
Edvard Avagyan
@DarkOdysseusData Engineering and Deep Learning enthusiast | Ms. C Data Engineering and Analytics at TUM | GitHub: https://t.co/4HQRij9Lbo

Llama3 was trained on 15 trillion tokens of public data. But where can you find such datasets and recipes?? Here comes the first release of 🍷Fineweb. A high quality large scale filtered web dataset out-performing all current datasets of its scale. We trained 200+ ablation…

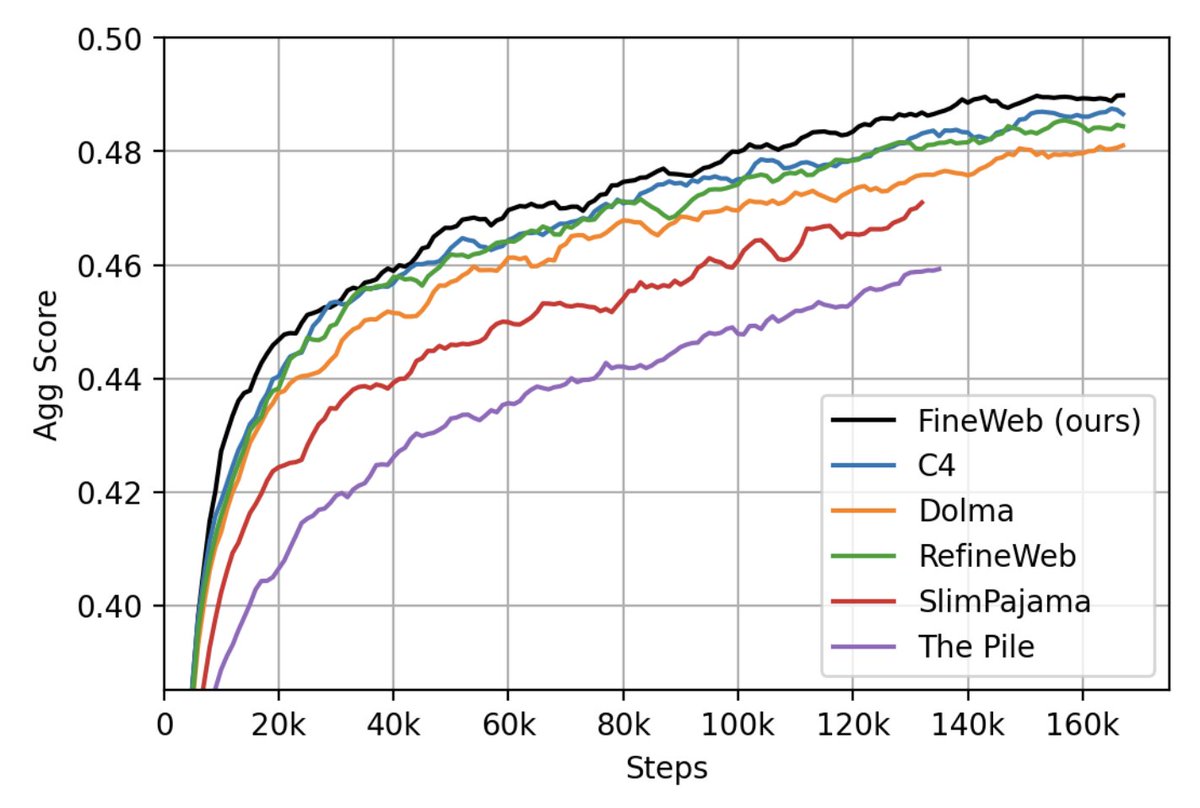
We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!

One of the best pieces of career advice I received came indirectly from @myleott, via @stephenroller, which was to always "optimize for knowledge." I've found that this holds through every layer of abstraction, from company/team choice down to the specifics of daily experiments



Today I have a huge announcement. The dataset used to create Open Hermes 2.5 and Nous-Hermes 2 is now PUBLIC! Available Here: huggingface.co/datasets/tekni… This dataset was the culmination of all my work on curating, filtering, and generating datasets, with over 1M Examples from…


If you're a Python programmer looking to get started with CUDA, this weekend I'll be doing a free 1 hour tutorial on the absolute basics. Thanks to @neurosp1ke, @marksaroufim, and @ThomasViehmann for hosting this on the CUDA MODE server. :D Click here: discord.gg/6z79K5Yh?event…


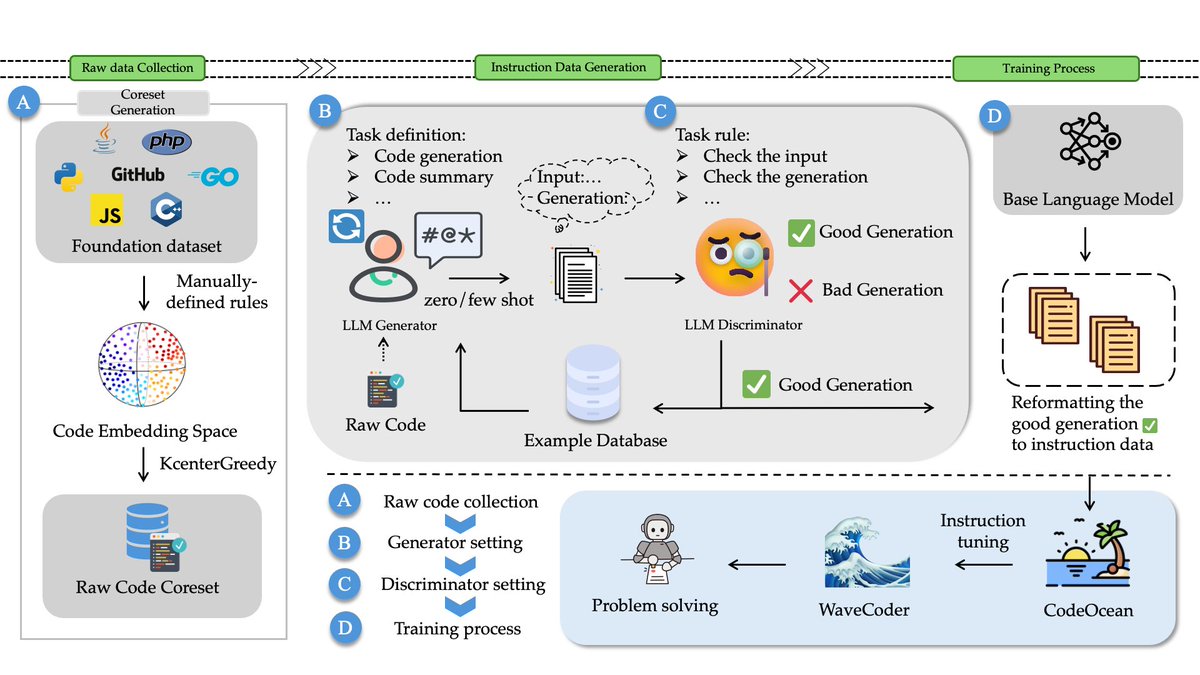
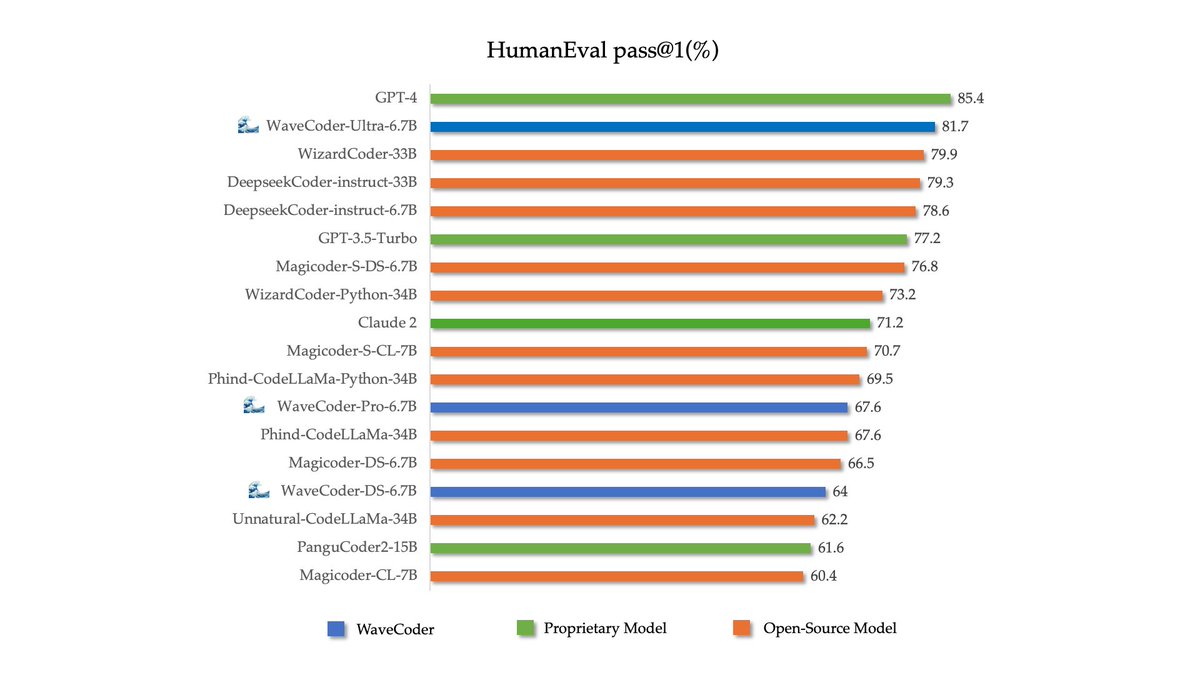
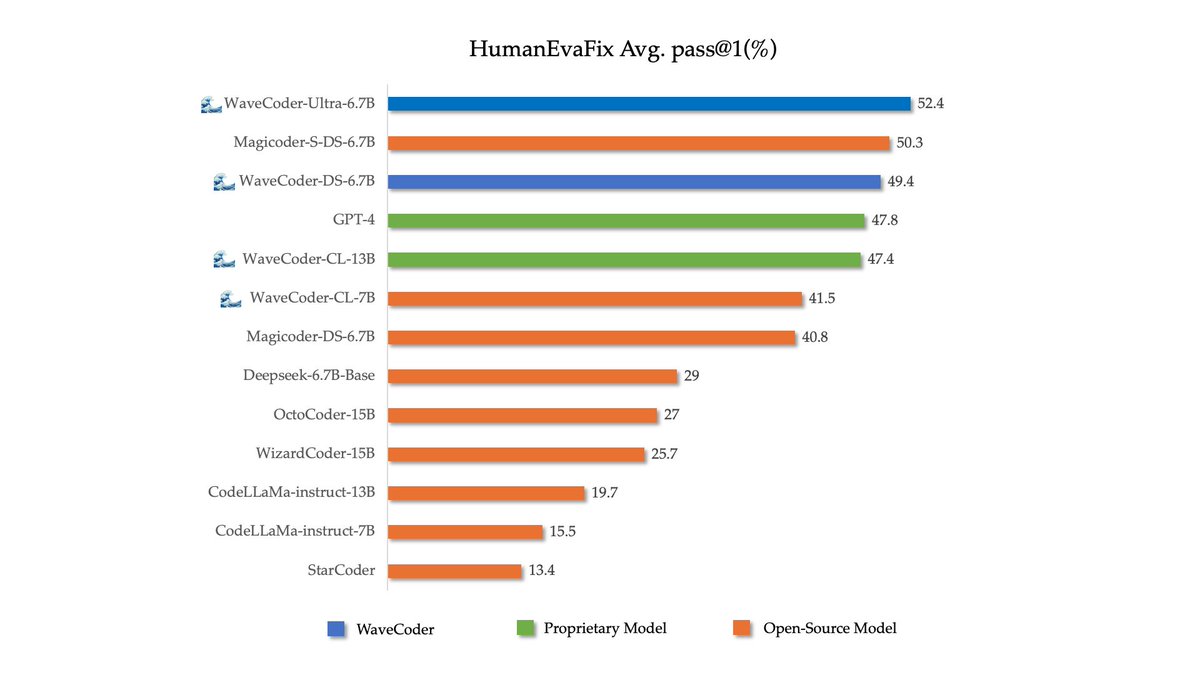
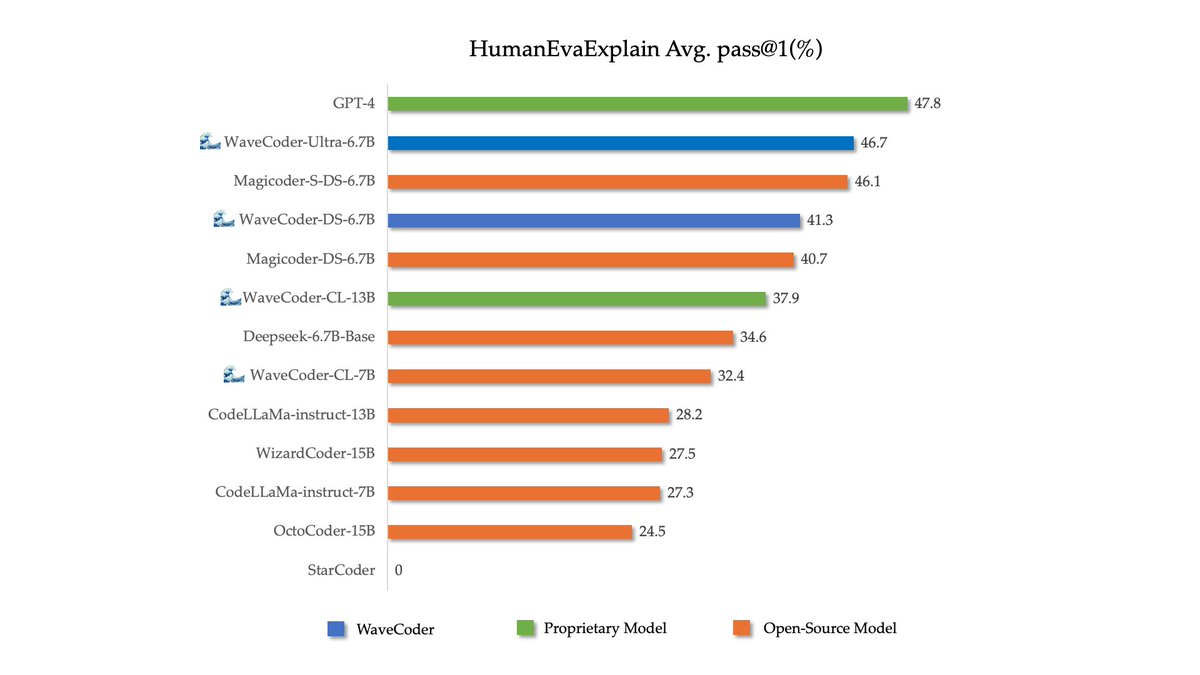
🌊🌊🌊Introduce WaveCoder-Ultra-6.7B with the closest capabilities to GPT-4 so far. Arxiv:arxiv.org/abs/2312.14187 WaveCoder-Ultra-6.7B is the newest SOTA open-source Code LLM on mutiple tasks.

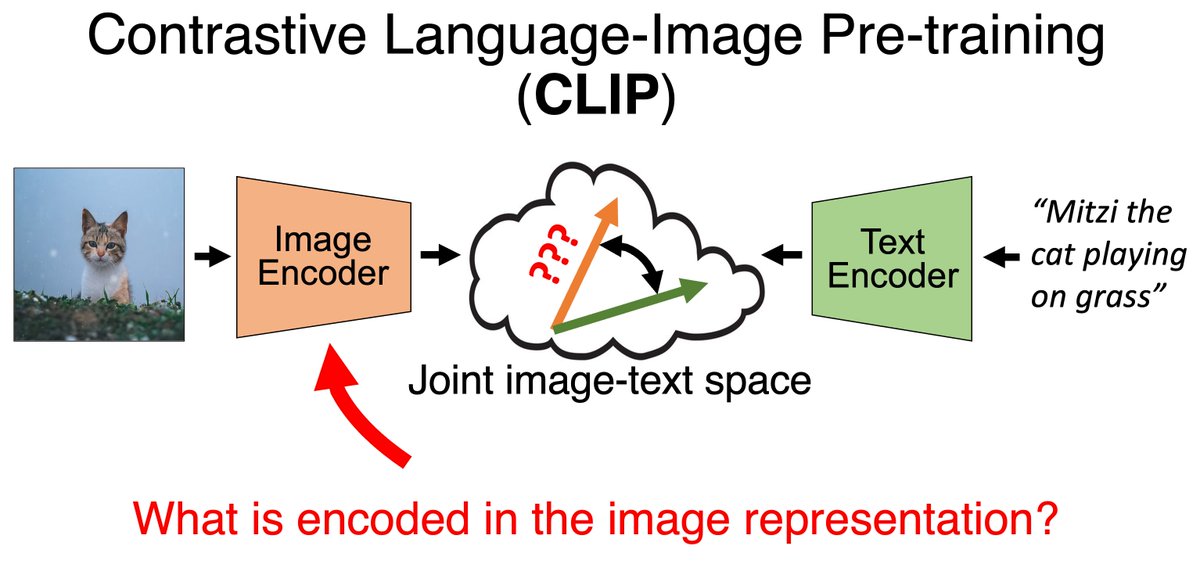
Accepted to oral #ICLR2024! *Interpreting CLIP's Image Representation via Text-Based Decomposition* CLIP produces image representations that are useful for various downstream tasks. But what information is actually encoded in these representations? [1/8]

🚢 Python DPO dataset This is uses items from Vezora/Tested-22k-Python-Alpaca as the "chosen" responses, and 13b/7b gens as rejected (assumed to be worse, not ranked/validated). huggingface.co/datasets/jondu…

It's pretty amusing seeing your weekend finetune getting downloads on HuggingFace.


you'll never know if you don't try just fucking do it!

Check us our if you're looking to make some easy JS open source contributions I'm trying to convert my python library to javascript, so i need help converting examples, check out our issues for more details github.com/jxnl/instructo…


Let's go 2024 🚀: 🆕 training script in 🧨 @diffuserslib leveraging techniques from the community: ① pivotal tuning (from @cloneofsimo cog-sdxl) ② prodigy optimizer (from kohya's scripts) + more tricks, compatibility with AUTO1111 ♾️ ⏩ all here huggingface.co/blog/sdxl_lora…


Who knew that coffee destroyed the fabric of society 😨☕

Here's the story of another technology that faced massive backlash in its time that will sound very familiar to today's battles over #AI. Coffee. a thread.


Evaluating Language-Model Agents on Realistic Autonomous Tasks Explores the ability of LM agents to acquire resources, create copies of themselves, and adapt to novel challenges they encounter in the wild arxiv.org/abs/2312.11671


I wrote a comprehensive blog on latent consistency models (LCMs). > aaaaaaaaaa.org/lcm The blog explains everything you need to know about LCMs including their math, architecture, finetuning and code.



























































































United States Trends
- 1. #OnlyKash 46,1 B posts
- 2. $MCADE 1.210 posts
- 3. Sweeney 10,9 B posts
- 4. Jaguar 56,3 B posts
- 5. Jose Siri 2.031 posts
- 6. Jim Montgomery 3.292 posts
- 7. $GARY 1.727 posts
- 8. Nancy Mace 77,2 B posts
- 9. Starship 154 B posts
- 10. $MOOCAT 2.187 posts
- 11. Joe Douglas 11,7 B posts
- 12. Monty 10,5 B posts
- 13. Dr. Phil 7.682 posts
- 14. Dr. Mehmet Oz 4.665 posts
- 15. Bader 3.983 posts
- 16. Medicare and Medicaid 16,7 B posts
- 17. Embiid 24,4 B posts
- 18. Rodgers 13,9 B posts
- 19. Jets 43,7 B posts
- 20. Maxey 16,5 B posts
Something went wrong.
Something went wrong.