
Minchan Jeong
@mc_jeongCurrently at @kaist_ai for Ph.D course. B.S at physics and mathematics in SNU.
Similar User

@jinheonbaek

@raymin0223

@hyeonmin_Lona

@hayeonlee_ai

@hoyeon_chang

@kimtaehyeon610

@mkkang_1133

@kim_sungnyun

@nick_jhlee

@seeyoojm

@sihyun_yu

@jaeh0ng_yoon

@seanie_12

@SeonghyeonYe

@nlp_eunhwanpark
🚀 Excited to share our latest research @GoogleDeepMind on ♻️Recursive Transformers! We make smaller LMs by "sharing parameters" across layers. A novel serving paradigm, ✨Continuous Depth-wise Batching, with 🏃Early-Exiting could significantly boost their decoding speed! 🧵👇


🌍 GenCast update! 🌍 New highlights include 0.25° resolution, predicting extreme weather, cyclones, and wind power production. Across all our evaluations, GenCast is better than the world’s top operational medium-range weather forecast New paper: arxiv.org/abs/2312.15796… 🧵 1/8

Llama 3 just changed the LLM game. People are finding wild use cases at GPT-4 level. There is a massive movement in the open source community. 10 examples (and ways to use Llama 3):



[1/3] Ever wondered how Sharpness-Aware Minimization (SAM) beats SGD? 🤔💡Sharpness is not the only answer! Our latest #NeurIPS2023 paper provides a new perspective that applies to non-smooth loss landscapes. 🚀 🔗: arxiv.org/pdf/2310.07269…


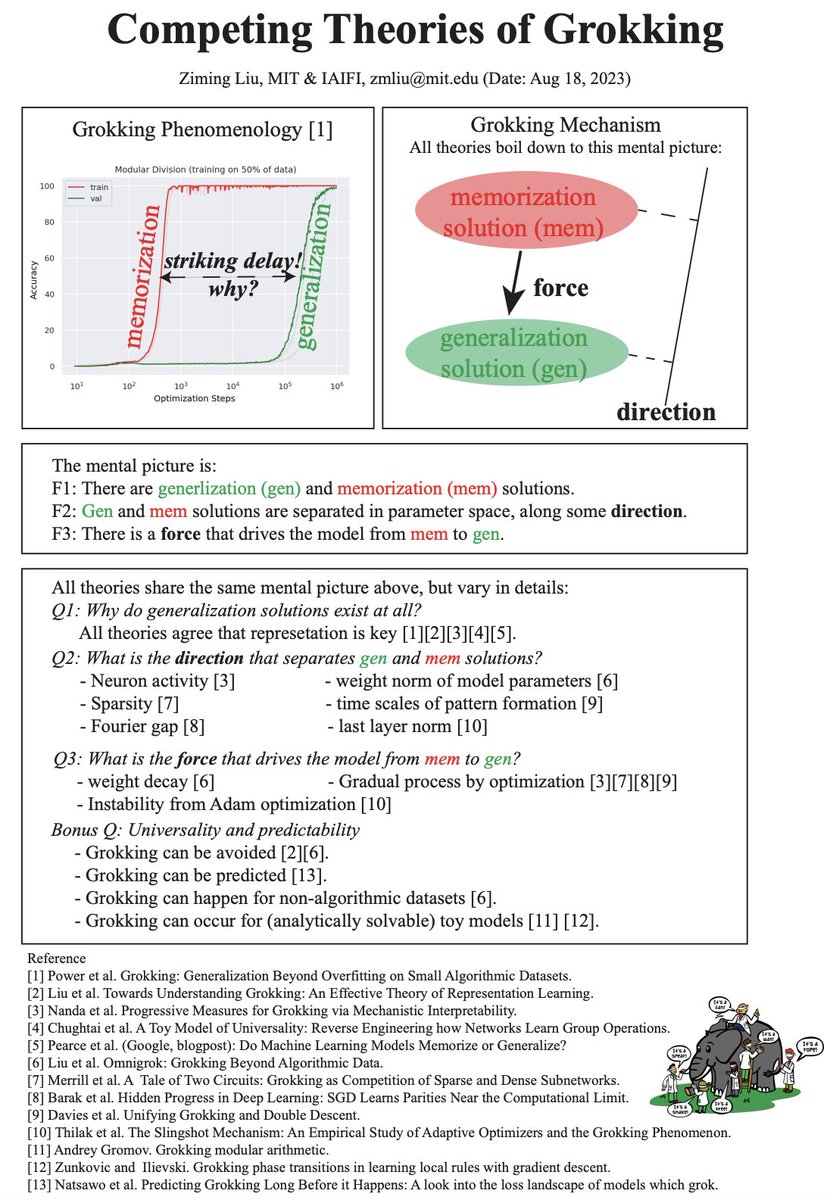
Deep learning has many mysterious phenomena, and grokking is one of the extreme. Want to catch up with the grokking literature? I've compiled a one-page summary of what's going on in the grokking world. Enjoy! :-) kindxiaoming.github.io/pdfs/grokking_…

A new 150 pages review paper on the applications of machine learning in finance. #machinelearning #finance papers.ssrn.com/sol3/papers.cf…


Towards Understanding the Dynamics of Gaussian--Stein Variational Gradient Descent. (arXiv:2305.14076v1 [math.ST]) ift.tt/0ofyG9p

몰로코 서울오피스에서 저와 함께 ML 엔지니어로 일하실 분을 찾습니다! JD를 요약하자면, 수학적 통찰에 기반한 딥러닝의 이해가 깊으며 개발도 잘 하실 수 있는 분이면 좋습니다. JD & 지원 페이지: moloco.com/open-positions…

something that i should definitely work on much more…

Giving good talks is a core skill for academics. It's learnable! Here's how I approach mine. drive.google.com/file/d/1SHiJs6…

Say you have an optimization algorithm, and you want to find its convergence proof. Do you want computer assistance in finding the proof? If so, check out Shuvo's talk given at the 2023 PEP Workshop, UCLouvain! 🇧🇪

🎥 Excited to share the YouTube video of my presentation at the 2023 Workshop on Performance Estimation Problems (PEP), UCLouvain, Belgium! 🇧🇪 Check out my talk titled "Design and analysis of first-order methods via nonconvex QCQP frameworks" at youtu.be/unDornjkpRU (1/5)

Implemented stable diffusion (DDPM by Ho & @pabbeel ) from scratch and that's the best thing I've done in the past 36 hrs 💪




Penrose라는 것이 있었군요. “Penrose is a platform that enables people to create beautiful diagrams just by typing mathematical notation in plain text.” penrose.cs.cmu.edu




Fine-tuning can make models like CLIP less robust. A simple idea is highly effective at mitigating that: averaging zero-shot and fine-tuned models. Check out our work introducing WiSE-FT, just accepted to CVPR! Paper: arxiv.org/abs/2109.01903 Code: github.com/mlfoundations/…


I tell new PhD students to pick a research topic according to three criteria: (1) the problem should be important, (2) it should have a reasonable chance of being solvable, and (3) you should personally have a unique edge.

The only writing advice I've ever given: write the book that nobody else can write. If there is a single person on Planet Earth who can write anything close to it, find a hobby. Generalize to every line you write. Those who didn't follow such a guideline are punished by ChatGPT.

quiver version 1.1.0 is now available: q.uiver.app Includes: - Colours (for arrows and labels) - Label positioning - Asymmetric shortening for arrows - Pullback/pushout corner variant - Optional diagram centring in LaTeX export - Improved LaTeX output




Are you a PhD student struggling to get a job or internship? Jealous of the success of your more-cited peers? More concerned with your career than doing good science? Here is a thread of eight invaluable techniques to "improve" your publication and citation metrics. vv 🧵🧵🧵 vv

Intuition why adding Gaussian noise to parameters is nice for optimization: when we integrate/marginalize over the noise, we convolve/blur the loss surface with a Gaussian kernel -> making it smoother






























































United States Trends
- 1. Trevor Lawrence 16 B posts
- 2. Bengals 32,1 B posts
- 3. Pickens 12,8 B posts
- 4. Seahawks 20,5 B posts
- 5. Jets 41,9 B posts
- 6. Texans 16,9 B posts
- 7. Titans 22,6 B posts
- 8. Jags 6.350 posts
- 9. #Steelers 10,6 B posts
- 10. #HereWeGo 5.692 posts
- 11. Tomlin 3.581 posts
- 12. Al-Shaair 10,8 B posts
- 13. Falcons 14,7 B posts
- 14. Kirk Cousins 1.723 posts
- 15. Drake Maye 3.816 posts
- 16. Rodgers 8.576 posts
- 17. Leonard Williams 3.298 posts
- 18. #RaiseHail 6.048 posts
- 19. $CUTO 12,8 B posts
- 20. Calvin Austin 1.271 posts
Who to follow
-
 Jinheon Baek
Jinheon Baek
@jinheonbaek -
 Sangmin Bae
Sangmin Bae
@raymin0223 -
 Hyeon min Yun
Hyeon min Yun
@hyeonmin_Lona -
 Hayeon Lee
Hayeon Lee
@hayeonlee_ai -
 Hoyeon Chang
Hoyeon Chang
@hoyeon_chang -
 Taehyeon Kim
Taehyeon Kim
@kimtaehyeon610 -
 Minki Kang
Minki Kang
@mkkang_1133 -
 Sungnyun Kim
Sungnyun Kim
@kim_sungnyun -
 Junghyun Lee
Junghyun Lee
@nick_jhlee -
 Jaemin Yoo
Jaemin Yoo
@seeyoojm -
 Sihyun Yu
Sihyun Yu
@sihyun_yu -
 Jaehong Yoon
Jaehong Yoon
@jaeh0ng_yoon -
 Seanie Lee
Seanie Lee
@seanie_12 -
 Seonghyeon Ye
Seonghyeon Ye
@SeonghyeonYe -
 Eunhwan Park
Eunhwan Park
@nlp_eunhwanpark
Something went wrong.
Something went wrong.