
Kacper Łukawski
@LukawskiKacperDevRel @qdrant_engine | Founder @AIEmbassy Foundation
Similar User

@qdrant_engine

@AmogKamsetty

@bobvanluijt

@aestheticedwar1

@etiennedi

@DmitryKan

@atitaarora

@SeaseLtd

@antas_marcin

@firqaaaa

@jackminong

@therealaseifert

@zhenwang_23

@dziubjak

@KeelieBach
It's been over a week since the official launch, so in case you missed it, please check out a short course prepared together with the @DeepLearningAI team! We covered some important topics, including tokenization and optimizing the semantic search layer in your RAG pipelines!

Tokenization -- turning text into a sequence of integers -- is a key part of generative AI, and most API providers charge per million tokens. How does tokenization work? Learn the details of tokenization and RAG optimization in Retrieval Optimization: From Tokenization to Vector…

We had a great session about @nvidia NIMs with @ansjin and @MarkMoyou yesterday. 🚀 From Mark: We got lots of info on inferencing with NIMs and different types of NIMs like embedding models, generative models, reranking models.. 🎨 I walked through how you can use NIMs for…

Some of the most popular embedding models out there have a particular issue. They do not support emojis out of the box, so the following sentences have identical representations: I feel so 😃 today = I feel so 😢 today

We're going to start the fine-tuning from the perspective of a regular @qdrant_engine user with lots of data vectorized who wants to avoid heavy and expensive recomputation of them all! It seems fine-tuning with backward compatibility might be possible in some cases! 🤓

Join our webinar if you want to adopt semantic search in a new area. @LukawskiKacper will present tips on teaching your dog new tricks, even with backward compatibility of the embeddings 😱 This time, we're joining forces with @origlobalcloud and their GPU Cloud and trying to…
Dense embedding models are not giving up yet! Surprisingly, they are also pretty good late interaction models! Please welcome ColBERT-like retrieval with just sentence transformers 🎉

Late interaction models are great for improving the quality of the results. But couldn't we design future embedding models so they can better solve both single and multi-vector search, though? The existing dense models can do it quite well already 🤔 qdrant.tech/articles/late-…

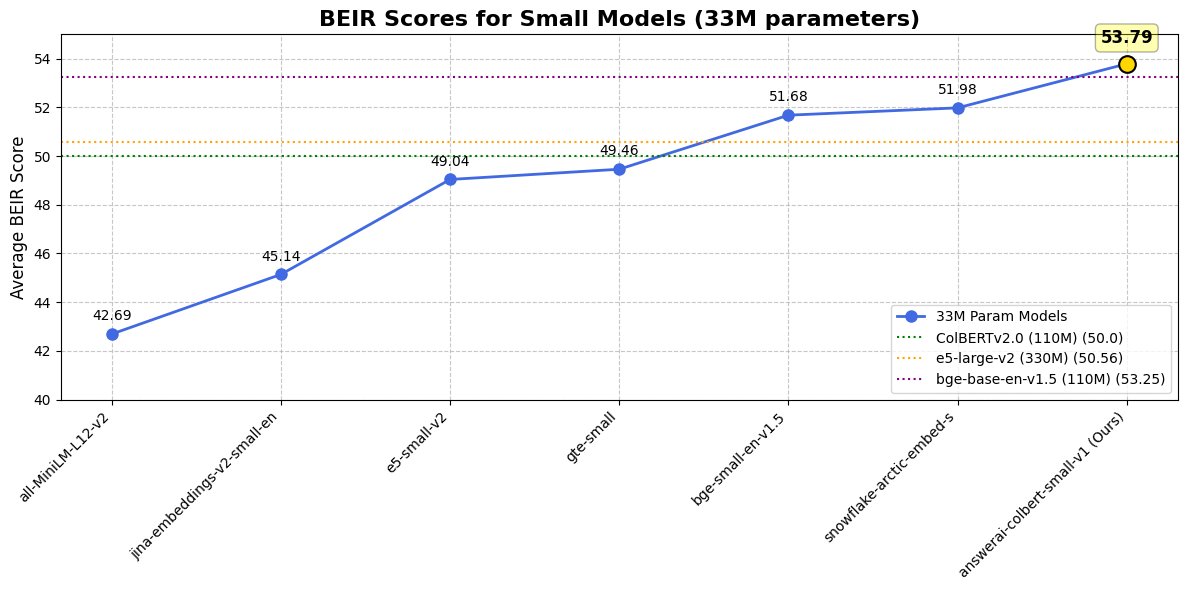
🎉Happy to finally release answerai-colbert-small-v1: the small but mighty @answerdotai ColBERT. It might not be able to count the number of "r"s in words, but it can definitely find the instructions on how to do that. With just 33M params, it beats even `bge-base` on BEIR!
































































































United States Trends
- 1. Mike Rogers 151 B posts
- 2. #FridayVibes 7.841 posts
- 3. Muppets 4.265 posts
- 4. #FridayMorning 3.023 posts
- 5. Jason Kelce 2.060 posts
- 6. Pam Bondi 333 B posts
- 7. #BOYCOTT143ENT 12,3 B posts
- 8. #FursuitFriday 13 B posts
- 9. Happy Friyay 2.876 posts
- 10. Roller Coaster 3.695 posts
- 11. #WeStandWithMadein 10,9 B posts
- 12. CONGRATULATIONS JIMIN 334 B posts
- 13. $MAD 5.877 posts
- 14. McCabe 27,8 B posts
- 15. Chris Brown 32,9 B posts
- 16. Dan Scavino 2.257 posts
- 17. Randle 7.817 posts
- 18. Jim Cramer 2.408 posts
- 19. Kang 37,1 B posts
- 20. President John F. Kennedy 9.521 posts
Who to follow
-
 Qdrant
Qdrant
@qdrant_engine -
 Amog Kamsetty
Amog Kamsetty
@AmogKamsetty -
 Bob van Luijt
Bob van Luijt
@bobvanluijt -
 Edward
Edward
@aestheticedwar1 -
 Etienne Dilocker
Etienne Dilocker
@etiennedi -
 Dmitry Kan
Dmitry Kan
@DmitryKan -
 atitaarora
atitaarora
@atitaarora -
 Sease
Sease
@SeaseLtd -
 Marcin Antas
Marcin Antas
@antas_marcin -
 π12Qα
π12Qα
@firqaaaa -
 Jackmin
Jackmin
@jackminong -
 Alexander Seifert
Alexander Seifert
@therealaseifert -
 zhen Wang
zhen Wang
@zhenwang_23 -
 dziubjak
dziubjak
@dziubjak -
 Keelie Bach
Keelie Bach
@KeelieBach
Something went wrong.
Something went wrong.