
Vijay Murari Tiyyala(Looking for PhD Fall’25)
@VijayTiyyala@JHUCompSci Research Assistant @jhuclsp @mdredze Research interests:Reasoning/Alignment LLMs, Model Editing, Interpretability. (విజయ్ మురారి)
Similar User

@amuuueller

@YunmoChen

@StellaLisy

@lltjuatja

@boyuan__zheng

@abe_hou

@CanyuChen3

@ruyimarone

@remorax98

@n_verma1

@kesnet50

@nikhilsksharma

@Nathaniel_Weir

@zeugma95031605

@jackjingyuzhang

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this: Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢 🧵⬇️


(1/5) Very excited to announce the publication of Bayesian Models of Cognition: Reverse Engineering the Mind. More than a decade in the making, it's a big (600+ pages) beautiful book covering both the basics and recent work: mitpress.mit.edu/9780262049412/…


Whoever RLHF'ed every LLM response to bullet points you made our lives objectively worse 🫤

Announcing the 20 **Outstanding Papers** for #EMNLP2024





Why do we treat train and test times so differently? Why is one “training” and the other “in-context learning”? Just take a few gradients during test-time — a simple way to increase test time compute — and get a SoTA in ARC public validation set 61%=avg. human score! @arcprize


🎉Congratulations to @jhuclsp authors on 22 papers accepted to #EMNLP2024!

I am recruiting 1-2 PhD students this cycle @RutgersCS to work on Responsible NLP topics! I will be at #EMNLP2024 next week. If you will be attending the conference and are interested in working with me, please reach out!✨

There’s a lot of work on democratizing medical knowledge and care using AI like MedGemini and GPT-o1 type models. I think this is a very promising direction and in many ways outperforms humans already. Have hope. Good people are working on this kind of thing too. @VijayTiyyala 👀

Process supervision for reasoning is 🔥! While previous approaches often relied on human annotation and struggled to generalize across different reasoning tasks, we're now asking: Can we improve this? Introducing 𝐑𝐀𝐓𝐈𝐎𝐍𝐀𝐋𝐘𝐒𝐓: a new model pre-trained on implicit…


Rice CS extends a warm welcome to new assistant professor @hanjie_chen! Dr. Chen specializes in natural language processing, interpretable machine learning, and trustworthy AI. bit.ly/3z5ak4s


We just released our survey on "Model MoErging", But what is MoErging?🤔Read on! Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "compose/remix" their skills using some routing mechanism to tackle new tasks and queries! 🧵👇…


🚨 Postdocs at @jhuclsp! We're interested in several topics, including: - Explainable AI/NLP for medicine - Clinical NLP - Evaluation of LLMs Apply: apply.interfolio.com/108613 Spread the word! #ACL2024NLP #ACL2024 @aclmeeting

Training a large language model? Pre-train then fine-tune! But how does pre-training affect downstream fine-tuning performance? What is learned during pre-training vs. fine-tuning? Here are some results. (🧵below) arxiv.org/abs/2408.06663 #NLProc

🚨 Students/postdocs: The Responsible AI for Health Symposium (RAIHS) at @JHUBloombergCtr on Aug 29 has travel grants! Amazing speakers! Very limited availability. Apply by Aug 8. forms.gle/HpPc5rZNPH6Hsb… Spread the word. @JHUCarey @HopkinsEngineer carey.jhu.edu/RAIHS

New #Nature study: Generative models forget true data distribution when recursively trained on synthetic data. As quality human data becomes scarce, caution is needed. This highlights the need for #watermarking to filter AI-generated content for future models.


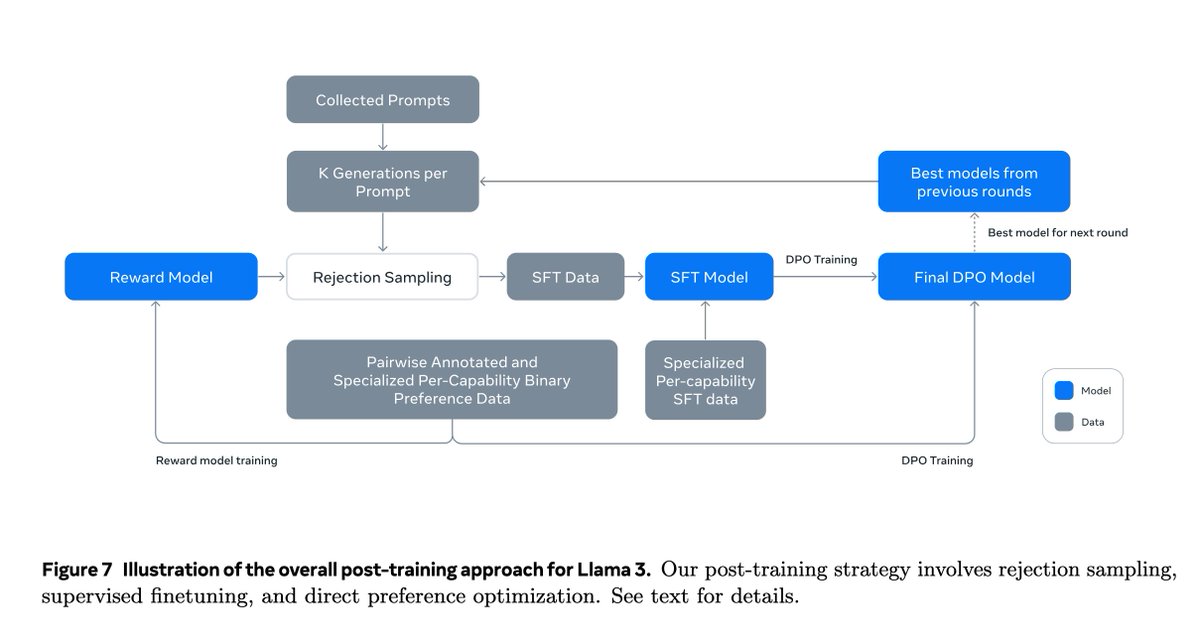
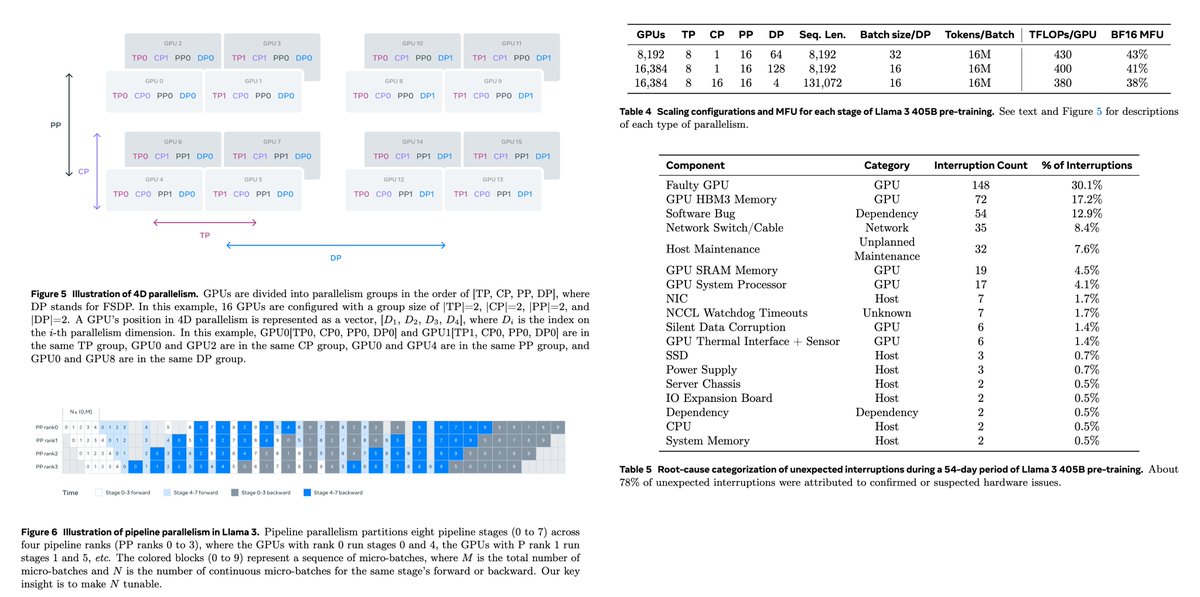
I went through the Llama-3 technical report (92 pages!). The report is very detailed, and it will be hard to describe everything in a single tweet, but I will try to summarize it in the best possible way. Here we go... Overview - Standard dense Transformer with minor changes -…



4 months since we released BitNet b1.58🔥🔥 After we compressed LLM to 1.58 bits, the inference of 1bit LLM is no longer memory-bound, but compute-bound. 🚀🚀Today we introduce Q-Sparse that can significantly speed up LLM computation.



RLHF aligns LMs to a fixed weighted combinations of rewards, but cannot retrain a new model for each user's preferred weightings. To achieve customization, prior work merges the parameters of single-objective models. Can we do better? We show that merging logits is better!


Late posting this, but super grateful I got to present this work at @naaclmeeting & @AmericasNLP! Huge thanks to the Kreyòl-MT team @prajdabre1 @netori3 @kentonmurray @Linguist_sam @LoicGrobol @VijayTiyyala @rasmundi @Tanishkaashi @BismarckBamfo et al.


Introducing Kreyòl-MT: a new machine translation dataset for 41 Caribbean, Latin American, and Colonial African Creole languages 🌎🌍🌏 arxiv.org/abs/2405.05376 #NLProc youtube.com/watch?v=pilC9G… (1/5)

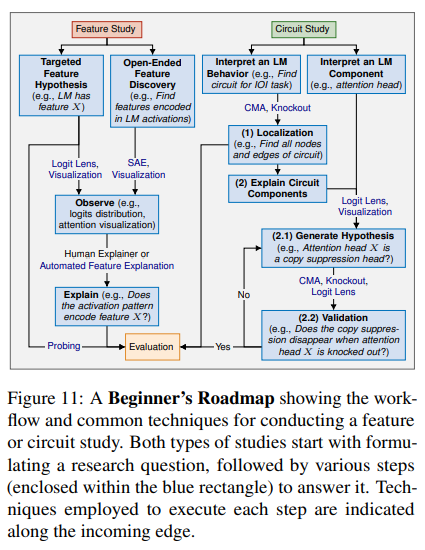
[1/6] Mechanistic Interpretability (MI) is an emerging sub-field of interpretability that aims to understand LMs by reverse-engineering its underlying computation. Here we present a comprehensive survey curated specifically as a 𝐠𝐮𝐢𝐝𝐞 𝐟𝐨𝐫 𝐧𝐞𝐰𝐜𝐨𝐦𝐞𝐫𝐬 𝐭𝐨 𝐭𝐡𝐢𝐬…























































































United States Trends
- 1. 49ers 30,2 B posts
- 2. Cowboys 58,1 B posts
- 3. Packers 30,4 B posts
- 4. Niners 6.299 posts
- 5. #GoPackGo 6.460 posts
- 6. #PrizePicksMilly 1.176 posts
- 7. $CUTO 6.558 posts
- 8. Raiders 28,2 B posts
- 9. Josh Jacobs 4.555 posts
- 10. Broncos 20,1 B posts
- 11. Deebo 5.455 posts
- 12. Geno 7.040 posts
- 13. Chiefs 75,1 B posts
- 14. Bears 82,3 B posts
- 15. Seahawks 17,7 B posts
- 16. Panthers 44,9 B posts
- 17. Christian Watson 2.133 posts
- 18. Brandon Allen 3.810 posts
- 19. Dobbs 4.289 posts
- 20. Texans 31,1 B posts
Who to follow
-
 Aaron Mueller
Aaron Mueller
@amuuueller -
 Yunmo Chen
Yunmo Chen
@YunmoChen -
 Stella Li
Stella Li
@StellaLisy -
 Lindia Tjuatja
Lindia Tjuatja
@lltjuatja -
 Boyuan Zheng
Boyuan Zheng
@boyuan__zheng -
 Abe Hou
Abe Hou
@abe_hou -
 Canyu Chen (Seeking Ph.D. 25fall)
Canyu Chen (Seeking Ph.D. 25fall)
@CanyuChen3 -
 Marc Marone
Marc Marone
@ruyimarone -
 Vivek Iyer
Vivek Iyer
@remorax98 -
 Neha Verma
Neha Verma
@n_verma1 -
 Kate Sanders @ kesnet50.bsky.social
Kate Sanders @ kesnet50.bsky.social
@kesnet50 -
 Nikhil Sharma
Nikhil Sharma
@nikhilsksharma -
 Nathaniel Weir
Nathaniel Weir
@Nathaniel_Weir -
 🍓
🍓
@zeugma95031605 -
 Jack Jingyu Zhang
Jack Jingyu Zhang
@jackjingyuzhang
Something went wrong.
Something went wrong.