
Yuanbo Yang
@YuanboYang60742Master's student @ZJU_China | Exploring 3D Vision & Generative Models 🌐

全文背诵

The best way to teach people critical thinking is to teach them to write

Open-source ftw. Flux Dev LoRA by @pathmayur (AKA MindlyWorks!) DimensionX LoRA by @an_epsilon0 ComfyUI Implementation by @Kijaidesign
So crazy

DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion Wenqiang Sun, Shuo Chen, Fangfu Liu, Zilong Chen, Yueqi Duan, Jun Zhang, Yikai Wang tl;dr: decouple the temporal and spatial factors in video diffusion arxiv.org/pdf/2411.04928





My naive and personal understanding of Computer Vision Research(keep learning and updating)

Very ambitious project 💪
GenXD: Generating Any 3D and 4D Scenes @yuyangzhao_, Chung-Ching Lin, Kevin Lin, Zhiwen Yan, Linjie Li, Zhengyuan Yang, Jianfeng Wang, @gimhee_lee, Lijuan Wang arxiv.org/pdf/2411.02319





🚨BreakingNews🚨 🎥 Highlight of the day: camera controls have appeared in Gen3 alpha! #runway No official announcement yet, but it looks like they’re rolling it out gradually. 😍

Advanced Camera Control is now available for Gen-3 Alpha Turbo. Choose both the direction and intensity of how you move through your scenes for even more intention in every shot. (1/8)

1/ We are excited to introduce Oasis, the world's first real-time AI world model, developed in collaboration with @Etched Imagine a video game entirely generated by AI, or a video you can interact with—constantly rendered at 20 fps, in real-time, with zero latency

Current video representation models (e.g. VideoMAE) are inefficient learners. How inefficient? We show that reprs with similar quality can be learned without training on *any* real videos, by using synthetic datasets that were created from very simple generative processes!

CamI2V is a method which can generate videos from images with precise control over camera movements and text prompts. 1st row: zoom in 2nd row: zoom out 3rd row: orbit left 4th row: orbit right Links ⬇️


re10k is all you need

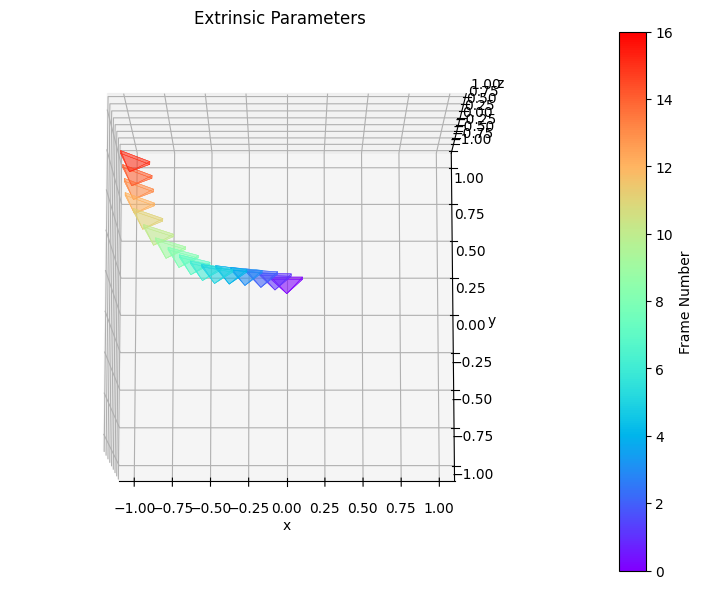
OpenSora is great but no viewpoint control? Check out our method which effectively moves the camera however you want for Video Diffusion Transformers. Key features: 1. It also controls speed. 2. Only 1 frame has input camera also works. Congrats @soon_yau for the amazing result🚀

We're excited to introduce our new 1-step image generator, Diffusion2GAN at #ECCV2024, which enables ODE-preserving 1k image generation in just 0.16 seconds! Check out our #ECCV2024 paper mingukkang.github.io/Diffusion2GAN/ and stop by poster #181 (Wed Oct 2, 10:30-12:30 CEST) if you're…
Super cool

Ever wanted to play Counter-Strike in a neural network? These videos show people playing (with keyboard & mouse) in 💎 DIAMOND's diffusion world model, trained to simulate the game Counter-Strike: Global Offensive. 💻 Download and play it yourself → github.com/eloialonso/dia… 🧵
Testing temporal coherence of the new monocular depth estimator Depth Pro: Sharp Monocular Metric Depth in Less Than a Second with my own videos. The admittedly challenging and low-detail background seems quite unstable.

Pretty comprehensive, 92-page technical report of 𝐌𝐨𝐯𝐢𝐞 𝐆𝐞𝐧: ai.meta.com/static-resourc… - 30B parameters - Train on O(100)M videos, O(1)B images - Cluster of 6,144 H100 GPUs - Temporal Autoencoder (TAE) for latents - Transformer model with Flow Matching - Synchronized audio

🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date. Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in…

The 3D vision community really hates the bitter lesson. Dust3r is what you get when you take the lesson seriously.






























































































United States Trends
- 1. Cowboys 53,8 B posts
- 2. Cooper Rush 10,1 B posts
- 3. Texans 52,5 B posts
- 4. #WWERaw 58,4 B posts
- 5. Mike McCarthy 2.073 posts
- 6. Trey Lance 2.269 posts
- 7. Sixers 9.856 posts
- 8. Mixon 12,9 B posts
- 9. Pulisic 19,1 B posts
- 10. #HOUvsDAL 7.760 posts
- 11. Derek Barnett 1.429 posts
- 12. Aubrey 15,1 B posts
- 13. Pitre 1.212 posts
- 14. #USMNT 3.277 posts
- 15. Keon Ellis N/A
- 16. #AskShadow 6.094 posts
- 17. Turpin 3.097 posts
- 18. Guyton 1.152 posts
- 19. CJ Stroud 3.371 posts
- 20. CeeDee 4.208 posts
Something went wrong.
Something went wrong.