
Jihan Yang
@jihanyang13Postdoc@NYU Courant; PhD@HKU; Researcher in Deep Learning, Computer Vision.
Similar User

@denghilbert

@runsen_xu

@frankzydou

@ComWjm

@Running_Zhao

@JiahaoXie3

@siweiyang_ac

@JaminFong

@JingLiu19624459

@EntongSu

@xinntao

@_xwen_

@Evan_THU

@zzk_zhao

@HengshuangZhao
Introducing 𝑽-𝑰𝑹𝑳🤖🌍 LLM-driven AI Agents like Generative Agents and Voyager are super cool, but they are text-only or limited to game engine. Can we ground AI agents in real vision data worldwide to perceive, reason and interact just like what we do in daily life? (1/n)

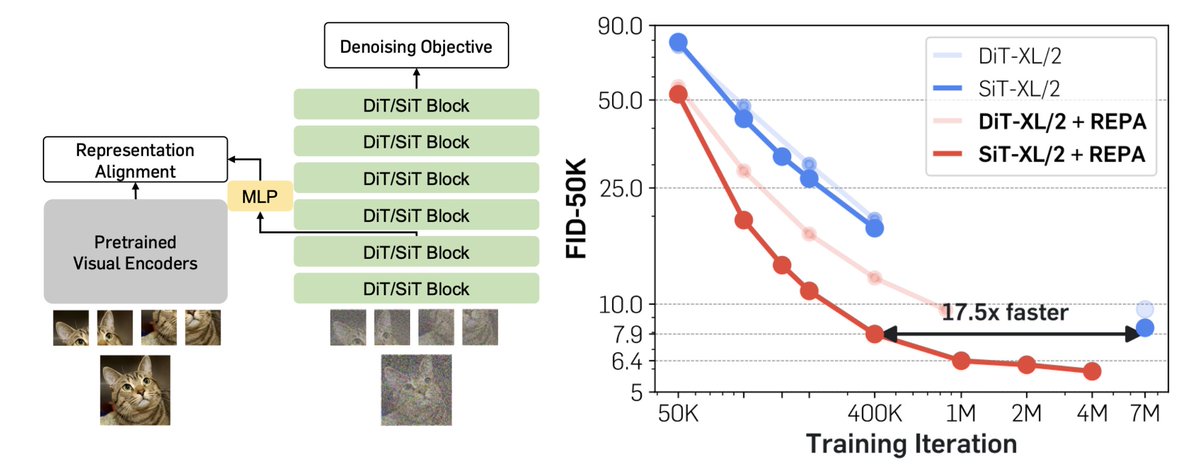
Representation matters. Representation matters. Representation matters, even for generative models. We might've been training our diffusion models the wrong way this whole time. Meet REPA: Training Diffusion Transformers is easier than you think! sihyun.me/REPA/(🧵1/n)
a fun collaboration with the system group at nyu. through sparse all2all comm; dynamic load balancing and large batch hyperparameter scaling rule, now you can finally train your large 3dgs on many gpus🔥without any loss in quality. led by @zhaohexu2001 haoyang & @fred_lu_443


On Scaling Up 3D Gaussian Splatting Training arxiv.org/abs/2406.18533 Project: daohanlu.github.io/scaling-up-3dg… Code (Apache 2.0): github.com/nyu-systems/Gr… => Parallelize training over multiple GPUs. Make sure to checkout the project page, it is awesome! Method ⬇️ 1 | 2

TLDR: We study benchmarks, data, vision, connectors, and recipes (anything other than LLMs in MLLM), and obtain very competitive performance. We hope our project can be a cornerstone for future MLLM research. Data & Model: huggingface.co/nyu-visionx Code: github.com/cambrian-mllm/…
Introducing Cambrian-1, a fully open project from our group at NYU. The world doesn't need another MLLM to rival GPT-4V. Cambrian is unique as a vision-centric exploration & here's why I think it's time to shift focus from scaling LLMs to enhancing visual representations.🧵[1/n]



Cambrian-1 🪼 Through a vision-centric lens, we study every aspect of building Multimodal LLMs except the LLMs themselves. As a byproduct, we achieve superior performance at the 8B, 13B, 34B scales. 📄arxiv.org/abs/2406.16860 🌎cambrian-mllm.github.io 🤗huggingface.co/nyu-visionx
Introducing Cambrian-1, a fully open project from our group at NYU. The world doesn't need another MLLM to rival GPT-4V. Cambrian is unique as a vision-centric exploration & here's why I think it's time to shift focus from scaling LLMs to enhancing visual representations.🧵[1/n]

Introducing Cambrian-1, a fully open project from our group at NYU. The world doesn't need another MLLM to rival GPT-4V. Cambrian is unique as a vision-centric exploration & here's why I think it's time to shift focus from scaling LLMs to enhancing visual representations.🧵[1/n]

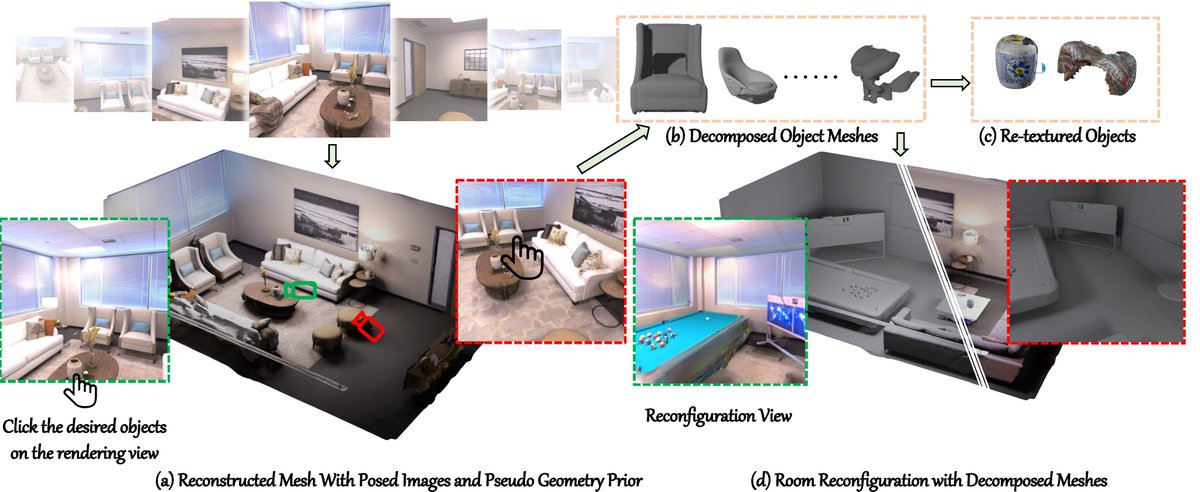
Welcome to check our new CVPR 2024 work, Total-Decom. It can decompose the reconstructed mesh to generate high-quality meshes for individual objects and backgrounds with minimal human annotations. Project Page: cvmi-lab.github.io/Total-Decom/
Thanks for sharing our work. Welcome to check it.
Code released: "Code for SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes" github.com/yihua7/SC-GS

Let’s think about humanoid robots outside carrying the box. How about having the humanoid come out the door, interact with humans, and even dance? Introducing Expressive Whole-Body Control for Humanoid Robots: expressive-humanoid.github.io See how our robot performs rich, diverse,…
Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community. What we…
⚖️ Ethics & privacy We think the discussion shouldn't stop at geographic bias. As developers of new technology, it's important to consider possible misuses of our creations VIRL doesn't capture any previously inaccessible data; it exclusively utilizes preexisting APIs.…

Say hello to VIRL – a platform that grounds AI agents in real-world vision. By combining geospatial data from Google Maps with cutting-edge vision and language models, the embodied AI agents gain the ability to “see”, understand and interact with the physical world🌎. (1/4)
🤖 VIRL 🌎 Grounding Virtual Intelligence In Real Life 🧐How can we embody agents in environments as rich/diverse as those we inhabit, without real hardware & control constraints? 🧐How can we ensure internet-trained vision/language models will translate to real life globally?

The world of embodied Agents needs it's goals, intentions and more importantly a large playground. 🌐 VIRL Virtual Intelligence in Real Life virl-platform.github.io ▶️ How can we embody agents in an environment as rich and diverse as the one we inhabit, without the…












































































United States Trends
- 1. Browns 62,2 B posts
- 2. Jameis 29,1 B posts
- 3. Pam Bondi 205 B posts
- 4. #PITvsCLE 9.022 posts
- 5. #TNFonPrime 4.056 posts
- 6. Russ 33,6 B posts
- 7. Tomlin 9.549 posts
- 8. Fields 48,9 B posts
- 9. Myles Garrett 5.761 posts
- 10. #HereWeGo 10,3 B posts
- 11. Njoku 6.333 posts
- 12. Pickens 6.958 posts
- 13. #DawgPound 5.141 posts
- 14. Arthur Smith 2.294 posts
- 15. Baylor 6.709 posts
- 16. Brandon Miller 5.102 posts
- 17. AFC North 5.154 posts
- 18. #ThePinkprintAnniversary 6.205 posts
- 19. Al Michaels 1.262 posts
- 20. Najee 4.264 posts
Who to follow
-
 youming.deng
youming.deng
@denghilbert -
 Runsen Xu
Runsen Xu
@runsen_xu -
 Zhiyang (Frank) Dou
Zhiyang (Frank) Dou
@frankzydou -
 Junming Wang
Junming Wang
@ComWjm -
 Running Zhao
Running Zhao
@Running_Zhao -
 Jiahao Xie
Jiahao Xie
@JiahaoXie3 -
 Siwei Yang
Siwei Yang
@siweiyang_ac -
 Jiemin Fang
Jiemin Fang
@JaminFong -
 Jing Liu
Jing Liu
@JingLiu19624459 -
 Entong Su
Entong Su
@EntongSu -
 Xintao Wang
Xintao Wang
@xinntao -
 Xin Wen
Xin Wen
@_xwen_ -
 Ling-Hao (Evan) CHEN
Ling-Hao (Evan) CHEN
@Evan_THU -
 Zhongkai Zhao
Zhongkai Zhao
@zzk_zhao -
 Hengshuang Zhao
Hengshuang Zhao
@HengshuangZhao
Something went wrong.
Something went wrong.