
Thomas Hummel
@hummelth_Currently research intern @SonyAI_global🇨🇭| PhD student @uni_tue within #IMPRSIS | Interested in multimodal learning and video understanding
Similar User

@zeynepakata

@massi_manc

@_elinguyen

@SchulzAuguste

@KatrinRenz

@thwiedemer

@mkirchhof_

@ferjadnaeem

@elifakata

@ShyamgopalKart1

@Matewhs

@a_rubique

@jackhb98

@m_tangemann

@YumengLi_007

The list of #ECCV2024 Outstanding Reviewers! Thank you for your service 🫡 eccv.ecva.net/Conferences/20…

Juggling my PhD work and reviewing isn't always easy, but super happy to be recognized for this!

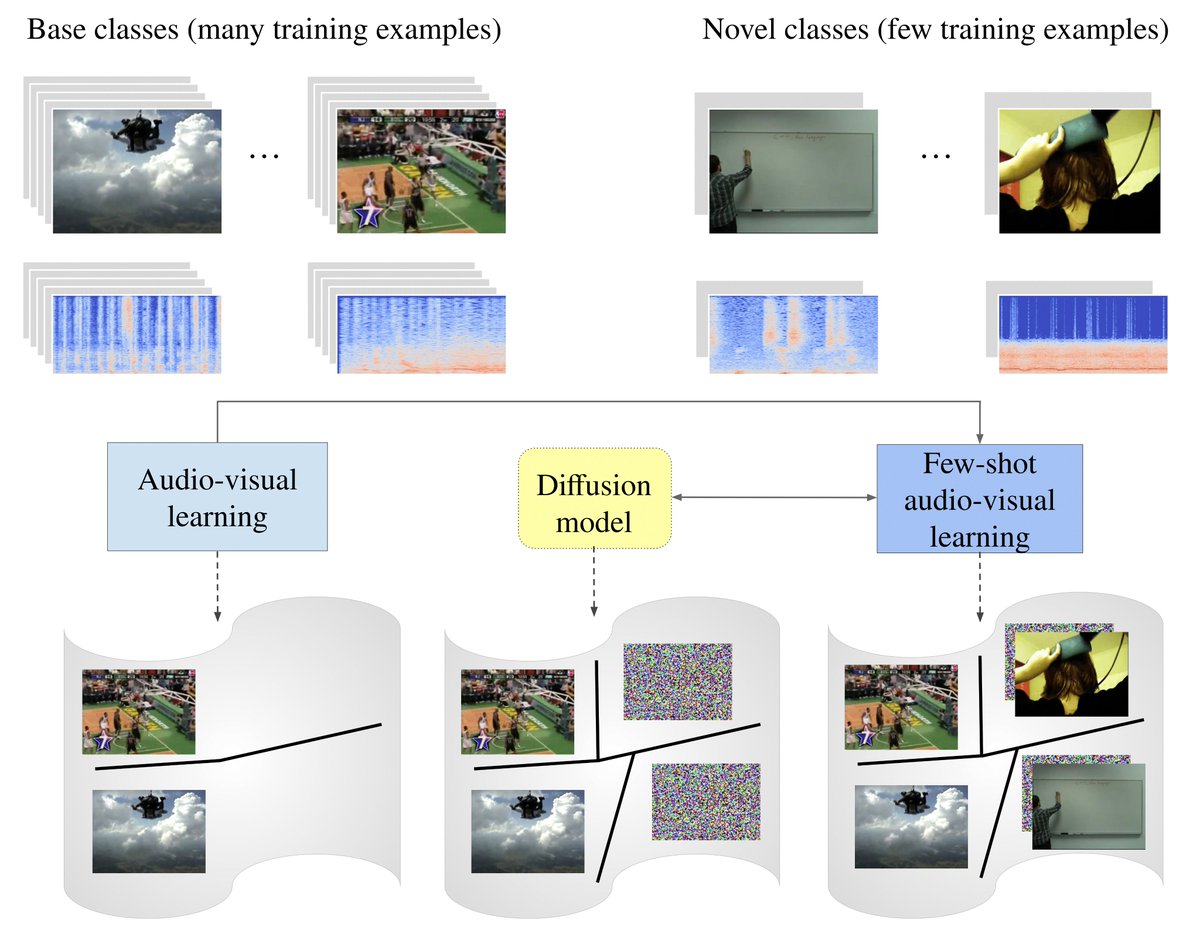
Come talk to me at our poster today at #GCPR2023 to dive into the details 🚀 In this work, we propose a novel few-shot audio-visual classification benchmark and a text-to-feature diffusion framework to augment the training!

At #GCPR23 today? Then come to our poster on "Text-to-feature diffusion for audio-visual few-shot learning" by @MerceaOtniel, @hummelth_, A. Sophia Koepke and @zeynepakata! Find out more about our work here: t.ly/xjX34
Interested in XAI? Do not miss the Explainability in ML workshop! It will take place March 28-29 in Tübingen (Germany) and will feature talks from prominent researchers in the field. Check the program here eml-unitue.de/eml-workshop, and register in advance: few spots remaining!

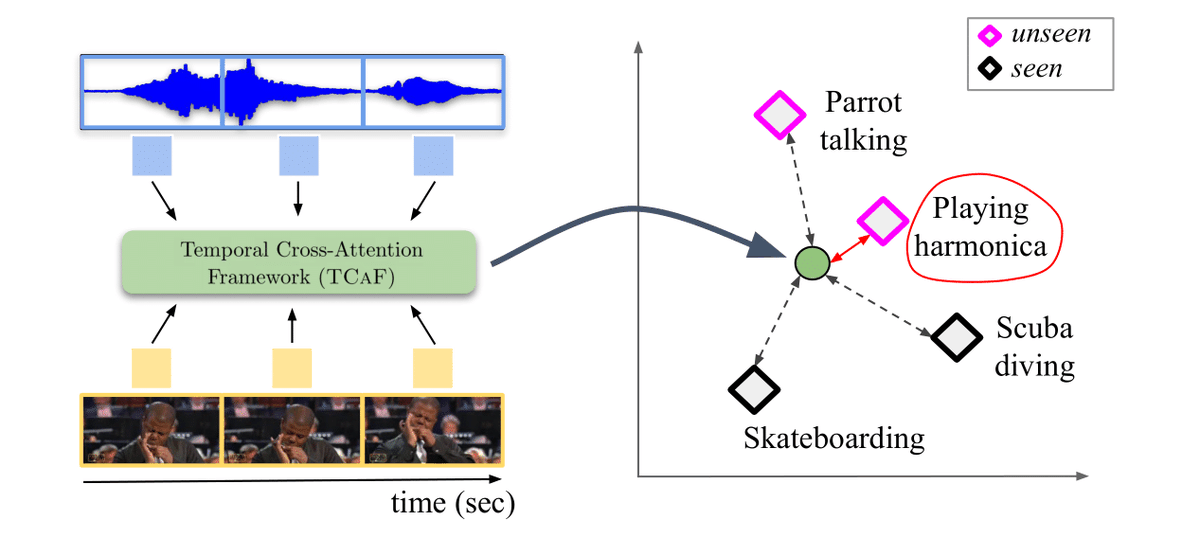
Come stop by our poster this afternoon (1.B-101) if you want to talk with us about audio-visual ZSL! We show that our temporal and cross-modal constrained attention mechanism outperforms previous work on three audio-visual GZSL benchmarks! #ECCV2022
🗓️Sess 6 | 101, 25/10 | afternoon “Temporal and cross-modal attention for audio-visual zero-shot learning” @MerceaOtniel* @hummelth_*, A. S. Koepke, @zeynepakata We leverage temporal context for better and improved audio-visual zero-shot learning! Blog bit.ly/3eWfTIg





















































































United States Trends
- 1. Mike Rogers 144 B posts
- 2. #FridayVibes 7.322 posts
- 3. Good Friday 66 B posts
- 4. $MAD 5.621 posts
- 5. CONGRATULATIONS JIMIN 324 B posts
- 6. Happy Friyay 2.784 posts
- 7. Pam Bondi 326 B posts
- 8. Jason Kelce 1.894 posts
- 9. #FridayMotivation 12,1 B posts
- 10. McCabe 26,4 B posts
- 11. #FursuitFriday 12,6 B posts
- 12. #FridayFeeling 3.691 posts
- 13. #BOYCOTT143ENT 8.375 posts
- 14. Chris Brown 31,9 B posts
- 15. Randle 7.569 posts
- 16. Dan Scavino 1.766 posts
- 17. President John F. Kennedy 8.702 posts
- 18. Jameis 73,2 B posts
- 19. Kang 36,2 B posts
- 20. Finally Friday 3.470 posts
Who to follow
-
 Zeynep Akata
Zeynep Akata
@zeynepakata -
 Massimiliano Mancini
Massimiliano Mancini
@massi_manc -
 Elisa Nguyen
Elisa Nguyen
@_elinguyen -
 Auguste Schulz
Auguste Schulz
@SchulzAuguste -
 Katrin Renz
Katrin Renz
@KatrinRenz -
 Thaddäus Wiedemer @ ICLR 2024
Thaddäus Wiedemer @ ICLR 2024
@thwiedemer -
 Michael Kirchhof
Michael Kirchhof
@mkirchhof_ -
 Ferjad Naeem
Ferjad Naeem
@ferjadnaeem -
 Elif Akata
Elif Akata
@elifakata -
 Shyamgopal Karthik
Shyamgopal Karthik
@ShyamgopalKart1 -
 Shweta Mahajan
Shweta Mahajan
@Matewhs -
 Alexander Rubinstein
Alexander Rubinstein
@a_rubique -
 Jack Brady
Jack Brady
@jackhb98 -
 Matthias Tangemann
Matthias Tangemann
@m_tangemann -
 Yumeng Li
Yumeng Li
@YumengLi_007
Something went wrong.
Something went wrong.