
Jon Ander Campos
@jaa_camposMember of Technical Staff @cohere. PhD in Natural Language Processing @IxaGroup. Also interned at @Apple, @AIatMeta, @CNRS and @nyuniversity.
Similar User

@AnderSala

@Hitz_zentroa

@Aitor57

@eagirre

@IxaGroup

@oierldl

@glabaka

@4nderB

@IxaTaldea

@aormazabalo

@liruizhe94

@ItziarGD

@YueDongCS

@ragerri

@ZEYULIU10

Incredibly honoured to see our work recognised as an outstanding paper. @magikarp_tokens dove deep into the dark depths of tokenisation on this one and fished up some very interesting insights. Be sure to catch him at #EMNLP2024 if you're around! 🎣 Thank you @emnlpmeeting ❤️






The state of AI in 2024 -- also featuring some of our recent work on synthetic critiques with @Daniella_yz, @FraserGreenlee, Phil Blunsom, @jaa_campos and @mgalle at @Cohere

🪩The @stateofaireport 2024 has landed! 🪩 Our seventh installment is our biggest and most comprehensive yet, covering everything you *need* to know about research, industry, safety and politics. As ever, here's my director’s cut (+ video tutorial!) 🧵

Concerned about data contamination? We asked the community for known contamination in different datasets and models, and summarized these finding in this report. arxiv.org/pdf/2407.21530


Thank you to all the contributors! As part of the CONDA Workshop, we have created a report with all the contributions. You can find it already available in arxiv: arxiv.org/abs/2407.21530
New work led by @Daniella_yz during her internship at Cohere 🚀 In the paper we show that synthetic critiques are not only helpful but also more efficient than vanilla preference pairs when training reward models.

Beyond their use in assisting human evaluation (e.g. CriticGPT), can critiques directly enhance preference learning? During my @Cohere internship, we explored using synthetic critiques from large language models to improve reward models. 📑Preprint: arxiv.org/abs/2405.20850


Understanding and Mitigating Language Confusion 😵💫 User: ¿De qué trata nuestro artículo? LLM: We analyze one of LLMs’ most jarring errors: their failure to generate text in the user’s desired language. 📑 arxiv.org/abs/2406.20052 💻 github.com/for-ai/languag…


Our paper about reliably finding under-trained or 'glitch' tokens is out! We find up to thousands of these tokens in some #LLMs, and give examples for most popular models. arxiv.org/abs/2405.05417 More in 🧵

Can you imagine having all the evidence of data contamination gathered in one place? 📢As part of the CONDA workshop, we present the Data Contamination Evidence Collection, a shared task on reporting contamination. Available as a @huggingface space: hf.co/spaces/CONDA-W…


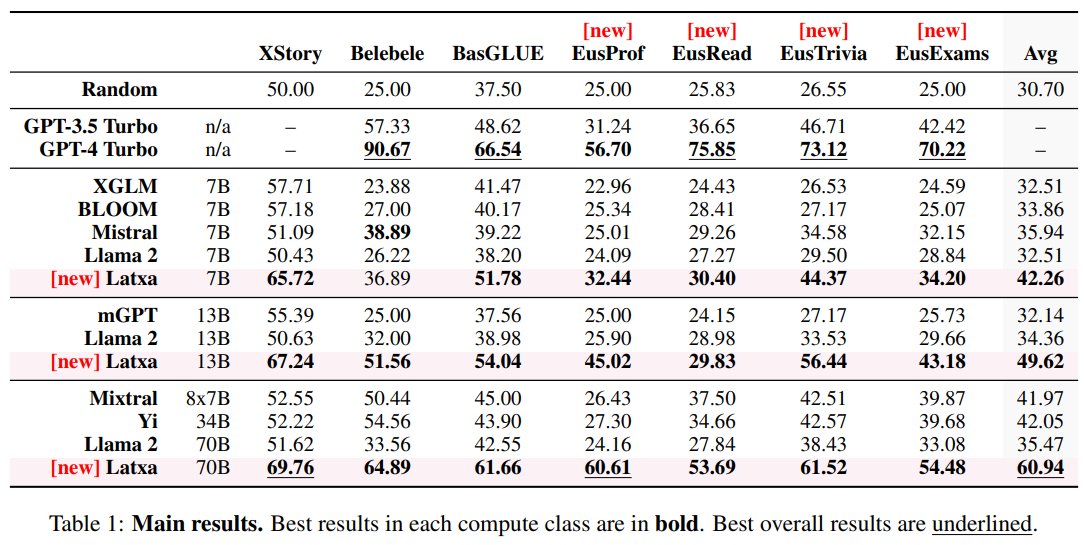
In our new paper, we introduce Latxa, a family of LLMs for Basque from 7 to 70B parameters that outperform open models and GPT3.5. Models and datasets @huggingface hf.co/collections/Hi… Code: github.com/hitz-zentroa/l… Blog: hitz.eus/en/node/343 Paper: arxiv.org/abs/2403.20266
Command R+ is now at position 6 on the arena leaderboard! 🚀 It's wonderful to see such positive reception! 🤩 If you enjoyed the model, you can explore the RAG and Tool Use capabilities at coral.cohere.com or download the weights from 🤗


Super happy and proud to share that ⌘R+ is out! 🚀 Working for this launch with such an amazing team has been an incredible journey. Try it out at coral.cohere.com or download the weights at 🤗 and play with it on your machine!

⌘R+ Welcoming Command R+, our latest model focused on scalability, RAG, and Tool Use. Like last time, we're releasing the weights for research use, we hope they're useful to everyone! txt.cohere.com/command-r-plus…
Uncontaminated test sets and methods for detecting contamination are invaluable these days! If you're working on related topics please consider submitting to the CONDA 🐍 workshop at ACL conda-workshop.github.io
Another pro-tip for doing really well on evals: just train on the test set. Literally just do it, you have the examples right there. Ie. here's [redacted] on HumanEval.

Excited to share that our paper "Do multilingual language models think better in English?" has been accepted at the NAACL 2024 main conference! 🎉🎉🎉 Thanks to all coauthors! @gazkune @Aitor57 @oierldl @artetxem @IxaGroup @Hitz_zentroa
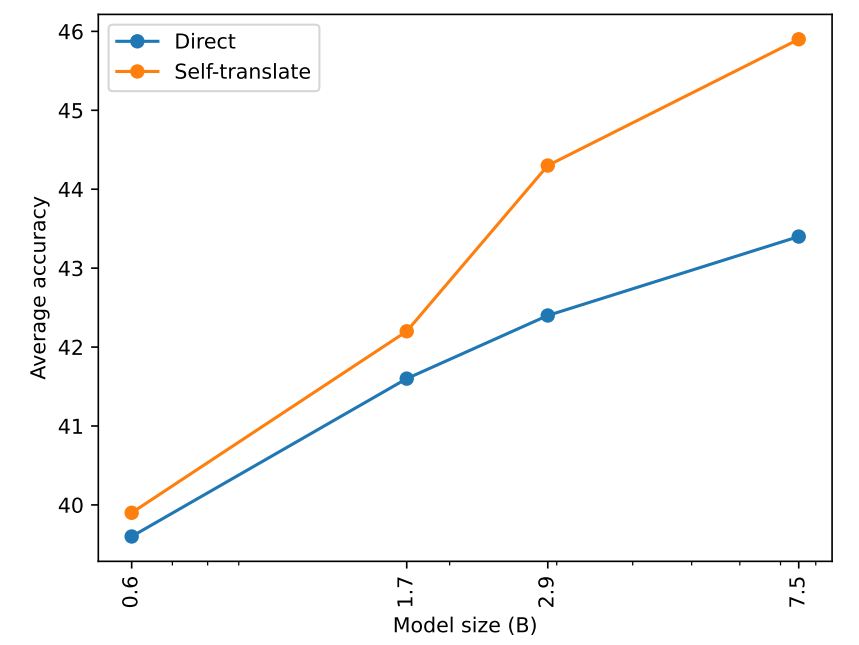
Do multilingual language models think better in English? 🤔 Yes, they do! We show that using an LLM to translate its input into English and performing the task over the translated input works better than using the original non-English input! 😯 arxiv.org/abs/2308.01223
🚀 Very excited to share that Command-R is out! 🚀 Command-R is multilingual, capable of handling long contexts, and powered by RAG and Tool Use! You can try it out at coral.cohere.com or simply download the weights and run it yourself 🤩! huggingface.co/CohereForAI/c4…
⌘-R Introducing Command-R, a model focused on scalability, RAG, and Tool Use. We've also released the weights for research use, we hope they're useful to the community! txt.cohere.com/command-r/


Today, we’re launching Aya, a new open-source, massively multilingual LLM & dataset to help support under-represented languages. Aya outperforms existing open-source models and covers 101 different languages – more than double covered by previous models. cohere.com/research/aya

👋 Check out our new paper and benchmark: REVEAL, a dataset with step-by-step correctness labels for chain-of-thought reasoning in open-domain QA 🧵🧵🧵 arxiv.org/abs/2402.00559 huggingface.co/datasets/googl…


This seems like a great workshop! I hope and expect that analyzing the potential of data conamination will become a standard part of any rigorous eval. Just like model cards, impact statements etc. are part of high qulity papers. Excited that @jaa_campos is organizing this.
Data contamination in large scale models - an issue acknowledged by many that hasn't been widely discussed yet. 🚨 We are organizing CONDA, the first Workshop on Data Contamination that will be co-located with ACL24 (Aug16)🚨 Please consider submitting: conda-workshop.github.io
Data contamination in large scale models - an issue acknowledged by many that hasn't been widely discussed yet. 🚨 We are organizing CONDA, the first Workshop on Data Contamination that will be co-located with ACL24 (Aug16)🚨 Please consider submitting: conda-workshop.github.io
📢 Excited to announce that our Workshop on Data Contamination (CONDA) will be co-located with ACL24 in Bangkok, Thailand on Aug. 16. We are looking forward to seeing you there! Check out the CFP and more information here: conda-workshop.github.io
Pozarren aukezten dugu Latxa eredu irekien familia, euskarazko hizkuntza eredurik handiena eta hoberena duena. @Meta-ren Llama ereduetan oinarritutakoa eta 7-70 mila miloi parametro arteko ereduak biltzen ditu, Llama-2 delako lizentzia irekia dute. 1/n


















































































United States Trends
- 1. Cowboys 50,4 B posts
- 2. Bears 75,5 B posts
- 3. Chiefs 67,5 B posts
- 4. Panthers 42,3 B posts
- 5. Turpin 11,8 B posts
- 6. Texans 28,5 B posts
- 7. Commanders 56,7 B posts
- 8. Vikings 44,1 B posts
- 9. Caleb 35,2 B posts
- 10. Bryce Young 8.575 posts
- 11. #DALvsWAS 13,2 B posts
- 12. Eberflus 8.510 posts
- 13. Titans 46,2 B posts
- 14. #skol 5.621 posts
- 15. Jayden Daniels 7.751 posts
- 16. #KeepPounding 3.478 posts
- 17. Colts 30 B posts
- 18. CJ Stroud 4.371 posts
- 19. Terry 31,9 B posts
- 20. #RaiseHail 8.874 posts
Who to follow
-
 Ander Salaberria
Ander Salaberria
@AnderSala -
 HiTZ zentroa (UPV/EHU)
HiTZ zentroa (UPV/EHU)
@Hitz_zentroa -
 AitorSoroa
AitorSoroa
@Aitor57 -
 Eneko Agirre
Eneko Agirre
@eagirre -
 Ixa Group
Ixa Group
@IxaGroup -
 Oier Lpz de Lacalle
Oier Lpz de Lacalle
@oierldl -
 Gorka Labaka
Gorka Labaka
@glabaka -
 Ander Barrena Madinabeitia
Ander Barrena Madinabeitia
@4nderB -
 Ixa taldea
Ixa taldea
@IxaTaldea -
 Aitor Ormazabal
Aitor Ormazabal
@aormazabalo -
 Ruizhe Li
Ruizhe Li
@liruizhe94 -
 Itziar Gonzalez-Dios
Itziar Gonzalez-Dios
@ItziarGD -
 Yue Dong @ NeurIPS 2023
Yue Dong @ NeurIPS 2023
@YueDongCS -
 Rodrigo Agerri
Rodrigo Agerri
@ragerri -
 Leo Liu
Leo Liu
@ZEYULIU10
Something went wrong.
Something went wrong.