
Similar User

@SamueleCornell
@ArxivSound

@ISCAInterspeech

@SpeechBrain1

@ButSpeech

@shinjiw_at_cmu

@mhnt1580

@neilzegh

@edfonseca_

@mirco_ravanelli

@alphacep

@WavLab

@rdesh26

@erogol

@hbredin
After spending some hours on F5, I found passion to finalize this small post. I'm telling this for quite some time already though. alphacephei.com/nsh/2024/10/18…
Awesome new project: Whisper Turbo MLX by Josef Albers. A clean, single file (< 250 lines), and blazing fast implementation of Whisper Turbo in MLX:

190ms TTFB 👀

Today we’re introducing our latest Text-To-Speech model, Play 3.0 mini. It’s faster, more accurate, handles multiple languages, supports streaming from LLMs, and it’s more cost-efficient than ever before. Try it out here: play.ht/playground/?ut…

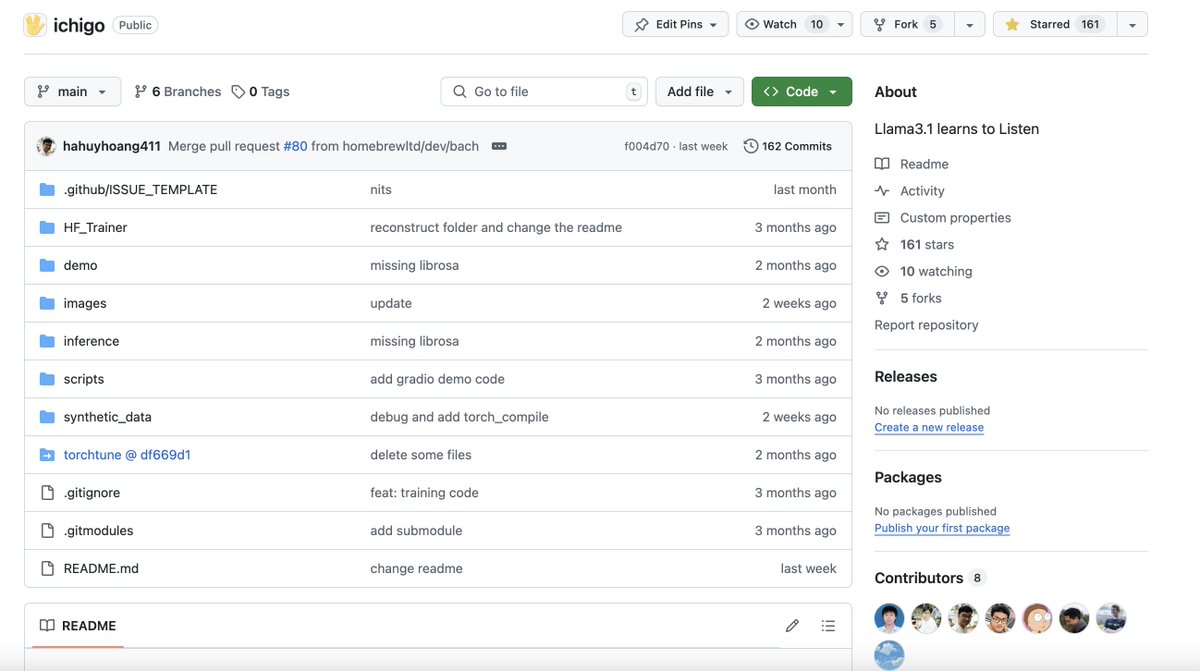
Inspired by the @AIatMeta's Chameleon and Llama Herd papers, llama3-s (Ichigo) is an early-fusion, audio and text, multimodal model. We're experimenting with this research entirely in the open, with an open-source codebase, open data, and open weights. 2/10
3 steps to run @huggingface "Parler TTS" AI Voice on your local machine. New tutorial video out now 😊! My step-by-step technical tutorial is now available on my "Thorsten-Voice" youtube channel. youtu.be/1X2LxAGn9tU

🍏 Apple ML research in Paris has multiple open internship positions!🍎 We are looking for Ph.D. students interested in generative modeling, optimization, large-scale learning or uncertainty quantification, with applications to challenging scientific problems. Details below 👇
I’ll be presenting a deep dive into how Moshi works at the next NLP Meetup in Paris, this Wednesday the 9th at 7pm. Register if you want to attend ! 🧩🔎🟢 meetup.com/fr-FR/paris-nl…
impressive

🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date. Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in…
👀

Under-appreciated that Moshi (by @kyutai_labs) is a big simplification over more traditional speech-to-speech pipelines. It's really just two models: - A speech encoder/decoder (like EnCodec) - An LLM (trained to input and output speech tokens) Traditionally building something…
``MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages,'' Marco Gaido, Sara Papi, Luisa Bentivogli, Alessio Brutti, Mauro Cettolo, Roberto Gretter, Marco Matassoni, Mohamed Nabih, Matteo Negri, ift.tt/visfyaK
Today I let my team know that I'll be leaving Rabbit. I'm immensely grateful to have worked with such a driven team. We made strides in pushing the boundaries of AI in everyday life, and we consistently shipped at high velocity with excellent partners. I want to thank my team…
My key takeaways from the first 17 pages of the Moshi technical report, which details the models and architecture (a thread):

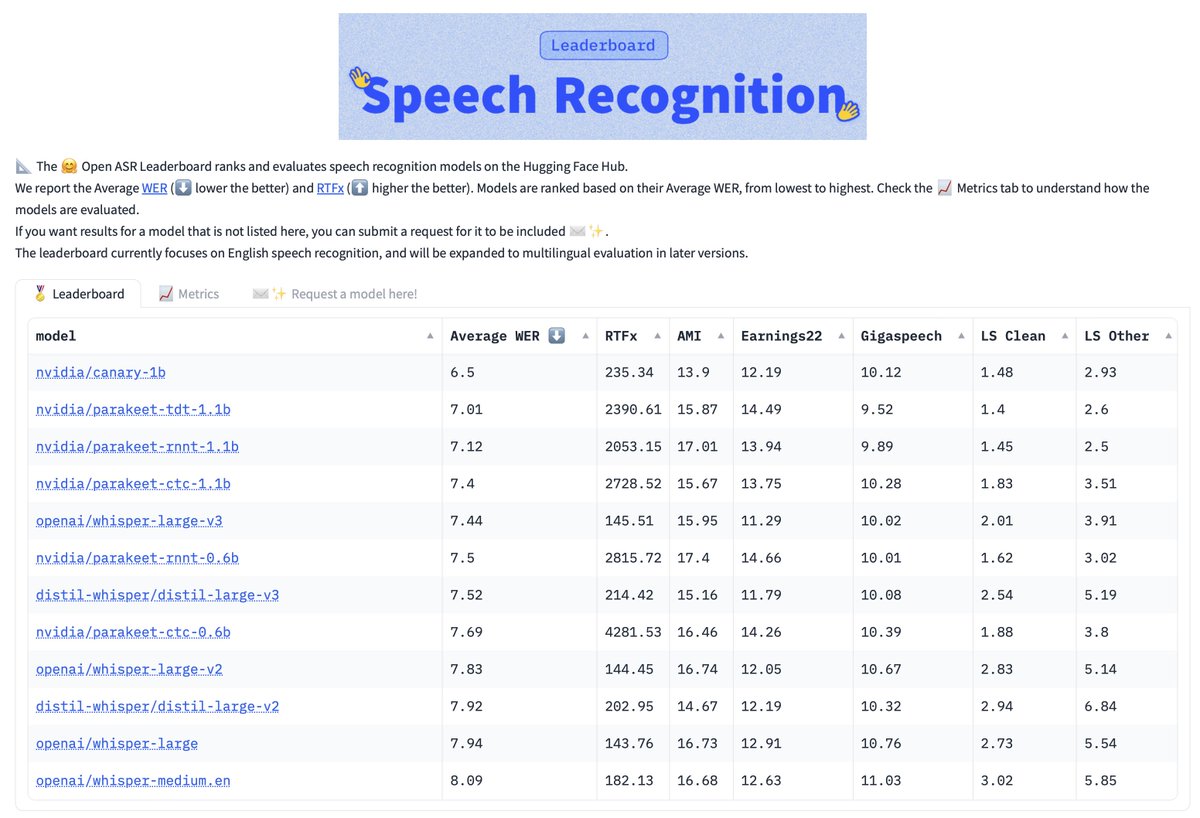
Behold: NeMo ASR now runs easily 2000-6000 faster than realtime (RTFx) on @nvidia GPU. We developed a series of optimizations to make RNN-T, TDT, and CTC models go brrrrrrr!🔥 In addition to topping the HF Open ASR Leaderboard they are now fast and cheap. All in pure PyTorch!

New paper: efficient multimodal machine translation training (EMMeTT). It's a milestone on our road to providing everybody with multimodal foundation model training infra. Result: single multimodal model handles both speech and text translation without loss of NMT performance.

I'm excited to share that Pindo Voice AI is now in beta! After sending 120M+ texts, we found that SMS & USSD are hard to access for many in Africa. @pindoio helps African businesses engage customers in their native languages. Join waitlist - pindo.ai/waitlist
We're releasing updated versions of Command R (35B) and Command R+ (104B). Command R (now with GQA) in particular should perform significantly better multilingually. 🤗 model weights: - ⌘ R 08-2024: huggingface.co/CohereForAI/c4… - ⌘ R+ 08-2024: huggingface.co/CohereForAI/c4…

We’re releasing improved versions of the Command R series, our enterprise-grade AI models optimized for business use cases. You can access them on our API, @awscloud Sagemaker, and additional platforms soon. cohere.com/blog/command-s…

Hi all, This is the third call for papers about the SynData4GenAI workshop. Good news! While the submission data was originally due on June 18th, we'll extend it to June 24th. Please submit your papers at syndata4genai.org We look forward to your submissions!
This is the second call for papers about the SynData4GenAI workshop. Please mark your calendar for the submission due date (June 18, 2024, after the Interspeech acceptance notification)! I'm also pasting the CFP.



















































































































United States Trends
- 1. Mike 1,81 Mn posts
- 2. Serrano 242 B posts
- 3. Canelo 16,9 B posts
- 4. #NetflixFight 74 B posts
- 5. Father Time 10,6 B posts
- 6. Logan 78,7 B posts
- 7. #netflixcrash 16,4 B posts
- 8. VANDER 5.197 posts
- 9. He's 58 27,6 B posts
- 10. Rosie Perez 15,1 B posts
- 11. Boxing 305 B posts
- 12. #arcane2spoilers N/A
- 13. ROBBED 101 B posts
- 14. Shaq 16,3 B posts
- 15. #buffering 11,1 B posts
- 16. My Netflix 83,8 B posts
- 17. Tori Kelly 5.355 posts
- 18. Roy Jones N/A
- 19. Ramos 69,3 B posts
- 20. Muhammad Ali 19,4 B posts
Who to follow
-
 Samuele Cornell
Samuele Cornell
@SamueleCornell -
 arXiv Sound
arXiv Sound
@ArxivSound -
 INTERSPEECH 2025
INTERSPEECH 2025
@ISCAInterspeech -
 SpeechBrain
SpeechBrain
@SpeechBrain1 -
 BUT Speech
BUT Speech
@ButSpeech -
 Shinji Watanabe
Shinji Watanabe
@shinjiw_at_cmu -
 Wei-Ning Hsu
Wei-Ning Hsu
@mhnt1580 -
 Neil Zeghidour
Neil Zeghidour
@neilzegh -
 Eduardo Fonseca
Eduardo Fonseca
@edfonseca_ -
 Mirco Ravanelli
Mirco Ravanelli
@mirco_ravanelli -
 AlphaCephei
AlphaCephei
@alphacep -
 WAVLab | @CarnegieMellon
WAVLab | @CarnegieMellon
@WavLab -
 Desh Raj
Desh Raj
@rdesh26 -
 erogol
erogol
@erogol -
 Hervé "pyannote" Bredin
Hervé "pyannote" Bredin
@hbredin
Something went wrong.
Something went wrong.