
Jaerin Lee
@_ironjr_Yet another AI engineer. @ Computer Vision Lab, Seoul National University. Research: Gaussian splatting, diffusion model, grokking
📣📣📣 We are excited to announce our new paper, “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”! 🤩 Reinterpreting ML optimization processes as control systems with gradients acting as signals, we accelerate the #grokking phenomenon up to X50, making a step…


some thoughts on the grokfast paper, which has some fun theory + nice results but i suspect is maybe fluffing up a simpler thing that would also work

like a somewhat similar thing you could test is just using bigger batches/gradient accumulation. would’ve liked to see that experiment, their “slow-moving only” ablation doesn’t really address whether the issue is just due to memorization capacity for each batch
🚨 #StreamMultiDiffusion now supports #StableDiffusion3. Public demo's uploaded. 🤩 Try now at @huggingface 🤗 Space 👉 huggingface.co/spaces/ironjr/… Amazed at #SD3 but bored of single text-to-image generation? Try out our demo by drawing with brushes 🖌️ that paints multiple meanings…
Fast multi-prompt arbitrary-sized generation @gradio demo with #StableDiffusion3... Almost done. Generating 2560x1024 images from five regional prompts under 30 sec.

Thanks for trying Grokfast and sharing the progress! I will also try for this setup, too.

I trained a 46M LLM for 260 epochs on wikitext using [@_ironjr_](x.com/_ironjr_) et al.'s grokfast algorithm. (1/9)


This is truly groundbreaking.
📣📣📣 We are excited to announce our new paper, “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”! 🤩 Reinterpreting ML optimization processes as control systems with gradients acting as signals, we accelerate the #grokking phenomenon up to X50, making a step…
Oh, sorry for mistaking your question. tl;dr: I am very open to other types of gradient filters that can have smooth transitions like MA/EMA or can have sharp cutoffs like traditional FIR filters. However, in my short experiences, I couldn't find a better sharp-transition…




I’m stunned at the fact they thought to try this Modeling gradients as signals? Wtf? This seems like a bigger deal than their application, was there prior art?

Grokked weights are much closer to random init in weight space than where models are ending up today. Makes some sense intuitively but pretty cool to see.
In our discussion section, we show that our Grokfast algorithm leads to alternative generalization states in the parameter space with smaller variance and much shorter distance from the initial weights than those reached by the baseline. 🧵 [8/9]
Fast multi-prompt arbitrary-sized generation @gradio demo with #StableDiffusion3... Almost done. Generating 2560x1024 images from five regional prompts under 30 sec.
🔥🔥 StreamMultiDiffusion now supports Stable Diffusion 3. 👉 github.com/ironjr/StreamM… Enabling super fast multiple region-based text-to-image generation by merging FlashDiffusion and StreamMultiDiffusion framework. @huggingface Space demo coming very soon.…


Grokking now reliable
📣📣📣 We are excited to announce our new paper, “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”! 🤩 Reinterpreting ML optimization processes as control systems with gradients acting as signals, we accelerate the #grokking phenomenon up to X50, making a step…
I just have tried. Seems like it can do inpainting with #SD3 from multiple masked text prompts in 5 sec (1024x1024). The code is uploaded 👉 github.com/ironjr/StreamM…


If you care about generalization to unseen data, throw an exponential moving average in your gradient descent. You’ll converge 3× slower—but grok 50× faster.
In our discussion section, we show that our Grokfast algorithm leads to alternative generalization states in the parameter space with smaller variance and much shorter distance from the initial weights than those reached by the baseline. 🧵 [8/9]

Explore the phenomenon of grokking and how the Grokfast algorithm accelerates generalization in neural networks by 50x. Learn the technical details and see how it can speed up your training. Read the full article here: wandb.ai/byyoung3/mlnew…

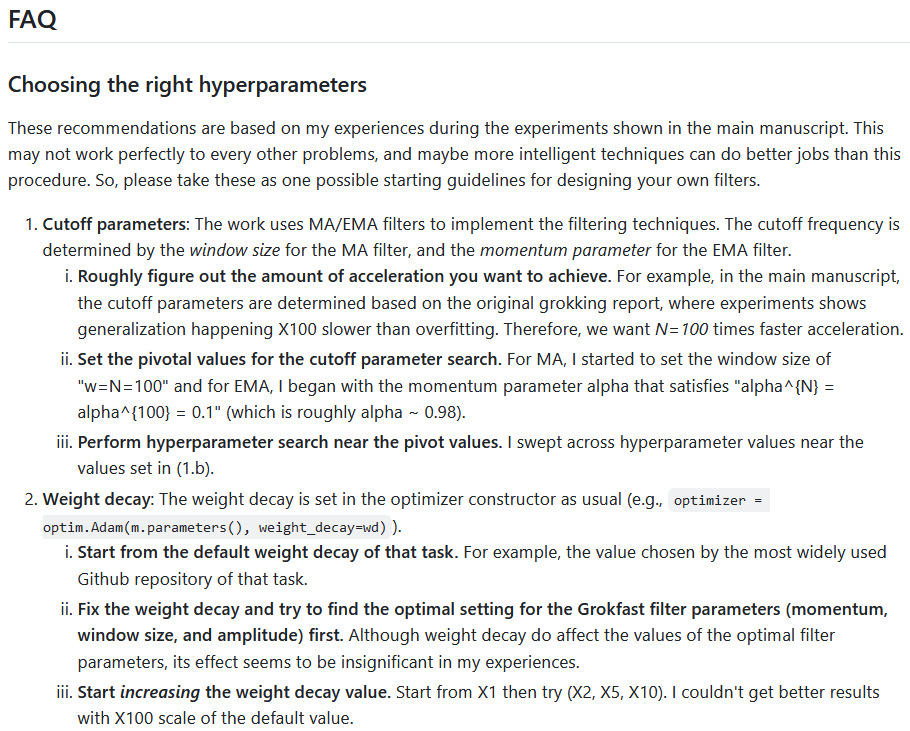
I just updated the readme of the main repository of #Grokfast with hyperparameter setup guidelines. github.com/ironjr/grokfast
How do you draw the boundary between the fast-varying, high frequency component and slow-varying, low frequency component? Does your LPF apply an arbitrary cutoff? Could you make it a sliding scale instead, where you boost the lowest frequencies the most and highest the least?
Thanks for the acknowledgement! Demonstrating with windowed/exponential moving average, the most simplest form of LPF, Grokfast paper is just a proof-of-concept of augmenting optimizers with signal filters to modulate the generalization process. We have showed that MA/EMA…



This is a really good paper! My main question is: there's been a lot of work using FFTs to try to get access to frequency domain information, be it here, or in attention in general, etc. I've not seen anybody try a fast wavelet transform, though. It seems to me that the FWT…































































































United States Trends
- 1. Spotify 2,81 Mn posts
- 2. Snape 4.634 posts
- 3. Pete 929 B posts
- 4. CEOs 31,6 B posts
- 5. Mbappe 171 B posts
- 6. $EMT 4.069 posts
- 7. #EarthMeta 1.655 posts
- 8. Arsenal 425 B posts
- 9. $HAWK 6.862 posts
- 10. Hawk Tuah 25,3 B posts
- 11. United Healthcare 120 B posts
- 12. Brian Thompson 166 B posts
- 13. Preemptive 36,7 B posts
- 14. UHC CEO 10,4 B posts
- 15. Sister Jean N/A
- 16. Citibike 12,2 B posts
- 17. Alan Rickman N/A
- 18. Anthony Fauci 33,1 B posts
- 19. Chipotle 9.020 posts
- 20. Team USA 6.783 posts
Something went wrong.
Something went wrong.