
Michael Carbin
@mcarbinAssociate Professor in EECS at @MIT | Founding Advisor at @mosaicml | Programming Systems | Neural Networks | Approximate Computing
Similar User

@jefrankle

@SebastienBubeck

@ZoubinGhahrama1

@zicokolter

@TheGregYang

@FidlerSanja

@ShamKakade6

@aleks_madry

@tomgoldsteincs

@HazanPrinceton

@gkdziugaite

@NeerajaJY

@RogerGrosse

@IsilDillig

@JohnCLangford
Meet MPT-7B and its children! Proud of the @MosaicML team for delivering a new open standard for LLMs. Built with the same data, training, and eval tools that we make available to you to build your own LLM.
MPT is here! Check out our shiny new LLMs, open-source w/commercial license. The base MPT-7B model is 7B params trained on 1T tokens and reaches LLaMA-7B quality. We also created Instruct (commercial), Chat, and (my favorite) StoryWriter-65k+ variants. 🧵 mosaicml.com/blog/mpt-7b

Super excited to join @databricks Mosaic Research team @DbrxMosaicAI! Looking forward to solving important research challenges in foundation models with my amazing team members and unlocking their full potential to accurately solve real-world problems.

Excited to announce our new work: Critique-out-Loud (CLoud) reward models. CLoud reward models first produce a chain of thought critique of the input before predicting a scalar reward, allowing reward models to reason explicitly instead of implicitly! arxiv.org/abs/2408.11791

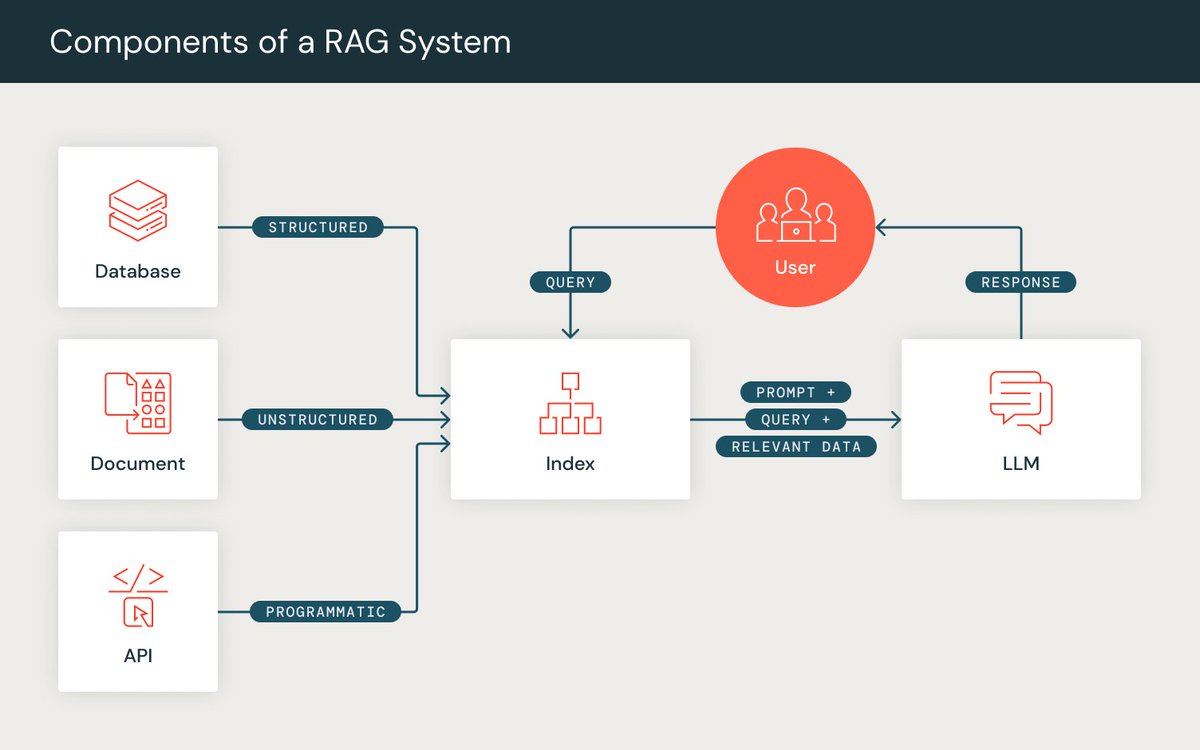
Personal News: I started today at @Databricks @DbrxMosaicAI as a Research Scientist Intern in the Bay area! 🧑🏻💻 ✨ I'm excited to push research forward in the RAG team, build standardized benchmarks, and improve RAG-based evaluations. Anyone in SF, let's hangout and meet up! 🤝


Function calling significantly enhances the utility of LLMs in real-world applications; however, evaluating and improving this capability isn't easy — and no one benchmark tells the whole story. Learn more about our approach in the latest blog from @databricks:…


Does long context solve RAG? We found that many long-context models fail in specific and weird ways as you grow context length, making the optimal system design non-obvious. Some models tend to say there's a copyright issue, some tend to summarize, etc. databricks.com/blog/long-cont…

How good do the latest long context LLMs (LLama-3.1-405b, GPT-4o-mini and Claude-3.5-sonnet) perform on RAG? We benchmarked 13 popular OSS and commercial models on context lengths from 2k to 125k, and the results are very interesting! Full post: databricks.com/blog/long-cont…
New paper where we explore using a small LM’s perplexity to prune the pretraining data for larger LMs. We find that small LMs can prune data for up to 30x larger LMs, data pruning works in the overtrained and data-constrained regimes, and more! arxiv.org/abs/2405.20541

You know your CTO (@matei_zaharia) got the dog in him when the company is worth 40B+ and he's still looking at data and labeling


DSPy x DBRX 🔥
Ready to use a programmatic approach to prompting #LLMs and building #RAG applications? The @stanfordnlp #dspy repo includes support for @databricks Model Serving and Vector Search! Details: databricks.com/blog/dspy-data…

I tried getting gpt-4-turbo to generate useful code from openai assistants docs. it failed. Claude-opus did better, but it's bad at coding. the new dbrx absolutely spanked the other models. chatcraft.org/api/share/tara…

@DbrxMosaicAI DBRX outperforms @OpenAI GPT-4 on realistic, domain-specific benchmark datasets. For example, on a customer support summarization use-case👇👇👇 Still neck and neck but it shows that open models can be the no-brainer choice for actual enterprise applications.


speaking of mosaic/databricks, i’ve ported so much code to versions of composer/streaming. it’s just so good.

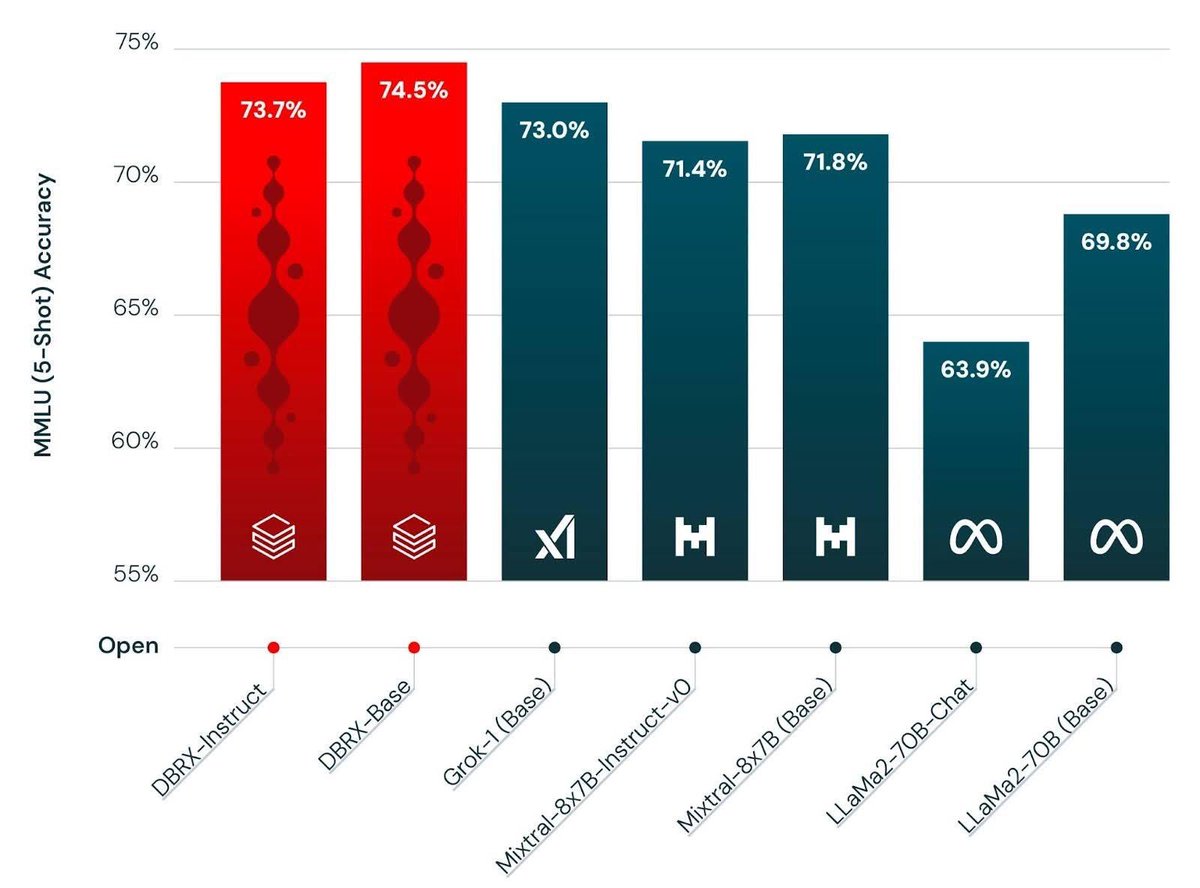
It’s finally here 🎉🥳 In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯

If you're curious about how DBRX was trained come by!
Curious about #DBRX and how it was trained? Join @abhi_venigalla and @ajaysaini725 to learn about the model and the @databricks platform that trained it! Hosted by our own Eric Peter, and the AI Alliance's @TimBonnemann and @ChiefScientist! lu.ma/kiidiyeb
How to Science: 1) replicate your comparisons where possible, 2) make strongest baselines you can think of, 3) ablate your work to death. If your idea survives all that, it might stand a chance. Oh yea and report it all in the appendix! Pass that science along.

I'm writing this cause I'm a bit salty. We've implemented so many seemingly promising, published & popular papers only for them to utterly flop. At least I like to think that my personal bs Big Model paper classifier is now pretty good given my extensive training data.



Best open model right now and >3x more efficient to serve than GPT-3.5 and 4 on our platform!
Meet DBRX, a new sota open llm from @databricks It's a 132B MoE with 36B active params trained from scratch on 12T tokens. It sets a new bar on all the standard benchmarks, and - as an MoE - inference is blazingly fast. Simply put, it's the model your data has been waiting for.


Scoop: Grok had a good run but there’s a new open source model that beats out the rest: DBRX. I got an inside look at the impressive work that went into building it: wired.com/story/dbrx-ins…
















































































































United States Trends
- 1. Thankful 66,7 B posts
- 2. #RTXOn 7.501 posts
- 3. #PMSLive 3.977 posts
- 4. #twug 3.257 posts
- 5. Sharon Stone 2.784 posts
- 6. Happy Thanksgiving 29,4 B posts
- 7. $ELONIA 1.702 posts
- 8. Hezbollah 160 B posts
- 9. Creighton 2.581 posts
- 10. Lebanon 192 B posts
- 11. #PumpRules 3.836 posts
- 12. Johnie Cooks N/A
- 13. Xanadu 1.268 posts
- 14. Rivian 9.679 posts
- 15. Mack Brown 5.064 posts
- 16. $CUTO 7.456 posts
- 17. #GivingTuesday 3.290 posts
- 18. Broyles Award N/A
- 19. Avocados 10,3 B posts
- 20. Billboard 581 B posts
Who to follow
-
 Jonathan Frankle
Jonathan Frankle
@jefrankle -
 Sebastien Bubeck
Sebastien Bubeck
@SebastienBubeck -
 Zoubin Ghahramani
Zoubin Ghahramani
@ZoubinGhahrama1 -
 Zico Kolter
Zico Kolter
@zicokolter -
 Greg Yang
Greg Yang
@TheGregYang -
 Sanja Fidler
Sanja Fidler
@FidlerSanja -
 Sham Kakade
Sham Kakade
@ShamKakade6 -
 Aleksander Madry
Aleksander Madry
@aleks_madry -
 Tom Goldstein
Tom Goldstein
@tomgoldsteincs -
 Elad Hazan
Elad Hazan
@HazanPrinceton -
 Gintare Karolina Dziugaite
Gintare Karolina Dziugaite
@gkdziugaite -
 Neeraja Yadwadkar
Neeraja Yadwadkar
@NeerajaJY -
 Roger Grosse
Roger Grosse
@RogerGrosse -
 Isil Dillig
Isil Dillig
@IsilDillig -
 John Langford
John Langford
@JohnCLangford
Something went wrong.
Something went wrong.