
Itamar Zimerman
@ItamarZimermanPhD candidate @ Tel Aviv University. AI Research scientist @ IBM Research. Interested in deep learning and algorithms.
Similar User

@Ofirlin

@YoadTewel

@ShellySheynin

@TShrbny

@BenaimSagie

@ItaiLang

@OhadRubin

@nirzabari

@idansc

@shir_gur

@haim_ben_yakov

@HmedThapar
New!🚨📰 Mamba is a cool, efficient, and effective DL architecture, but what do we know about Mamba? How does it capture interactions between tokens? Can it be the attention-killer? In our work, "The Hidden Attention of Mamba Models" we provide answers to these questions! [1/4]


Excited to announce LTX-Video! Our new text-to-video model generates stunning, high-quality videos faster than real-time—5 seconds of 24fps video at 768x512 in just 4 seconds on an Nvidia H100! ⚡ We’re open-sourcing the code & weights. Check out the results 🎥👇
🚀 Excited to release the code and demo for ConsiStory, our #SIGGRAPH2024 paper! No fine-tuning needed — just fast, subject-consistent image generation! Check it out here 👇 Code: github.com/NVlabs/consist… Demo: build.nvidia.com/nvidia/consist…

Nvidia presents ConsiStory Training-Free Consistent Text-to-Image Generation paper page: huggingface.co/papers/2402.03… enable Stable Diffusion XL (SDXL) to generate consistent subjects across a series of images, without additional training.


🎙️ Proud to share our new preprint: Continuous Speech Synthesis using per-token Latent Diffusion Check it out: huggingface.co/papers/2410.16… @ArnonTu, @NimrodShabtay #IBMResearch #SpeechSynthesis


Introducing LiveXiv, a new, challenging and maintainable scientific multi-modal live dataset Paper: arxiv.org/abs/2410.10783 Github: github.com/NimrodShabtay/… Dataset: huggingface.co/datasets/LiveX…

I'm going to present ConsiStory📖 at #SIGGRAPH2024 this Monday @ 2pm! If you're around this week, DM me if you want to chat! Details below⬇️🧵
Nvidia presents ConsiStory Training-Free Consistent Text-to-Image Generation paper page: huggingface.co/papers/2402.03… enable Stable Diffusion XL (SDXL) to generate consistent subjects across a series of images, without additional training.
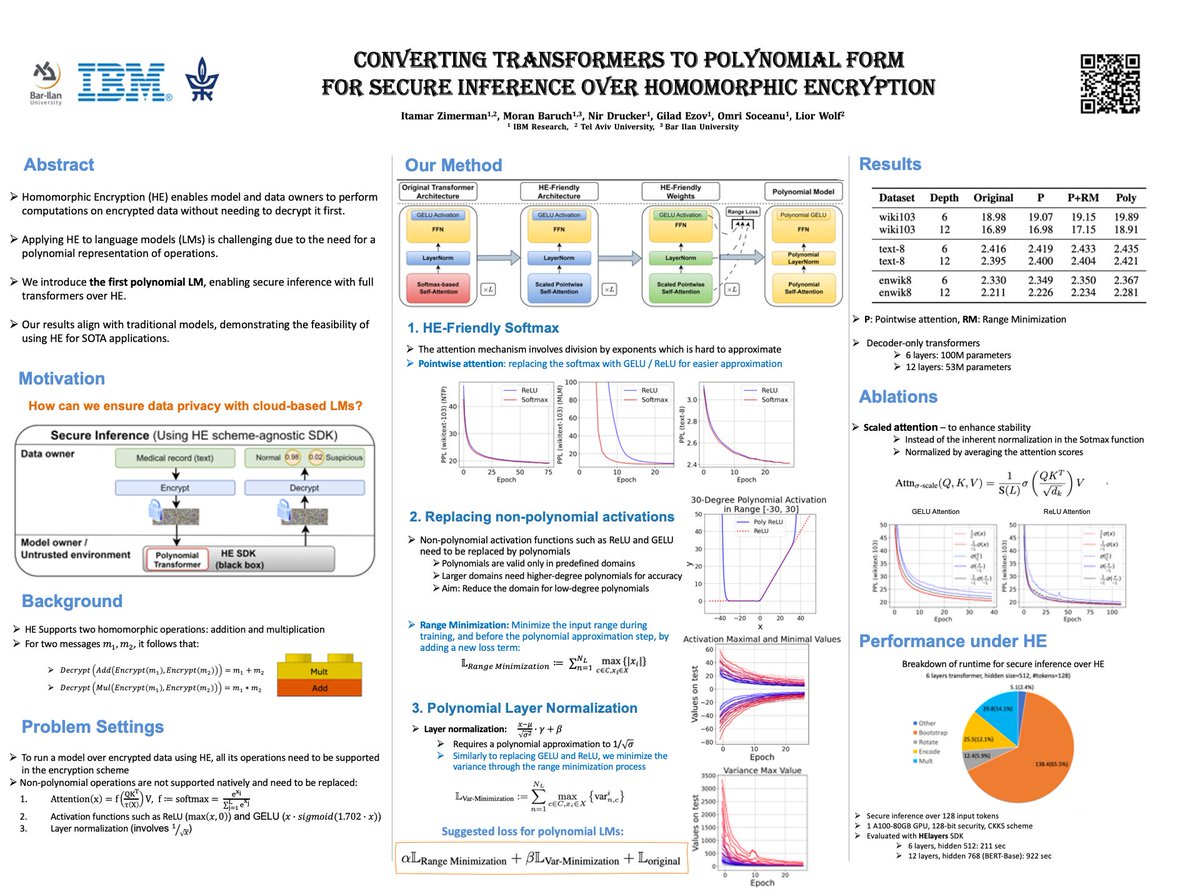
Given a polynomial P and an input x, the magic of homomorphic encryption enables the computation of Dec(P(Enc(x)), yielding P(x) without exposing information about x or P. By converting transformers into polynomials, we provide a new framework for confidential computing with LMs!


1/5 Worried about your sensitive data while using LLMs? Come and join me tomorrow at @icmlconf at 11:30, presenting our work: "Converting Transformers to Polynomial Form for Secure Inference over Homomorphic Encryption" (#2115). #IBMResearch #HELayers >>

Want to train short and evaluate long? 📚🤖 DeciMamba code is out! Github 👉 github.com/assafbk/DeciMa… Paper 👉 arxiv.org/abs/2406.14528
New Work! 🐍 What prevents Mamba from extrapolating to sequences that are significantly longer than those it was trained on? Furthermore, can Mamba solve long-range NLP tasks using short-range training only? 🧵🧵🧵


NEW! 📰📢 What are Mamba's length generalization capabilities? What limits them? How can we unlock their potential for real-world long NLP tasks? In a very fun work led by Assaf @abk_tau, we dive deep into these questions! arxiv.org/abs/2406.14528
New Work! 🐍 What prevents Mamba from extrapolating to sequences that are significantly longer than those it was trained on? Furthermore, can Mamba solve long-range NLP tasks using short-range training only? 🧵🧵🧵

Why do state-space models work so well? With @orvieto_antonio, we study their learning dynamics and find that diagonal recurrence is key: 1. It helps in better conditioning the loss landscape 2. It facilitates Adam's job by making the Hessian diagonal 📝 arxiv.org/abs/2405.21064


🧵 Exciting news from our latest research on Interpretability of LMs and fairness! Our paper "Natural Language Counterfactuals through Representation Surgery" introduces a novel approach to interpret representational level interventions and mitigate biases in language models.👇

Introducing Menteebot: Groundbreaking Humanoid Robot. We're proud to unveil Menteebot, the culmination of a two-year journey by our brilliant team! Menteebot is a groundbreaking humanoid robot designed for versatility. Visit our website menteebot.com for more demos.











































































United States Trends
- 1. #PrizePicksMilly 2.582 posts
- 2. 49ers 34,1 B posts
- 3. Packers 35,5 B posts
- 4. Raiders 32 B posts
- 5. Niners 7.133 posts
- 6. Cowboys 59,2 B posts
- 7. #GoPackGo 7.135 posts
- 8. $CUTO 5.846 posts
- 9. Rams 16,2 B posts
- 10. Broncos 23,9 B posts
- 11. Josh Jacobs 5.466 posts
- 12. Deebo 5.983 posts
- 13. Seahawks 20,6 B posts
- 14. Geno 7.254 posts
- 15. #PrizePicksDiscord N/A
- 16. Chiefs 76,7 B posts
- 17. Christian Watson 2.172 posts
- 18. Bears 83,4 B posts
- 19. Brandon Allen 4.000 posts
- 20. Minshew 4.052 posts
Who to follow
-
 Ofir Lindenbaum
Ofir Lindenbaum
@Ofirlin -
 Yoad Tewel
Yoad Tewel
@YoadTewel -
 Shelly Sheynin
Shelly Sheynin
@ShellySheynin -
 Tal Shaharabany
Tal Shaharabany
@TShrbny -
 Sagie Benaim
Sagie Benaim
@BenaimSagie -
 Itai Lang
Itai Lang
@ItaiLang -
 Ohad Rubin
Ohad Rubin
@OhadRubin -
 Nir Zabari
Nir Zabari
@nirzabari -
 Idan Schwartz
Idan Schwartz
@idansc -
 Shir Gur 🎗️
Shir Gur 🎗️
@shir_gur -
 Dr. Haim Ben Yakov
Dr. Haim Ben Yakov
@haim_ben_yakov -
 Mechanical Engineering Department,Thapar Institute
Mechanical Engineering Department,Thapar Institute
@HmedThapar
Something went wrong.
Something went wrong.