
Similar User

@iHR4K

@matsiiako

@Vizcom_ai

@aviskowron

@GKopanas

@MattMikula

@thejuproject

@jwkirchenbauer

@PiotrRMilos

@HoskinsAllen

@bobda

@dmayhem93

@HaoyiZhu

@daryl_imagineai

@tonyjhartshorn

Why do we treat train and test times so differently? Why is one “training” and the other “in-context learning”? Just take a few gradients during test-time — a simple way to increase test time compute — and get a SoTA in ARC public validation set 61%=avg. human score! @arcprize


Quantization method that accounts for how many instructions it takes on GPUs to dequantize! We're passed just counting FLOPS or memory access, we're counting instructions

🧵 🏎️ Want faster, better quantized LLMs? Introducing QTIP, a new LLM quantization method that achieves a SOTA combination of quality and speed – outperforming methods like QuIP#! 🧑💻+🦙(w/ 2 bit 405B!): github.com/Cornell-RelaxM… 📜arxiv.org/abs/2406.11235

We have released a torch compile friendly version of the scatterMoE kernel. Speedups are around 5-7% on 64 H100s for 1B MoE model. Larger MoEs or MoEs with larger compute density will benefit more from the optimization. Code: github.com/mayank31398/ke…


We have updated our PowerLM series models. They are now under Apache 2.0. And with a slight tweak to the data mix, they perform better than the previous version. PowerLM-3B: huggingface.co/ibm/PowerLM-3b PowerMoE-3B (800M active params): huggingface.co/ibm/PowerMoE-3b

Smol models FTW

PowerMoE from IBM look underrated - Trained on just 1T (PowerLM 3B) & 2.5T (PowerMoE 0.8B active, 3B total) - open model weights - comparable perf to Gemma, Qwen 🔥 > Two-stage training scheme > Stage 1 linearly warms up the learning rate and then applies the power decay > Stage…

Padding-Free transformers now accelerate training models with HuggingFace library natively. 2x throughput improvement without any approximations. NO CUSTOM DEVICE KERNELS!! (except Flash Attention)

Want to get 2x throughput improvement on your tuning jobs across various HF models without changing any code and effecting model quality? Now you can simply use Hugging Face transformers and TRL to do this! Read more here: research.ibm.com/blog/hugging-f… Key findings: 1. Simple sequence…

Here is a new Machine Learning Engineering chapter: Network debug github.com/stas00/ml-engi… The intention is to help non-network engineers to figure out how to resolve common problems around multi-gpu and multi-node collectives networking - it's heavily NCCL-biased at the moment.…

ScatterMoE is accepted by CoLM. See you in Philadelphia!

Scattered Mixture-of-Experts Implementation - Presents ScatterMoE, an implementation of Sparse Mixture-of-Experts on GPU - Enables a higher throughput and lower memory footprint repo: github.com/shawntan/scatt… abs: arxiv.org/abs/2403.08245

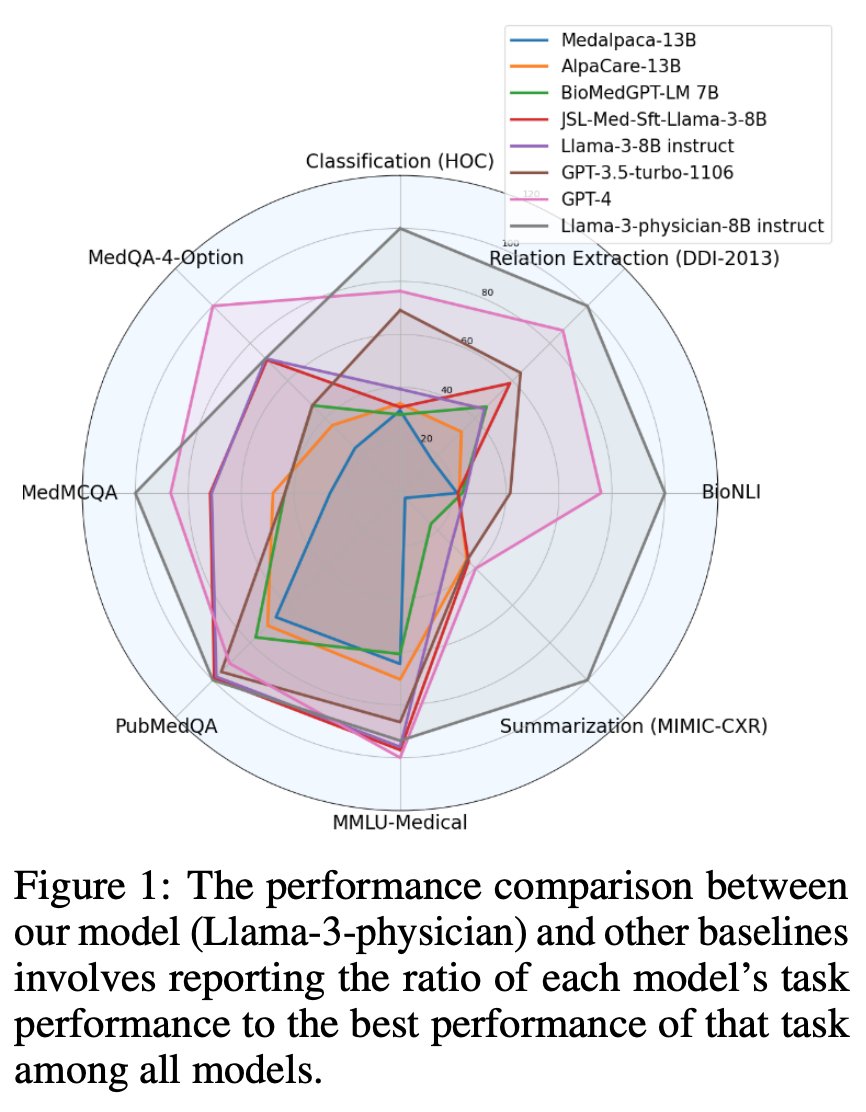
With a few tricks, Llama-3-8B can be continued trained to outperform GPT-4 on Medical tasks. For more details, check our paper Efficient Continual Pre-training by Mitigating the Stability Gap (arxiv.org/abs/2406.14833)!
We have released 4-bit GGUF versions of all Granite Code models for local inference. 💻 The models can be found here: huggingface.co/collections/ib…
New preprint out with colleagues from MIT and IBM "Reducing Transformer Key-Value Cache Size with Cross-Layer Attention": arxiv.org/abs/2405.12981 We introduce a simple mechanism of sharing keys and values across layers, reducing the memory needed for KV cache during inference!!

JetMoE and IBM Granite Code models are now natively available on in Huggingface Transformers v4.41! github.com/huggingface/tr…
Yes sir :)

Our IBM Granite Code series models are finally released today. Despite the strong code performance that you should definitely check out, I also want to point out that the math reasoning performance of our 8B models is unexpectedly good. Congrats to all our teammates!…

Open-sourcing Granite Code models (3B, 8B, 20B, 34B) trained on 3-4 trillion tokens of code. → Completely Apache 2.0 → Outperforming all models openly available → Amazing mathematical and reasoning performance Paper: github.com/ibm-granite/gr… Models: huggingface.co/collections/ib…

Unveiling BRAIn, a new method of aligning LLMs with preferencial data. Kudos to @gauravpandeyamu for leading this effort. The work has been accepted for publication at ICML.

Minimizing forward KL wrt PPO-optimal policy (proceedings.neurips.cc/paper_files/pa……) policy doesn't perform as well for RLHF as PPO and DPO. Or does it? In our ICML paper (arxiv.org/abs/2402.02479), we show that it actually performs much better if an appropriate baseline is chosen.
New way of training MoE's Thanks for all you hard work @BowenPan7

Thrilled to unveil DS-MoE: a dense training and sparse inference scheme for enhanced computational and memory efficiency in your MoE models! 🚀🚀🚀 Discover more in our blog: huggingface.co/blog/bpan/ds-m… and dive into the details with our paper: arxiv.org/pdf/2404.05567…























































































United States Trends
- 1. #UFC309 257 B posts
- 2. Jon Jones 111 B posts
- 3. Jon Jones 111 B posts
- 4. Jon Jones 111 B posts
- 5. Chandler 82,4 B posts
- 6. Oliveira 68,7 B posts
- 7. #discorddown 6.352 posts
- 8. Bo Nickal 8.387 posts
- 9. Kansas 19,7 B posts
- 10. Do Bronx 10,2 B posts
- 11. #MissUniverse 420 B posts
- 12. Tennessee 54,5 B posts
- 13. Tatum 27,1 B posts
- 14. Oregon 33,8 B posts
- 15. Keith Peterson 1.247 posts
- 16. Paul Craig 4.372 posts
- 17. Beck 21,5 B posts
- 18. #BYUFootball 1.222 posts
- 19. Rock Chalk 1.001 posts
- 20. #kufball N/A
Who to follow
-
 Sergei 🇺🇦
Sergei 🇺🇦
@iHR4K -
 Vlad Matsiiako 🇺🇦
Vlad Matsiiako 🇺🇦
@matsiiako -
 Vizcom
Vizcom
@Vizcom_ai -
 Aviya Skowron
Aviya Skowron
@aviskowron -
 George Kopanas
George Kopanas
@GKopanas -
 Maciej Mikuła
Maciej Mikuła
@MattMikula -
 divorcioeparentalidade
divorcioeparentalidade
@thejuproject -
 John Kirchenbauer
John Kirchenbauer
@jwkirchenbauer -
 Piotr Miłoś
Piotr Miłoś
@PiotrRMilos -
 allen h
allen h
@HoskinsAllen -
 Bob Andrew Piercy
Bob Andrew Piercy
@bobda -
 dmayhem93
dmayhem93
@dmayhem93 -
 Haoyi Zhu
Haoyi Zhu
@HaoyiZhu -
 Daryl
Daryl
@daryl_imagineai -
 Anthony Hartshorn
Anthony Hartshorn
@tonyjhartshorn
Something went wrong.
Something went wrong.