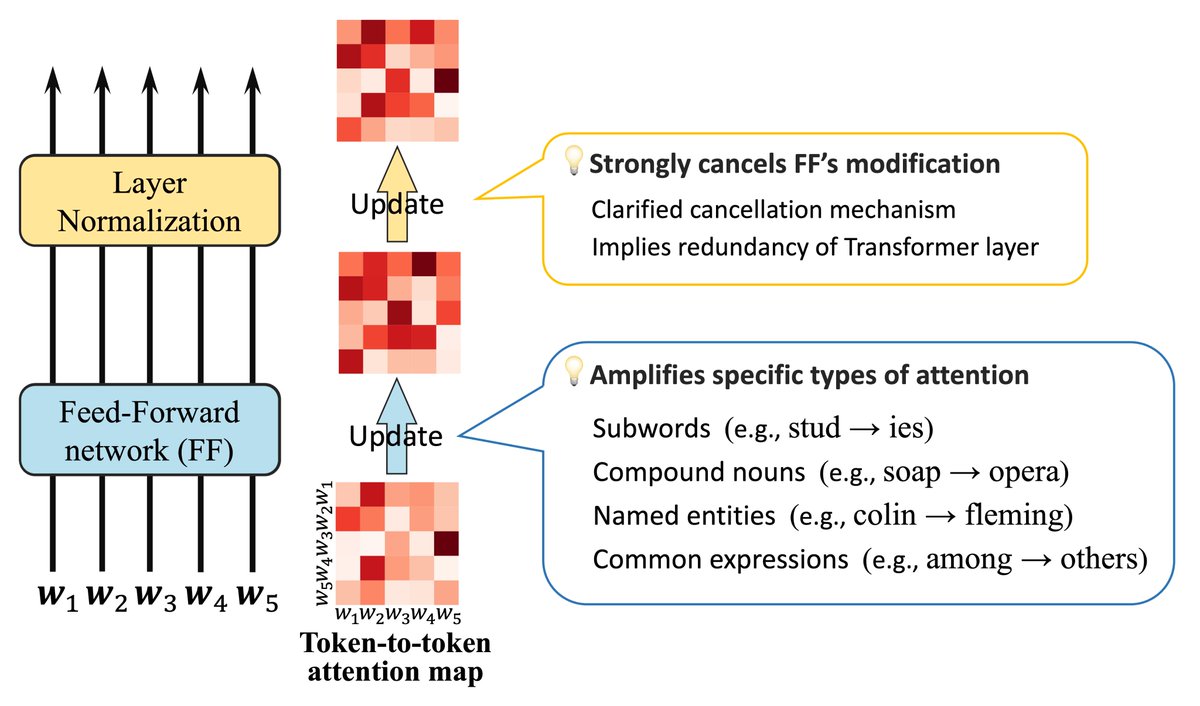
[CL] Analyzing Feed-Forward Blocks in Transformers through the Lens of Attention Map G Kobayashi, T Kuribayashi, S Yokoi, K Inui [Tohoku University & MBZUAI] (2023) arxiv.org/abs/2302.00456 - Transformers have become ubiquitous in NLP tasks, so interpreting their internals is…




Happy to share our paper on LM’s Feed-forward network (FF) analysis has been accepted as an #ICLR2024 spotlight! 💡FF boosts attention between words forming compound nouns, named entities, etc. 💡FF and LayerNorm cancel out each other’s effects 📄arxiv.org/abs/2302.00456
[ARR Co-CTO here] Quick correction - our policy is based on your arXiv submission time, which we acknowledge will sometimes mean the paper appears on arXiv inside the anonymity window (see the FAQ on the ARR author page for details: aclrollingreview.org/authors#faq)
The Tohoku NLP Lab will present nine works at #EMNLP2023. See you in Singapore! #NLProc nlp.ecei.tohoku.ac.jp


It's now on arXiv! arxiv.org/abs/2310.15921


Thrilled to announce my first paper, “Contrastive Learning for Sentence Encoder Induces Word Weighting by Information-Theoretic Quantities” got accepted at #EMNLP2023 findings! Our work connects sentence encoders with information theory. Will upload the paper to arXiv soon! 💨

Thrilled to announce my first paper, “Contrastive Learning for Sentence Encoder Induces Word Weighting by Information-Theoretic Quantities” got accepted at #EMNLP2023 findings! Our work connects sentence encoders with information theory. Will upload the paper to arXiv soon! 💨
Three full papers and four findings papers have been accepted to #EMNLP2023 ! #NLProc nlp.ecei.tohoku.ac.jp/news-release/9…
Cool idea! We actually observed that BERT tries to turn off attention by shrinking the value vector of [CLS] [SEP] punctuations and paying unnecessary attention there: arxiv.org/abs/2004.10102 I'd like to see his simpler trick will make Transformer better.


I hit a bug in the Attention formula that’s been overlooked for 8+ years. All Transformer models (GPT, LLaMA, etc) are affected. Researchers isolated the bug last month – but they missed a simple solution… Why LLM designers should stop using Softmax 👇 evanmiller.org/attention-is-o…
Introducing OTAlign, optimal transport (OT) based monolingual word alignment. We established a connection between the family of OT and monolingual word alignment concerning the null alignment ratio. (1/3) 📄arxiv.org/abs/2306.04116 w/ @levelfour_ and @sho_yokoi_ #ACL2023NLP
How the “prediction head” works in LMs? Our #ACL2023 Findings paper shows this module at the end of LMs adjusts word frequency in prediction 📊 (bonus) This property can easily be used to promote more diverse outputs of LMs! 📜 arxiv.org/abs/2305.18294

Monolingual alignment, anyone? Our #ACL2023NLP paper "Unbalanced Optimal Transport for Unbalanced Word Alignment" w/ @levelfour_ and @sho_yokoi shows the family of optimal transport are natural and powerful tools for this problem. More information coming soon. #NLProc
Hey! We've uploaded two pre-prints! One focuses on the intersection of vision, language, and cognitive science. arxiv.org/abs/2302.00667 The other examines the role of feedforward in Transformers. arxiv.org/abs/2302.00456 These are still **in progress**. Stay tuned for updates!


The separation of “(recognizing) textual entailment” and “natural language inference” in the peer-review field selection form for ACL 2023 is disturbing.
[CL] Subspace-based Set Operations on a Pre-trained Word Embedding Space Y Ishibashi, S Yokoi, K Sudoh, S Nakamura [NAIST & Tohoku University] (2022) arxiv.org/abs/2210.13034 #MachineLearning #ML #AI #NLP #NLProc


One paper entitled "Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem" has been accepted to #NAACL2022 (main conference, short paper) 🎉

Here is the slide of my today's talk at #NeurIPS Meetup Japan 2021. slideshare.net/SatoshiHara3/e…








































































































United States Trends
- 1. #PaulTyson 26,7 B posts
- 2. #SmackDown 40,6 B posts
- 3. Barrios 25,4 B posts
- 4. Rosie Perez 2.837 posts
- 5. Goyat 17,6 B posts
- 6. Evander Holyfield 2.445 posts
- 7. #NetflixFight 1.246 posts
- 8. #NetflixBoxing 1.008 posts
- 9. #netfilx 1.294 posts
- 10. Shinsuke 3.107 posts
- 11. Bronson Reed 3.101 posts
- 12. Cedric 6.661 posts
- 13. Purdue 6.711 posts
- 14. Lennox Lewis 1.208 posts
- 15. Bayley 5.492 posts
- 16. Cam Thomas 2.656 posts
- 17. My Netflix 10,4 B posts
- 18. Grok 48,7 B posts
- 19. LA Knight 4.746 posts
- 20. B-Fab 4.702 posts
Who to follow
-
 Hiroki Ouchi
Hiroki Ouchi
@blankeyelephant -
 YANS
YANS
@yans_official -
 Tohoku NLP Group
Tohoku NLP Group
@tohoku_nlp -
 NLPコロキウム
NLPコロキウム
@nlp_colloquium -
 Reina Akama
Reina Akama
@jqk09a -
 Takuma Udagawa
Takuma Udagawa
@futsaludy -
 Sho Takase
Sho Takase
@shot4410 -
 Goro Kobayashi
Goro Kobayashi
@goro_koba -
 Ryoko TOKUHISA / 徳久良子
Ryoko TOKUHISA / 徳久良子
@rtokuhisa -
 Esin Durmus
Esin Durmus
@esindurmusnlp -
 梶原智之
梶原智之
@moguranosenshi -
 Yuji NARAKI
Yuji NARAKI
@yuji_research -
 hiroshi matsuda
hiroshi matsuda
@hmtd223 -
 Kaori Abe
Kaori Abe
@KaoriAbe11 -
 Shun Kiyono
Shun Kiyono
@shunkiyono
Something went wrong.
Something went wrong.