
Manuel Madeira
@manuelmlmadeiraPhD student @epfl | trying to boost science via machine learning
Similar User

@alesfav

@arahmani_AR

@amodas_

@tml_lab

@leopetrini_

@haririAli95

@cruzfabios

@Im_Pratas

@SkanderMoalla
Python Optimal Transport (POT) 0.9.5 released: new solvers for Gaussian Mixture Model OT, unbalanced OT, semi-relaxed (F)GW barycenters, unbalanced FGW and COOT, partial GW. more details in 🧵1/7 github.com/PythonOT/POT/r…

Fine-tuning pre-trained models leads to catastrophic forgetting, gains on one task cause losses on others. These issues worsen in multi-task merging scenarios. Enter LiNeS 📈, a method to solve them with ease. 🔥 🌐: lines-merging.github.io 📜: arxiv.org/abs/2410.17146 🧵 1/11
Looking forward to your contributions!

📢 Deadline Extended! Submit your manuscript for the IEEE TSIPN Special Issue on Learning on Graphs for Biology & Medicine by Nov 1, 2024. Don’t miss your chance to contribute to cutting-edge research! hubs.la/Q02NH26N0 🧬📊 #IEEE #GraphLearning #Biomedicine #Research

It was fun to present our work at @GRaM_org_ yesterday :) Thanks to everyone who stopped by to discuss, and thanks to the organizers for making such an inspiring workshop happen!



Congratulations to @olgazaghen for having her Master's thesis accepted at @GRaM_workshop! 🎉 📜 Sheaf Diffusion Goes Nonlinear: Enhancing GNNs with Adaptive Sheaf Laplacians. 📎 openreview.net/pdf?id=MGQtGV5… With: Olga @steveazzolin @lev_telyatnikov @andrea_whatever @pl219_Cambridge

See you at @arlet_workshop @icmlconf Poster Session 1 between 1:30 - 2:30 pm (Schubert 1 - 3)!


Have you ever been left puzzled by your PPO agent collapsing out of nowhere? 📈🤯📉 We’ve all been there... We can help you with a hint: monitor your representations!💡 🚀 We show that PPO suffers from degrading representations and that this breaks its trust region 💔

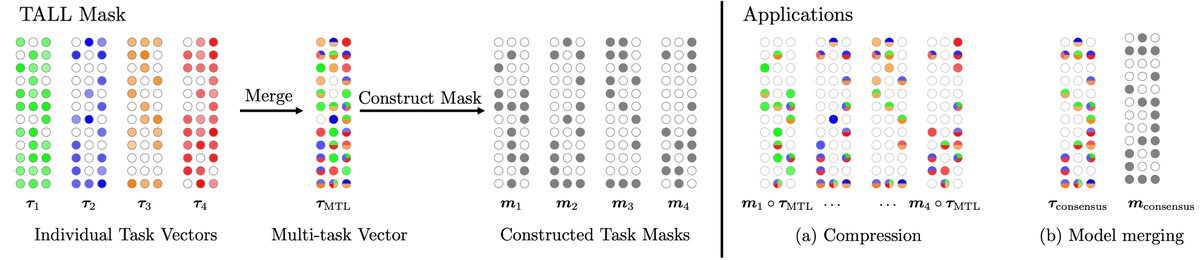
Good morning ICML🇦🇹 Presenting today "Localizing Task Information for Improved Model Merging and Compression" with @wangkeml @gortizji @francoisfleuret @pafrossard Happy to see you at poster #2002 from 11:30 to 13:00 if you are interested in model merging & multi-task learning!

Wouldn't it be great if we could merge the knowledge of 20 specialist models into a single one without losing performance? 💪🏻 Introducing our new ICML paper "Localizing Task Information for Improved Model Merging and Compression". 🎉 📜: arxiv.org/pdf/2405.07813 🧵1/9
I'm also at ICML -- excited to present our paper on training + LR schedules as a spotlight (!) at the workshop on the next gen of seq. models as well as ES-FOMO on Fri🤙 Reach out to discuss methods for training open models, scaling, efficiency, or the future of architectures :)
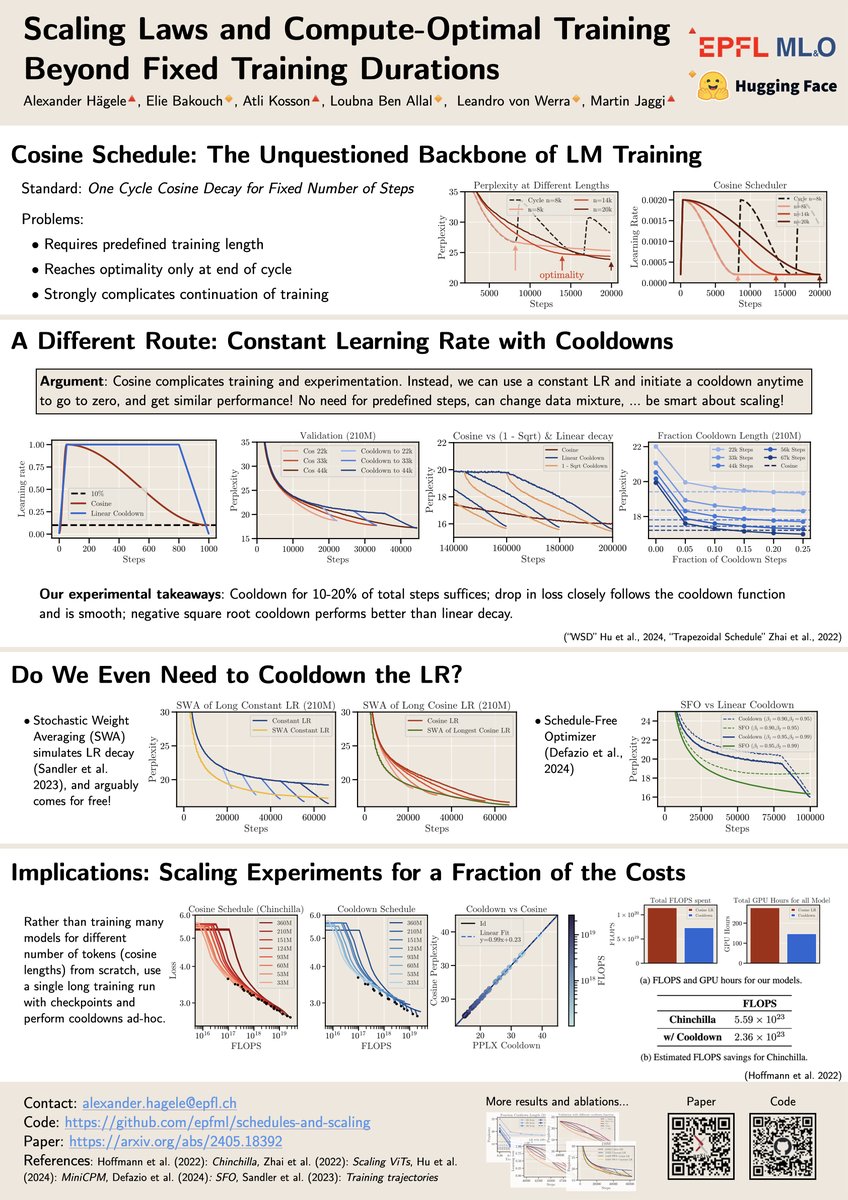

Why exactly do we train LLMs with the cosine schedule, still?🤔 Maybe we do not actually have to -- and that would come with a lot of benefits :) 🧵Our paper on LR schedules, compute-optimality and more affordable scaling laws

























































































United States Trends
- 1. $CATEX N/A
- 2. $CUTO 7.491 posts
- 3. #collegegameday 2.359 posts
- 4. $XDC 1.416 posts
- 5. #Caturday 7.859 posts
- 6. DeFi 106 B posts
- 7. Henry Silver N/A
- 8. Jayce 83,2 B posts
- 9. #saturdaymorning 3.139 posts
- 10. #MSIxSTALKER2 6.090 posts
- 11. Good Saturday 36,6 B posts
- 12. #Arcane 305 B posts
- 13. Renji 3.889 posts
- 14. Senior Day 2.945 posts
- 15. Pence 85,7 B posts
- 16. Cavuto N/A
- 17. Fritz 8.846 posts
- 18. Fishers N/A
- 19. Zverev 7.130 posts
- 20. Clyburn 1.093 posts








Something went wrong.
Something went wrong.