
Prompt
@engineerrpromptCreator of localGPT | Building something cool! Generative AI, Tech, Arts, Life!
This is so true. Agents have a long way to go to get consistent performance. My work flow usually involves hard-coded/hand crafted states along with agents.

The biggest blocker for AI agents? It is performance quality, BY FAR For all the talk of cost, latency, safety... the fact is, most people are still just struggling to get agents to work 🤷♀️ Full survey here: langchain.com/stateofaiagents

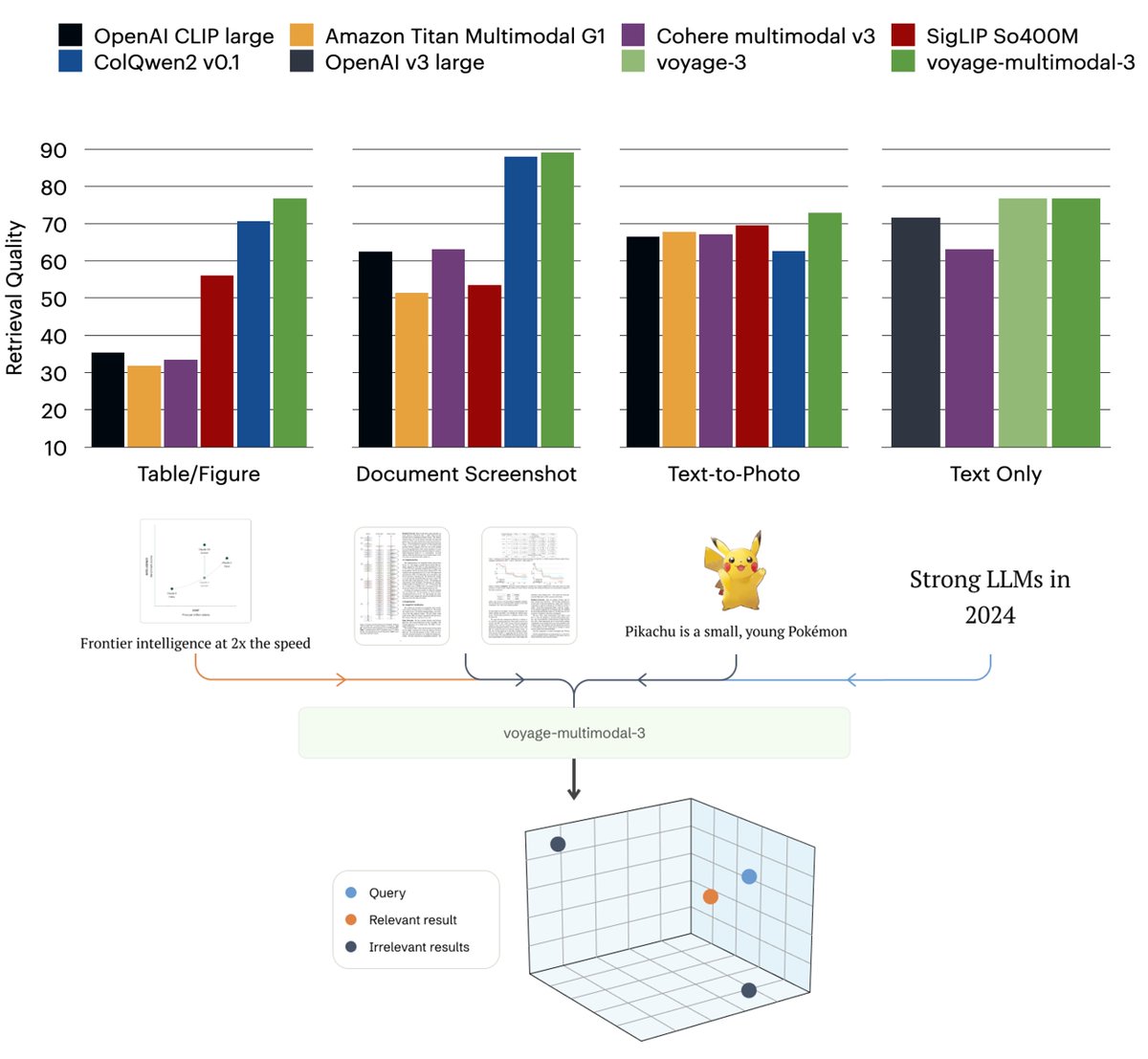
It's great to see the shift towards visual RAG with the new embedding model from @voyageAi The OG was the intro of ColPali. If you are looking for a complete local solution for visual RAG, checkout localgpt-vision, which builds on top of colpali/qwenpali github.com/PromtEngineer/…


Qwen-2.5-32B-Instruct from @Alibaba_Qwen is the best in class open weight model and trending on @huggingface How is it building webapps with it? I put it to the test in my new video. youtu.be/KYvVl0UT1Sk
Updates to localgpt-vision coming soon. It's built on top of byaldi and the fantastic work on VLM community for vision based end to end multimodal RAG.

🐭byaldi v0.0.7 is out! It's been a while, so time for a re-introduction: 🐭byaldi is a library that makes it ridiculously easy to use models with complex mechanisms, so you don't have to understand what a "late-interaction multi-modal VLM-based retrievers" * is before you can…
Qwen models are one of the best open weight models and are often missing from comparisons when other frontier labs release new models ( that should tell you a lot). They just released the Qwen2.5 32B coding model. Check it out here. qwenlm.github.io/blog/qwen2.5-c…
This is so true. The key to a good RAG system is understanding your own data. It's something folks shy away from. GenAI is not magic. Spend time understanding your data and the use case, and then implement a custom RAG system if you need one.

Learn how to use the multimodal llama 3.2 from @AIatMeta for building a vision based RAG system thanks to the recent integration with @ollama Here is a video to get you started youtu.be/45LJT-bt500
Biggest mistakes i have seen in RAG systems. When "chunking your documents" for RAG, make sure you are chunking them on "tokens," not "characters". You are welcome 😊
What is happening! Never a dull moment. @Microsoft released OmniParser "OmniParser is a general screen parsing tool, which interprets/converts UI screenshot to structured format, to improve existing LLM based UI agent."

Microsoft just dropped OmniParser model on @huggingface, so casually! 😂 “OmniParser is a general screen parsing tool, which interprets/converts UI screenshot to structured format, to improve existing LLM based UI agent.” 🔥 huggingface.co/microsoft/Omni…
Sometimes, I do want to pull my hair when I don't "feel the AGI" while coding!!!

This is an interesting idea and definitely a much needed tool. Not only for ownership but also for figuring out what is real vs. synthetic!

Today, we’re open-sourcing our SynthID text watermarking tool through an updated Responsible Generative AI Toolkit. Available freely to developers and businesses, it will help them identify their AI-generated content. 🔍 Find out more → goo.gle/40apGQh
You can read through the blog posts to learn what @AnthropicAI released or can just watch my video with a quick summary of what was released today. This will make me happy 😊 youtu.be/lnWrF-xcwq0

We believe these developments will open up new possibilities for how you work with Claude, and we look forward to seeing what you'll create. Read the updates in full: anthropic.com/news/3-5-model…
Hard to say what is real anymore! You can run this SOTA Video generation model IF you have access to at least 4 H100 GPUs but hopefully we will have smaller models soon.

Wow, now Claude can use your computer!
We believe these developments will open up new possibilities for how you work with Claude, and we look forward to seeing what you'll create. Read the updates in full: anthropic.com/news/3-5-model…

Friday releases is a new thing now :) A multimodal model from @AIatMeta Text/Speech input and text/Speech output! Here goes my weekend ;)

Today we released Meta Spirit LM — our first open source multimodal language model that freely mixes text and speech. Many existing AI voice experiences today use ASR to techniques to process speech before synthesizing with an LLM to generate text — but these approaches…
Curious who is actively using the @OpenAI GPT-4o advanced voice on daily basis? What is your use case? I probably use it once or twice a week at most, that also just for looking up some info, not conversations.
The Age of SLMs is upon us! Great to see these smaller models that can be great for task specific finetunes.



































































































United States Trends
- 1. Ravens 81,7 B posts
- 2. Steelers 114 B posts
- 3. Falcons 13,9 B posts
- 4. Paige 16,3 B posts
- 5. Bears 114 B posts
- 6. Bo Nix 6.678 posts
- 7. Packers 74,3 B posts
- 8. Bills 102 B posts
- 9. Jets 57,1 B posts
- 10. WWIII 53,6 B posts
- 11. Lamar 32,2 B posts
- 12. Broncos 21,2 B posts
- 13. Jennings 7.436 posts
- 14. Mahomes 19,7 B posts
- 15. Josh Allen 7.728 posts
- 16. Randle 11,3 B posts
- 17. Worthy 48,3 B posts
- 18. #HereWeGo 20,1 B posts
- 19. #GoPackGo 10 B posts
- 20. Lions 95,6 B posts
Something went wrong.
Something went wrong.