
Tobias Weyand
@0xtobResearcher / Software Engineer @GoogleDeepMind working on video understanding.
Similar User

@Jimantha

@giotolias

@dlarlus

@aliathar94

@pararths

@kwangmoo_yi

@SattlerTorsten

@FuaPv

@avapamini

@Istvan_Sarandi

@NagraniArsha

@rishit_dagli

@ElorHadar

@pmh47_ml

@mihaidusmanu
Excited to share Long-Video Masked Autoencoder (LVMAE) our team just published at @NeurIPSConf! We boost the context length of video models using an adaptive decoder and a dual-masking strategy and achieve SotA on several video benchmarks. Paper: arxiv.org/abs/2411.13683

Training video understanding models on longer contexts is computationally intensive. To address this, we present a novel approach that reduces the computational load while also improving the quality of the learned representations. More at: goo.gle/4fW5aIc

Thank you @JeffDean , very much appreciate the boost! This is really a team effort with my amazing colleagues @NagraniArsha, Mingda Zhang, @raminia, Rachel Hornung, @nitesh_ai, @under_fitting, Austin Meyers, @zhouxy2017, @BoqingGo, @CordeliaSchmid, @sirotenko_m, @ZhuZhu66595

Excited that our work on Long video understanding is being featured by @GoogleAI !
Can #AI truly understand long videos? Tobias Weyand & the Google Research team are testing the limits w/ Neptune, an open-source benchmark for long video understanding. Dive into the details & see how AI tackles temporal reasoning, cause & effect, & more →goo.gle/4esTTNM
The other day I let my kids talk to Gemini live. Today my 3 year old asked my 6 year old: "Can you tell me a joke?" - 6 year old: "Sorry, I'm just a language model."
Excited to share what our team has been working on! With expanding context lengths, frontier models are able to process longer and longer videos. But how well do they really understand them? Today we release Neptune, a challenging benchmark for long video understanding.
Datasets for evaluation of long video understanding are rare. So with this in mind, today we describe Neptune, an open-source evaluation dataset that includes multiple-choice and open-ended questions for videos of variable lengths up to 15 minutes. More →goo.gle/3B41nZV

New long video understanding benchmark from my colleagues @GoogleDeepMind pushing LLMs to their limits!

Can current LLMs solve video reasoning Qs like: Over 1-hour, when does the camera holder go down stairs... ?? Watch the teaser... Can you distinguish up/down stairs - p.s. stairs are not visible when you go down any youtu.be/Ddgvr4OReL4 Hour-Long PerceptionTest VQA @eccvconf
Congratulations to the authors of "VideoPoet: A Large Language Model for Zero-Shot Video Generation" for winning one of this year's @icmlconf Best Paper Awards! #ICML2024 Paper: openreview.net/forum?id=LRkJw… Blog post: goo.gle/4atanoj


Computer Vision conference's acceptance criteria these days: #CVPR2024 #eccc2024 #AI #ComputerVision
Introducing VideoPrism, a single model for general-purpose video understanding that can handle a wide range of tasks, including classification, localization, retrieval, captioning and question answering. Learn how it works at goo.gle/49ltEXW
New work from my colleagues: NeRF without the need for SfM to obtain camera poses!

My 5yo daughter is already coming up with image generation prompts to test generalization beyond the training data: "Unicorn kitty in space", "Princess astronaut". Or maybe she's just asking me to print coloring pages for her, idk.
Introducing SANPO, a multi-attribute video dataset for outdoor human egocentric scene understanding composed of both real-world and synthetic data, including depth maps and video panoptic masks with a wide variety of semantic class labels. Read more → goo.gle/3ZISInU
I just spent 3 days with dear friends, all of whom have kids ages 8mo to 4y. Something I need to get off my chest about being a parent of young kids and the culture we live in:

New work from our team. We studied how various video foundation models perform on different benchmarks and with different adaptation methods.

VideoGLUE: Video General Understanding Evaluation of Foundation Models paper page: huggingface.co/papers/2307.03… We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action…

Very clear and concise tutorial on transformers

My Transformer tutorial slides are now available at lucasb.eyer.be/transformer I'll append recordings to this thread as I get them. If you want to use some of the slides for your lecture, you may, as long as you credit me. If you'd like me to give the lecture: maybe; e-mail me.

Our team is looking for student researchers to work on foundation video models. You'll work with @BoqingGo and @0xtob DM if you're interested
The Universal Image Embedding Challenge (kaggle.com/competitions/g…) of our @eccvconf Instance-Level Recognition workshop (ilr-workshop.github.io/ECCVW2022/) is online now! The workshop is co-organized by @0xtob and @giotolias among others.

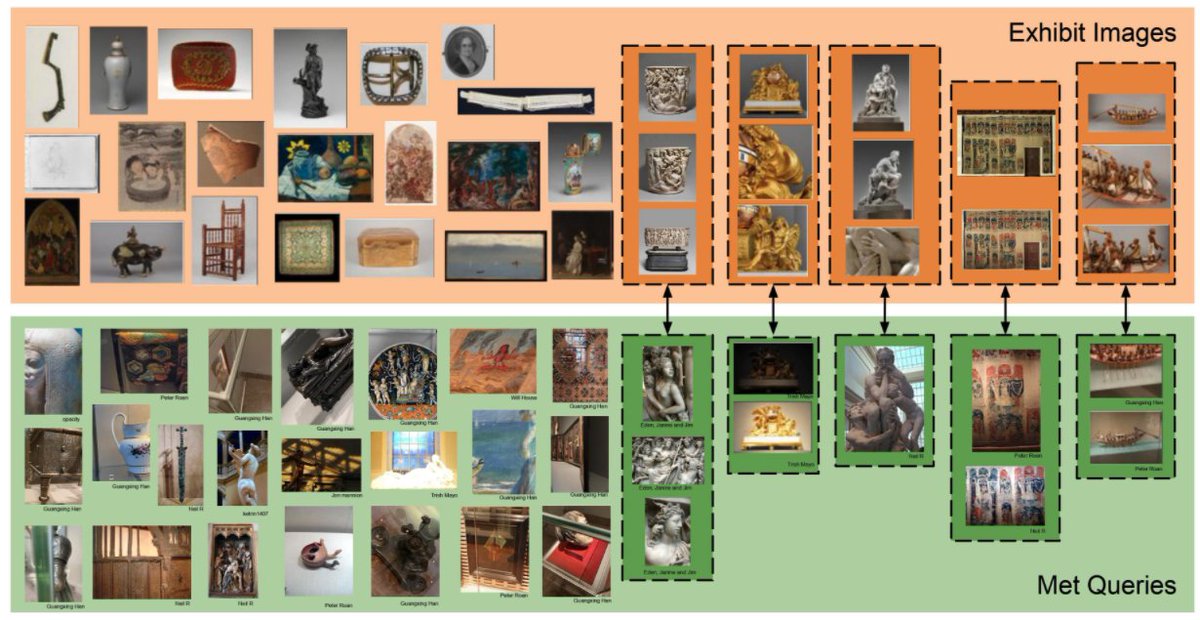
🖼️The Met Dataset: a large-scale dataset for instance-level recognition in the artwork domain. Consists of 400k images from more than 224k classes. It can be used for research in few-shot learning, self-supervised and supervised contrastive learning. paperswithcode.com/dataset/met






































































































United States Trends
- 1. Good Monday 41,5 B posts
- 2. Big Bass Xmas Extreme N/A
- 3. Victory Monday N/A
- 4. #MondayVibes 2.319 posts
- 5. #MARK_Fraktsiya 255 B posts
- 6. Immanuel 4.506 posts
- 7. Carti 45 B posts
- 8. Trump 2028 7.334 posts
- 9. Acheron 6.130 posts
- 10. Mona Lisa 37,9 B posts
- 11. Geno 18,1 B posts
- 12. Alex Bruesewitz 10 B posts
- 13. Sam Howell 6.186 posts
- 14. Burna 28,8 B posts
- 15. Yellowstone 12,1 B posts
- 16. #BaddiesMidwest 14,7 B posts
- 17. #GoPackGo 9.822 posts
- 18. Klay 13,9 B posts
- 19. Ernie 4.735 posts
- 20. OpTic 7.995 posts
Who to follow
-
 Noah Snavely
Noah Snavely
@Jimantha -
 Giorgos Tolias
Giorgos Tolias
@giotolias -
 Diane Larlus
Diane Larlus
@dlarlus -
 Ali Athar
Ali Athar
@aliathar94 -
 pararth
pararth
@pararths -
 Kwang Moo Yi
Kwang Moo Yi
@kwangmoo_yi -
 Torsten Sattler
Torsten Sattler
@SattlerTorsten -
 Pascal Fua
Pascal Fua
@FuaPv -
 Ava Amini
Ava Amini
@avapamini -
 István Sárándi
István Sárándi
@Istvan_Sarandi -
 Arsha Nagrani
Arsha Nagrani
@NagraniArsha -
 Rishit Dagli
Rishit Dagli
@rishit_dagli -
 Hadar Averbuch-Elor
Hadar Averbuch-Elor
@ElorHadar -
 Paul Henderson
Paul Henderson
@pmh47_ml -
 Mihai Dusmanu
Mihai Dusmanu
@mihaidusmanu
Something went wrong.
Something went wrong.