
Marcus Hutter
@mhutter42I 👨🔬 a mathematical definition&theory of Artificial General Intelligence 🎥&🎤@ https://t.co/OZsooP92mn 🍀 I now work @GoogleDeepMind 🧠 History:🇩🇪🇨🇭🇦🇺🇬🇧
Similar User

@SchmidhuberAI

@ZoubinGhahrama1

@shimon8282

@danijarh

@TheGregYang

@sirbayes

@marcgbellemare

@ShaneLegg

@quocleix

@vernadec

@aleks_madry

@kenneth0stanley

@neu_rips

@DanHendrycks

@FeryalMP
My new book finally ships! You fear your math is not up to scratch? Fear not, over 100 pages are devoted to introducing the relevant concepts. routledge.com/An-Introductio… #AI #AGI #ArtificialIntelligence #Math #Maths #machinelearning #ReinforcementLearning

New paper! Over-optimization in RL is well-known, but it even occurs when KL(policy || base model) is constrained fairly tightly. Why? And can we fix it? 🧵

Our cover article mdpi.com/1099-4300/26/9 and other articles in the special issue on 'Time and Temporal Asymmetries' mdpi.com/journal/entrop… provide some new insights into an old problem. #Entropy #ArrowOfTime #Thermodynamics

Besides Ilya Sutskever, Microsoft CTO Kevin Scott also "gets" #Solomonoff: youtu.be/aTQWymHp0n0&t=… You can find a gentle introduction to his theory in dx.doi.org/10.3390/e13061… and its #ASI relevance in my new #AI book x.com/mhutter42/stat…

Microsoft CTO Kevin Scott Reflects on AI Pioneer Ray Solomonoff In a recent interview with Pat Grady from Sequoia Capital, Microsoft CTO Kevin Scott shared his admiration for Ray Solomonoff, a pivotal figure in the history of AI. Solomonoff, one of the key participants in the…
Don't miss this ICML Spotlight Talk by one of my colleagues, and/or even better read his very nice exposition illustrating why and how randomness deficiency overcomes the deficiency of existing approaches to realism and outlier detection.

What does it mean for an image, video, or text to be 𝑟𝑒𝑎𝑙𝑖𝑠𝑡𝑖𝑐? Despite how far we've come in 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑖𝑛𝑔 realistic data, 𝑞𝑢𝑎𝑛𝑡𝑖𝑓𝑦𝑖𝑛𝑔 realism is still a poorly understood problem. I've shared my thoughts on how to correctly quantify realism here:…
Are you interested in AGI but a bit exhausted keeping up with Deep Learning? Why not take a break and watch the Cartesian Cafe podcast covering (a tiny fraction of) my new book. youtube.com/watch?v=7TgOwM… #ai #artificialintelligence #math #maths #machinelearning

Want to see a paper "stating the obvious" (@ChrSzegedy) where "the main message is unclear" and "regardless of the message, the evidence falls short" (@DimitrisPapail)? Check out our poster "Language Modeling Is Compression" tomorrow! ⏰ 10:45 - 12:45 📍Halle B #139 #ICLR2024
tinyurl.com/ywyoqw3r Exploring the edges of meta-learning by training neural networks with Universal Turing Machine-generated data to learn universal prediction strategies. Groundbreaking work in blending Solomonoff Induction with AI. #MachineLearning #NeuralNetworks

Check out our latest paper, which approximates Solomonoff induction by meta-learning on data from Universal Turing Machines. Learning Universal Predictors 📄 arxiv.org/abs/2401.14953 💻 github.com/google-deepmin…
What do you get when you cross modern Machine Learning with good old-fashioned Search? An IJCAI distinguished paper award 🙂 for Levin Tree Search with Context Models: aihub.org/2023/08/23/con…
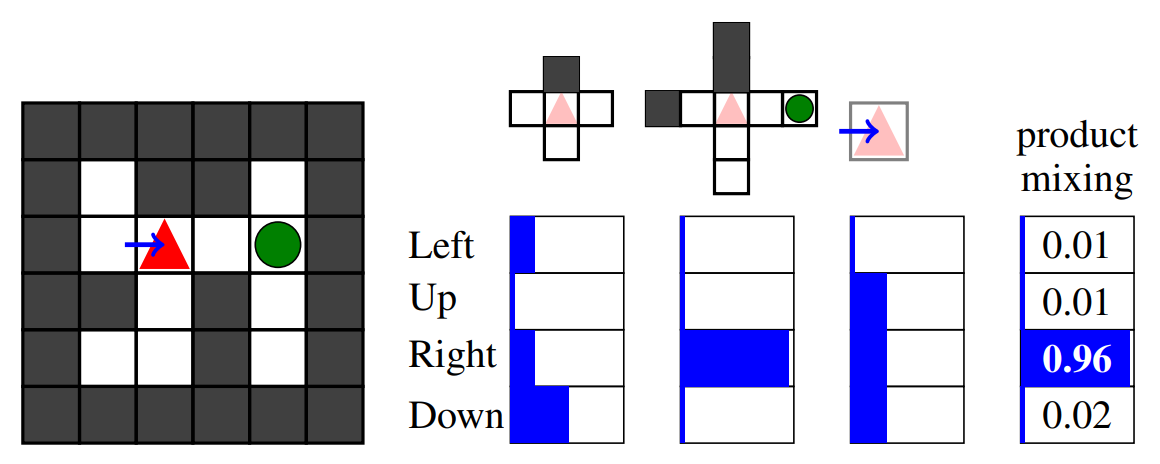
Great review of theories&indicators of consciousness 👍, but limited to computational functionalism. Chalmers and Tononi and Qualia are out of scope 🙁. Also, society will eventually only care about the behavior of the AIs and not their inner workings. arxiv.org/abs/2308.08708
Ilya Sutskever explains how Kolmogorov complexity well-defines unsupervised learning and LLMs are approximations thereof. Nothing new but very accessible, and maybe it makes it more convincing if it comes from the Chief Scientist of OpenAI.

There're few who can deliver both great AI research and charismatic talks. OpenAI Chief Scientist @ilyasut is one of them. I watched Ilya's lecture at Simons Institute, where he delved into why unsupervised learning works through the lens of compression. Sharing my notes: -…
Some progress on a very old problem: Principled "exact" line search algorithms for general convex functions with (3-point method) and without (5-point method) using (sub)gradient information. arxiv.org/abs/2307.16560

Progress on the Human Knowledge Compression front: Saurabh Kumar is the second winner of the 10x (1GB) version, winning €5187, by beating the previous record by 1.04%. Who wants to try next? prize.hutter1.net

So elegant! And the proof even fits in the Twitter "margin": The determinant is a linear function in (x²+y²+z²,x,y,z,1), and equals 0 if (x,y,z) is one of the 4 points, since then two rows coincide.


This paper arxiv.org/abs/2210.12392 in large is just another statistics paper, but Section 2 explains its potential relevance for Deep Learning: It's a(nother) warning why the still prevalent i.i.d. train/test paradigm is not suitable for AGI.





































































































United States Trends
- 1. Mike 1,73 Mn posts
- 2. #Arcane 174 B posts
- 3. Serrano 243 B posts
- 4. Jayce 30,4 B posts
- 5. vander 8.909 posts
- 6. Canelo 17,2 B posts
- 7. maddie 14,3 B posts
- 8. #NetflixFight 74,7 B posts
- 9. Jinx 85,6 B posts
- 10. Logan 78,8 B posts
- 11. Father Time 10,5 B posts
- 12. He's 58 28,6 B posts
- 13. #netflixcrash 16,7 B posts
- 14. Boxing 308 B posts
- 15. ROBBED 99,7 B posts
- 16. Rosie Perez 15,2 B posts
- 17. #buffering 11,2 B posts
- 18. Tori Kelly 5.425 posts
- 19. Isha 22,5 B posts
- 20. Shaq 16,7 B posts
Who to follow
-
 Jürgen Schmidhuber
Jürgen Schmidhuber
@SchmidhuberAI -
 Zoubin Ghahramani
Zoubin Ghahramani
@ZoubinGhahrama1 -
 Shimon Whiteson
Shimon Whiteson
@shimon8282 -
 Danijar Hafner
Danijar Hafner
@danijarh -
 Greg Yang
Greg Yang
@TheGregYang -
 Kevin Patrick Murphy
Kevin Patrick Murphy
@sirbayes -
 Marc G. Bellemare
Marc G. Bellemare
@marcgbellemare -
 Shane Legg
Shane Legg
@ShaneLegg -
 Quoc Le
Quoc Le
@quocleix -
 Claire Vernade @ EWRL in Toulouse
Claire Vernade @ EWRL in Toulouse
@vernadec -
 Aleksander Madry
Aleksander Madry
@aleks_madry -
 Kenneth Stanley
Kenneth Stanley
@kenneth0stanley -
 Gergely Neu
Gergely Neu
@neu_rips -
 Dan Hendrycks
Dan Hendrycks
@DanHendrycks -
 Feryal
Feryal
@FeryalMP
Something went wrong.
Something went wrong.