
Pavan Kapanipathi
@pavankapsResearcher at IBM Research (Views are my own)
Similar User

@aviaviavi__

@LisaAmini1

@BadmotorF

@mraghava

@fusionconfusion

@nrkarthikeyan

@pablomendes

@ioanauoft

@icepieces

@KGreenewald

🚨 New Dataset Alert🚨 We introduce ACP Bench. A question-answering style dataset that evaluates AI-model's ability to reason about Action, Change, and Planning. Checkout 🔗 ibm.github.io/ACPBench/ 📄 arxiv.org/abs/2410.05669


We released best-in-class Apache 2.0 licensed models for detecting general harm and RAG hallucinations as part of the Granite 3.0 release! Read more: linkedin.com/pulse/ibm-open… Documentation: ibm.com/granite/docs/m… Hugging Face: huggingface.co/collections/ib… Try them out!

At IBM we just released Granite 3.0. It is not just another LLM; it's a suite of AI tools designed specifically for the enterprise's needs. These new tools are designed to scale GenAI to lower cost, govern it, and speed up innovation. It is: - Fit-for-purpose - Transparent with…


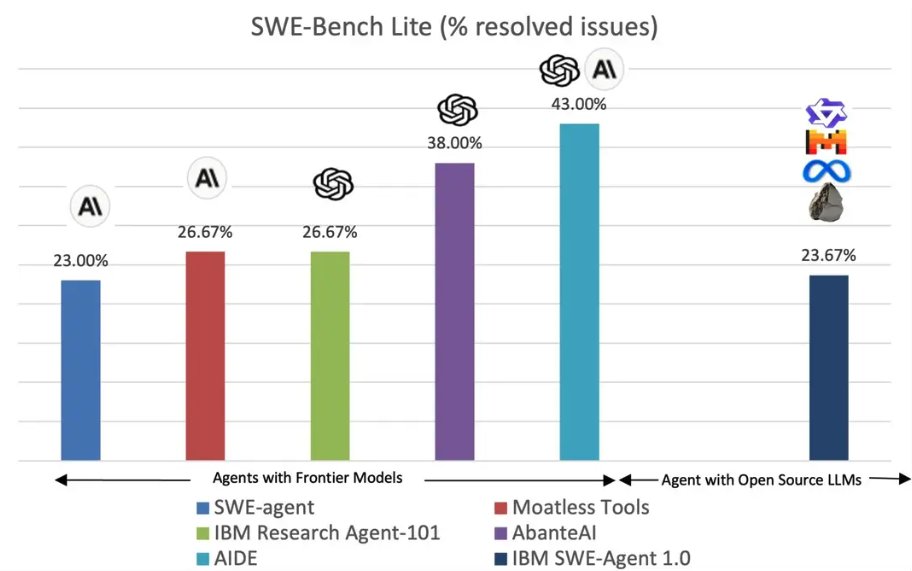
Announcing "@IBM SWE-Agent 1.0", from my team @IBMResearch , the first SWE-Agent built only on top of open-source models while achieving competitive performance (23.7%) compared to frontier LLM-agents on SWE-Bench. More details in this blog: ibm.biz/ibm_swe

🎉Today, we're pleased to announce the release of the Granite 3.0 model family, the latest open-licensed, general purpose LLMs from @IBM 🎉 These have been a labor of love for my team at @IBMResearch, working closely with a host of collaborators across the company. We're excited…


Granite 3.0 is our latest update for the IBM foundation models. The 8B and 2B models outperform strong competitors with similar sizes. The 1B and 3B MoE use only 400M and 800M active parameters to target the on-device use cases. Our technical report provides all the details you…


Minimizing forward KL wrt PPO-optimal policy (proceedings.neurips.cc/paper_files/pa……) policy doesn't perform as well for RLHF as PPO and DPO. Or does it? In our ICML paper (arxiv.org/abs/2402.02479), we show that it actually performs much better if an appropriate baseline is chosen.

Are you building and evaluating RAG systems? Presenting InspectorRAGet arxiv.org/abs/2404.17347 a platform for easily analyzing overall performance, instance level analysis, comprehensive metrics, and multiple models and more!

@RealAAAI nuclear-workshop.github.io workshop Neuro-Symbolic Learning and Reasoning in the Era of Large Language Models @GaryMarcus talk on “No AGI without Neurosymbolic AI.” @asimunawar @AvilaGarcez @frossi_t



IBM presents API-BLEND A Comprehensive Corpora for Training and Benchmarking API LLMs There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is…


Self-RAG in @llama_index We’re excited to feature Self-RAG, a special RAG technique where an LLM can do self-reflection for dynamic retrieval, critique, and generation (@AkariAsai et al.). It’s implemented in @llama_index as a custom query engine with…


A big downside of top-k RAG is its static nature. Self-RAG (@AkariAsai et al.) trains an LLM to do dynamic retrieval through self-reflection. This allows the LLM to 1) only perform retrieval if needed through a retrieval token, 2) generate/critique/filter retrieved outputs, and…


We are releasing `v0.5.4` version of the transition-amr-parser. Now with document-level AMR parsing, instalable from PyPI, shipped with trained checkpoints and SoTA performance. github.com/IBM/transition…


We can all agree we’re at a unique and evolutionary moment in AI, with enterprises increasingly turning to this technology’s transformative power to unlock new levels of innovation and productivity. At #Think2023, @IBM unveiled watsonx. Learn more: newsroom.ibm.com/2023-05-09-IBM…

If you're using GPT-3 or any other LLMs read this: 1. Don't want it to hallucinate? 2. Need attribution for generated answers? 3. Have access to proprietary data that you want to index yourself and generate answers from it? Use PrimeQA! We added "retrieve" and "read" mode.🧵


Good article on LLMs at Forbes. The media are starting to agree with my much-criticized statements about LLMs. "LLMs as they exist today will never replace Google Search. Why not? In short, because today’s LLMs make stuff up." forbes.com/sites/robtoews…


Happy to see that our chemical language foundation model, MoLFormer is highlighted in @NatComputSci In addition to showing competitive performance in standard prediction benchmarks, it also shows first-of-a-kind emergent behavior with scaling, e.g. learning of geometry and taste

Finally, we highlight a @NatMachIntell paper by @payel791 and colleagues on a large-scale transformer-based language model that enables the encoding of spatial information in molecules. nature.com/articles/s4358… 👉rdcu.be/c31BO

Join us today for a very exciting 3rd day of IBM Neuro-Symbolic AI Workshop 2023. Day 3 is all about NLP, large language models like #ChatGPT and what can we expect from future models. Day 3 talks by @GaryMarcus @alkoller Kathy McKeown @hhexiy #ArtificialIntelligence #IBM
I am very excited to invite you to IBM Neuro-Symbolic AI Workshop 2023 (23-27 Jan, 9 am-12 pm ET). This is the 2nd workshop of the series. Register for free at: ibm.biz/nsworkshop2023 #ai #ibmresearch

@IBMResearch workshop on Neurosymbolic AI on the way. Alex Gray opening and @vardi on Deep Learning and Deep Reasoning - Neurosymbolic Reasoning. @frossi_t @asimunawar @GaryMarcus @AvilaGarcez @guyvdb



.@ArvindKrishna summarizes our efforts at @IBM and @IBMResearch on responsible and trustworthy AI in this video. This is precisely what I have the privilege to work on every day. youtube.com/watch?v=gdAVw1…
PrimeQA now has collaborators & code contributions from @stanfordnlp, @osunlp, @NotreDame , @LTIatCMU, @uiuc_nlp , @UMassAmherst, @Uni_Stuttgart & many more on the way bringing in their best Question Answering (QA) models to advance the research in QA. What are you waiting for?


Two more days to go!!! Looking forward to your submissions. cc: @pavankaps @sbhatia_ @pascalhitzler @ejimenez_ruiz @nandanamihindu

5 more days to go for participating in the ISWC 2022 Semantic Reasoning Evaluation Challenge #SemREC. You can participate by submitting your (hard to reason over) ontologies and neuro-symbolic reasoners semrec.github.io @mraghava @pavankaps @iswc_conf #iswc2022





















































































































United States Trends
- 1. Thanksgiving 788 B posts
- 2. Dylan Harper 4.399 posts
- 3. Druski 23,3 B posts
- 4. Kevin Hart 12,5 B posts
- 5. Pat Spencer 1.091 posts
- 6. Shai 6.506 posts
- 7. Friday Night Lights 16,4 B posts
- 8. Tyrese Martin 1.783 posts
- 9. Jalen Williams 1.901 posts
- 10. #AEWDynamite 25,4 B posts
- 11. #Survivor47 4.514 posts
- 12. Knicks 13,2 B posts
- 13. Zuck 10,7 B posts
- 14. RJ Davis N/A
- 15. Kuminga 2.514 posts
- 16. Cruz Azul 23,6 B posts
- 17. Vindman 63,1 B posts
- 18. Izzo 1.695 posts
- 19. Ace Bailey 1.267 posts
- 20. Hubert 3.885 posts








Something went wrong.
Something went wrong.