
Konstantinos Kontras
@k_kontrasHow to use multiple sources/modalities on a neural network? I am trying to figure that out, join me!
Similar User

@biomed_kuleuven

@Christo76907360

@ExpORL_KULeuven

@andreawwenyi

@Robborger

@NeuroSc1

@ChinweubaC2
🌟 New preprint: "Multimodal Fusion Balancing Through Game-Theoretic Regularization"! We frame fusion as a game, where modalities act as players competing to influence the output, setting new benchmarks in multimodal learning. 🚀 📄arxiv.org/pdf/2411.07335

Quite an interesting extension of LoRA!

Are you LoRA fine-tuning LLMs and looking for easy ways to get improvements in accuracy? And also Bayesian uncertainty on top for free? Then check our recent work, accepted @neurips24fitml workshop! arxiv.org/abs/2411.04421

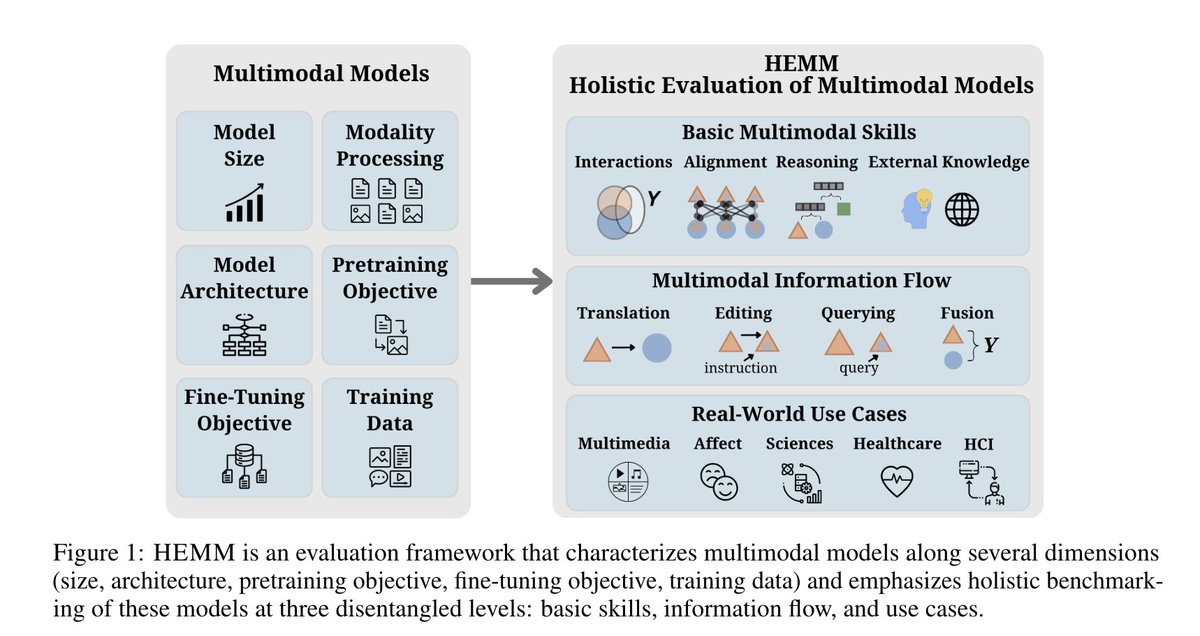
Excited to release HEMM (Holistic Evaluation of Multimodal Foundation Models), the largest and most comprehensive evaluation for multimodal models like Gemini, GPT-4V, BLIP-2, OpenFlamingo, and more. HEMM contains 30 datasets carefully selected and categorized based on: 1. The…

Scientific publishing etiquette: 1. Scientists should be allowed to publish their research. 2. Publications should include the names of all contributors in the author list. 3. Junior contributors who actually did the work should be placed at the beginning of the author list. 4.…
Seriously though, you should let your researchers put their name on papers that describe their research. Or else what you pay them amounts to hush money. I'm sure they're pretty pissed about it.

🌟 Big News from @biomed_kuleuven! Our group has a new website! Get direct access to our most recent research, updates, and projects. What you’ll find: 🔬 Latest Publications 🌐 News Updates 📊 Detailed Project Overviews 🔗 Check us out now: biomed-kuleuven.web.app

What are we really decoding? Unveiling biases in EEG-based decoding of the spatial focus of auditory attention My first journal paper got published in the Journal of Neural Engineering🙂 iopscience.iop.org/article/10.108… A joint research project of @ExpORL_KULeuven and @biomed_kuleuven
Very interesting work on multimodal fusion shown at @iclr_conf DEQ for fusion, showing recurrent fusion aiming on reaching equilibrium. I would be curious to see how it achieves on multimodal competition, should it balance learning among modalities? openreview.net/forum?id=bZMyH…

Explored @iclr_conf results aligning with my past training idea. Batch training with randomly missing modalities to enhance such robustness. Curious to see comparisons with CoRe-Sleep's approach of adding local unimodal losses. 🤔 #Multimodal #Gazelle openreview.net/pdf?id=b3f7FRU…


In the best papers, the models are often just vehicles for larger ideas. A paper may be teaching us about distribution shifts, heteroscedasticity, or some other larger concept, simply expressed through the models (LLMs, ResNets, SVMs, ...) that happen to be popular at the time.

Information Theory is awesome so here is a TL;DR about Shanon's entropy. This field is about quantifying the amount "of information" contained in a signal and how much can be transmitted under certain conditions. 1/11

⚠️A widespread confusion: calibration of predictors, as measured by expected calibration error, does not control completely that the predictor gives perfect probabilities P(y|X): A predictor may be overconfident on some individuals and underconfident on others 🧵 1/10

This seems similar modality competition in multimodal. Single objective ensemble would be affected from Occam's razor and also one model would intervene to the update steps of the others. Interesting work, it's very helpful to see evidence of the problem in ensembles!

In the meantime, check out our paper: “Joint Training of Deep Ensembles Fails Due to Learner Collusion” With amazing coauthors @JonathanICrabbe, @tennisonliu & @MihaelaVDS arxiv.org/abs/2301.11323

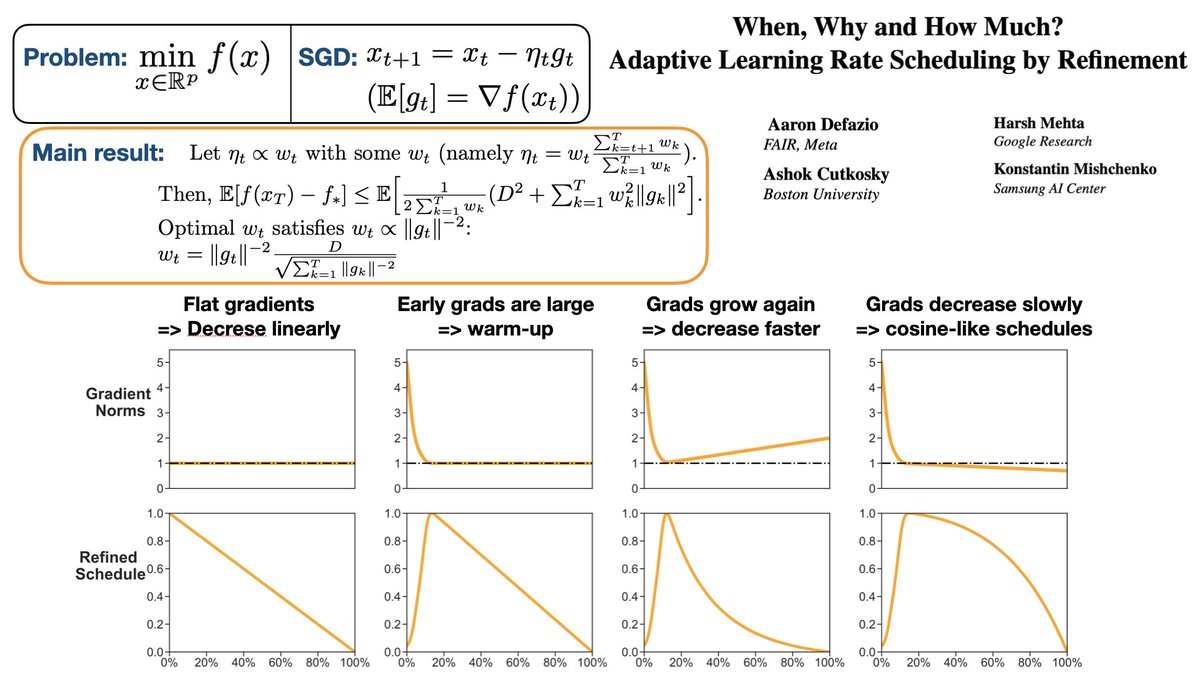
Why do we need warm-up, cosine annealing, and other learning rate schedules when training with gradient descent? It turns out it's all about how gradient norms change over time. E.g., large norms at the start => warm-up. Slow decrease => cosine. Paper: arxiv.org/abs/2310.07831 0/4
Today we had one of the most alive and full events of #FlandersAI. It was a pleasure to present some preliminary results of our work on #multimodal balancing. More to come soon!

A well-grounded mathematical framing can be found in our ICLR Poster, detailing the link between these notions and how to study them empirically 2/2
Our poster this afternoon at #ICLR2023: why calibration is not enough, and how to estimate the remainder to quantify uncertainty Indeed, a classifier can be over-confident on some individuals and under-confident on others. How to separate this error from irreducible uncertainty?

I am glad to share that our team with @DariusSchaub , @mayarbali and @aksu_fatihh was among the winning teams of the #OxML challenge on carcinoma classification from biopsies! Sometimes Bayes is all you need!

Join the NEonatal Sleep Talks #NEST2023 to explore neonatal and early infant #sleep. Co-organized by @MaartenDeVos19! Submit abstract by July 14th. @ResearchSleep @Newborn_brain @AASM #Biomed cam-pgmc.ac.uk/courses/nest-2…

This week many of our group is in #Rodos for #ICASSP 2023! A grand challenge, a workshop and 4 papers to present! Join us to spark the discussion #Biomed
Virtually every ML paper is a method comparison, where the authors almost always have a "horse in the race". This is bad for science. We need to diversify and embrace empirical studies that are not incentivized to push a particular narrative or make a specific method look good.
🗣 We are proud to announce that our postdoc @GeirnaertSimon received a postdoc grant from @FWOVlaanderen to continue his research on signal processing algorithms for attention decoding in #EEG! We will be lucky to have him in our team for 3 more years! #Biomed #FWO















































































United States Trends
- 1. Army 447 B posts
- 2. Dylan Harper 3.957 posts
- 3. Jalen Johnson 1.786 posts
- 4. Pat Adams N/A
- 5. George Stephanopoulos 100 B posts
- 6. Lamont Butler 1.030 posts
- 7. ABC News 88,2 B posts
- 8. Sixers 8.680 posts
- 9. #SNME 21,5 B posts
- 10. Dennis 47,7 B posts
- 11. Dame 48,8 B posts
- 12. Melton 10,8 B posts
- 13. #drwfirstgoal N/A
- 14. Horvath 1.525 posts
- 15. Bryson Daily 1.034 posts
- 16. Christie 15,3 B posts
- 17. Marshall 23,3 B posts
- 18. Capela 1.129 posts
- 19. Gary Danielson N/A
- 20. Jean Carroll 21,8 B posts




Something went wrong.
Something went wrong.