
Alex Havrilla
@Dahoas1Georgia Tech ML Researcher studying neural network learning theory and LLMs for mathematical reasoning. Intern at FAIR, MSR. Co-founder of CarperAI.
Similar User

@lcastricato

@tri_dao

@ml_hardware

@DbrxMosaicAI

@Francis_YAO_

@YiTayML

@jsuarez5341

@OfirPress

@dust4ai

@ggerganov

@aidangomez

@JayAlammar

@synth_labs

@EthanJPerez

@humanloop

Excited to share work from my internship at @AIatMeta! LLM devs often tweak decoding temperature: low for analytical tasks, and high for creative ones. Why not learn this from the data? Introducing the AdaptiveDecoder! (1/3)🧵
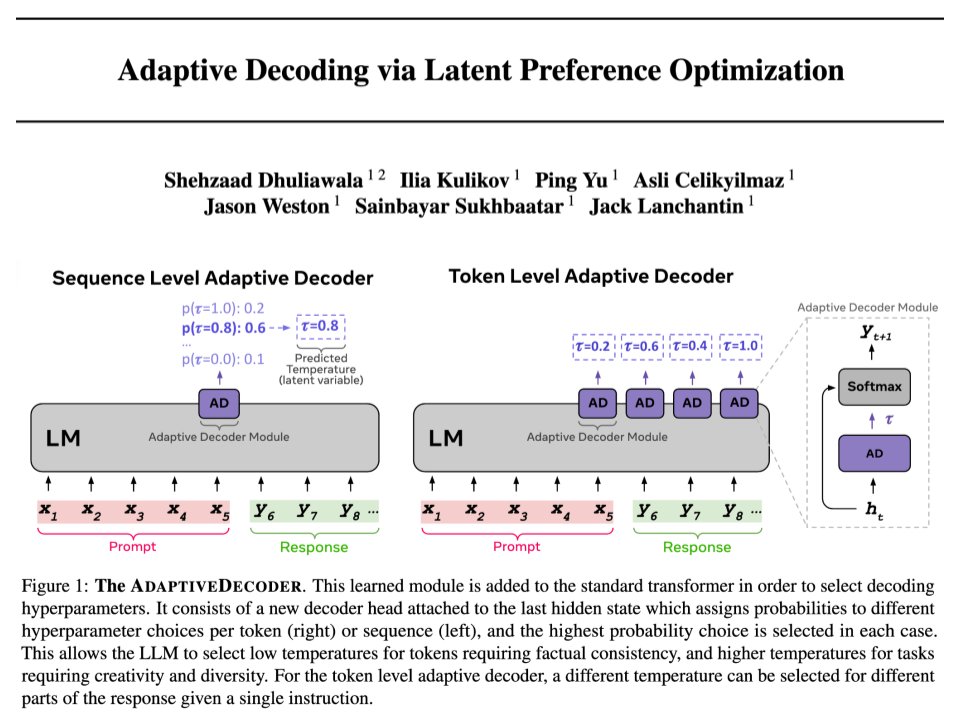

🚨 Adaptive Decoding via Latent Preference Optimization 🚨 - New layer added to Transformer, selects decoding params automatically *per token* - Learnt via new method, Latent Preference Optimization - Outperforms any fixed temperature decoding method, choosing creativity or…


✨ New Evaluation Benchmark for Reward Models - We Go Multilingual! ✨ Introducing M-RewardBench: A massively multilingual RM evaluation benchmark covering 23 typologically different languages across 5 tasks. Paper, code, dataset: m-rewardbench.github.io Our contributions: 1/9


Do you work in AI? Do you find things uniquely stressful right now, like never before? Haver you ever suffered from a mental illness? Read my personal experience of those challenges here: docs.google.com/document/d/1aE…
Super cool work from SynthLabs on generative reward modeling!
🎭 Introducing Generative Reward Models (GenRM): A novel framework for preference learning that improves traditional reward models by up to 45%! 🤖 CoT-GenRM leverages self-generated reasoning traces and iterative training to enable test-time compute for better alignment of…


PERSONA A Reproducible Testbed for Pluralistic Alignment The rapid advancement of language models (LMs) necessitates robust alignment with diverse user values. However, current preference optimization approaches often fail to capture the plurality of user opinions,


I'm at ICML presenting GLoRe (arxiv.org/abs/2402.10963) and Teaching Reasoning with RL (arxiv.org/abs/2403.04642)! If you'd like to chat about synthetic data, process-based rewards, open-endedness, or theoretical foundations of scaling laws (or anything else) my DMs are open!
Come help us build a PRM benchmark!

Interested in benchmarking and improving Process Based Reward models (PRMs)? Come join our project to extend RewardBench by building a benchmark with fine-grained step-level feedback across many hard STEM and agentic type tasks! Project doc: docs.google.com/document/d/1S2… Discord:…

🚨 Pass by our #ICLR2024 workshop on Generative AI for Decision Making tomorrow, Saturday May 11! 🚨 We have a content-heavy day, including an exciting lineup of invited and contributed talks, as well as two poster sessions! Details: iclr.cc/virtual/2024/w…

[1/4] Introducing “A Primer on the Inner Workings of Transformer-based Language Models”, a comprehensive survey on interpretability methods and the findings into the functioning of language models they have led to. ArXiv: arxiv.org/pdf/2405.00208

In my humble opinion the recent Stream of Search paper (arxiv.org/abs/2404.03683) is truly outstanding. Everyone should give it a thorough read.

The 3 key elements of a good dataset: 1. quality 2. diversity 3. quantity You can only easily measure the last one but the performance is a sensitive function of all three. Super interesting topic ty for #longread :)!

I've finally uploaded the thesis on arXiv: arxiv.org/abs/2404.12150 It ties together a bunch of papers exploring some alternatives to RL for finetuning LMs, including pretraining with human preferences and minimizing KL divergences from pre-defined target distributions.


I was very impressed with @tomekkorbak's thesis! Some really nice insights into LLM alignment: 1) RL is not the way --> distribution matching let's us target constraints like "generate as many of these as of those" 2) fine-tuning is not the way --> PHF aligns during pre-training

I am super excited to share our Llama3 preview models (8B and 70B). I am proud to have been a part of this amazing effort over the past 8 months. We still have some super cool stuff coming up in the coming months... until then, enjoy playing with these preview models…

Had a great time during our discussion, thanks again for having me!

Today we're joined by @Dahoas1 from @GeorgiaTech to discuss the reasoning capability of language models and the potential to improve it with traditional RL methods 🎧 / 🎥 Listen to the episode at: twimlai.com/go/680. 📖 CHAPTERS 00:00 - Introduction 02:19 - RL vs RLHF…

How to define Diversity in the context of CodeLMs and Programming Languages ? 1. Diversity is positively correlated with Performance in solving a problem. 2. Shortcomings of diversity in small codeLMs. 3. Code Embedding models don't capture semantics. reshinthadithyan.github.io/blog/2023/code…






















































































































United States Trends
- 1. Bengals 74,8 B posts
- 2. Chargers 62,5 B posts
- 3. McPherson 11,2 B posts
- 4. Herbert 32,7 B posts
- 5. Joe Burrow 18,9 B posts
- 6. #BoltUp 5.144 posts
- 7. Zac Taylor 4.020 posts
- 8. #CINvsLAC 9.986 posts
- 9. #BaddiesMidwest 18,3 B posts
- 10. #SNFonNBC N/A
- 11. JK Dobbins 4.169 posts
- 12. Money Mac N/A
- 13. Harbaugh 15,1 B posts
- 14. Ladd 5.336 posts
- 15. #WhoDey 1.747 posts
- 16. Chiefs 155 B posts
- 17. Tee Higgins 3.643 posts
- 18. WWIII 156 B posts
- 19. Russia 753 B posts
- 20. Josh Allen 67,5 B posts
Who to follow
-
 Louis Castricato
Louis Castricato
@lcastricato -
 Tri Dao
Tri Dao
@tri_dao -
 Abhi Venigalla
Abhi Venigalla
@ml_hardware -
 Databricks Mosaic Research
Databricks Mosaic Research
@DbrxMosaicAI -
 Yao Fu
Yao Fu
@Francis_YAO_ -
 Yi Tay
Yi Tay
@YiTayML -
 Joseph Suarez (e/🐡)
Joseph Suarez (e/🐡)
@jsuarez5341 -
 Ofir Press
Ofir Press
@OfirPress -
 Dust
Dust
@dust4ai -
 Georgi Gerganov
Georgi Gerganov
@ggerganov -
 Aidan Gomez
Aidan Gomez
@aidangomez -
 Jay Alammar
Jay Alammar
@JayAlammar -
 SynthLabs
SynthLabs
@synth_labs -
 Ethan Perez
Ethan Perez
@EthanJPerez -
 Humanloop
Humanloop
@humanloop
Something went wrong.
Something went wrong.