

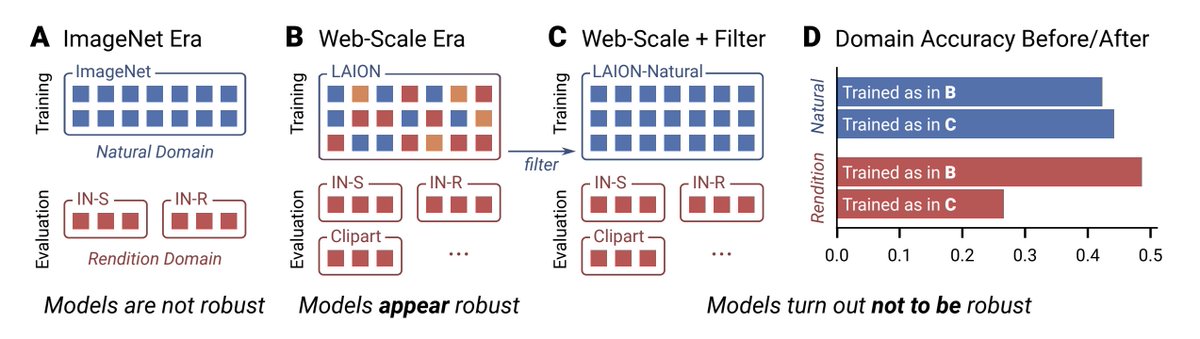
🎉 New Pre-print! 🎉 Do CLIP models truly generalize to new, out-of-domain (OOD) images, or are they only doing well because they’ve been exposed to these domains in training? Our latest study reveals that CLIP’s ability to “generalize OOD” may be more limited than previously…

🧵Join us for a short tour of how a large-scale MEG dataset collected during active vision made us question it all. New work with @carmen_amme @PhilipSulewski @EelkeSpaak @martin_hebart @konigpeter biorxiv.org/content/10.110…

Why training a linear probe on top of a pretrained representation can solve so many different tasks? We take an identifiability viewpoint and show when/why your pretrained model actually learned ground truth factors of variations in your data! arxiv.org/abs/2410.21869

🎭Recent work shows that models’ inductive biases for 'simpler' features may lead to shortcut learning. What do 'simple' vs 'complex' features look like? What roles do they play in generalization? Our new paper explores these questions. arxiv.org/pdf/2407.06076 #Neurips2024


PhD then: “We validate our method on a large-scale dataset of hundreds of images.” PhD now: “We validate our method on 10 different modalities, 15 domains, 20 scenarios, 25 tasks, and 200 languages, each with millions of testing examples”.

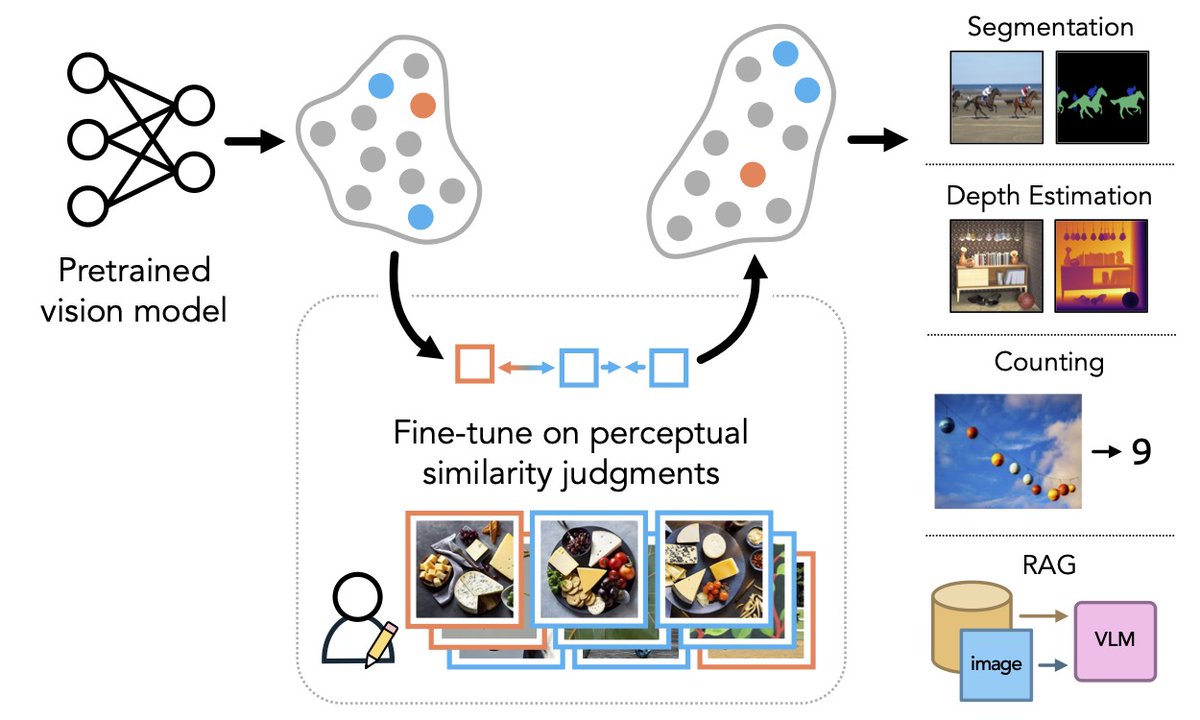
What happens when models see the world as humans do? In our #NeurIPS2024 paper we show that aligning to human perceptual preferences can *improve* general-purpose representations! 📝: arxiv.org/abs/2410.10817 🌐: percep-align.github.io 💻: github.com/ssundaram21/dr… (1/n)

1/ 🚨New preprint out now! 🚨 We present a data-driven method using GANs to discover interpretable and novel tuning dimensions in IT neurons in macaques and can be used to control visual perception! biorxiv.org/content/10.110…

Stable, chronic in-vivo recordings from a fully wireless subdural-contained 65,536-electrode brain-computer interface device biorxiv.org/content/10.110… #BCI #NeuroTech


Nicole mentally imagined images from her past inside an MRI machine, and we used neuroAI to reconstruct those memories from her brain scans. My collab w/ Fujifilm connecting science & art to visualize the intangible aspects of memory and thought! youtube.com/watch?v=EFrU-K…

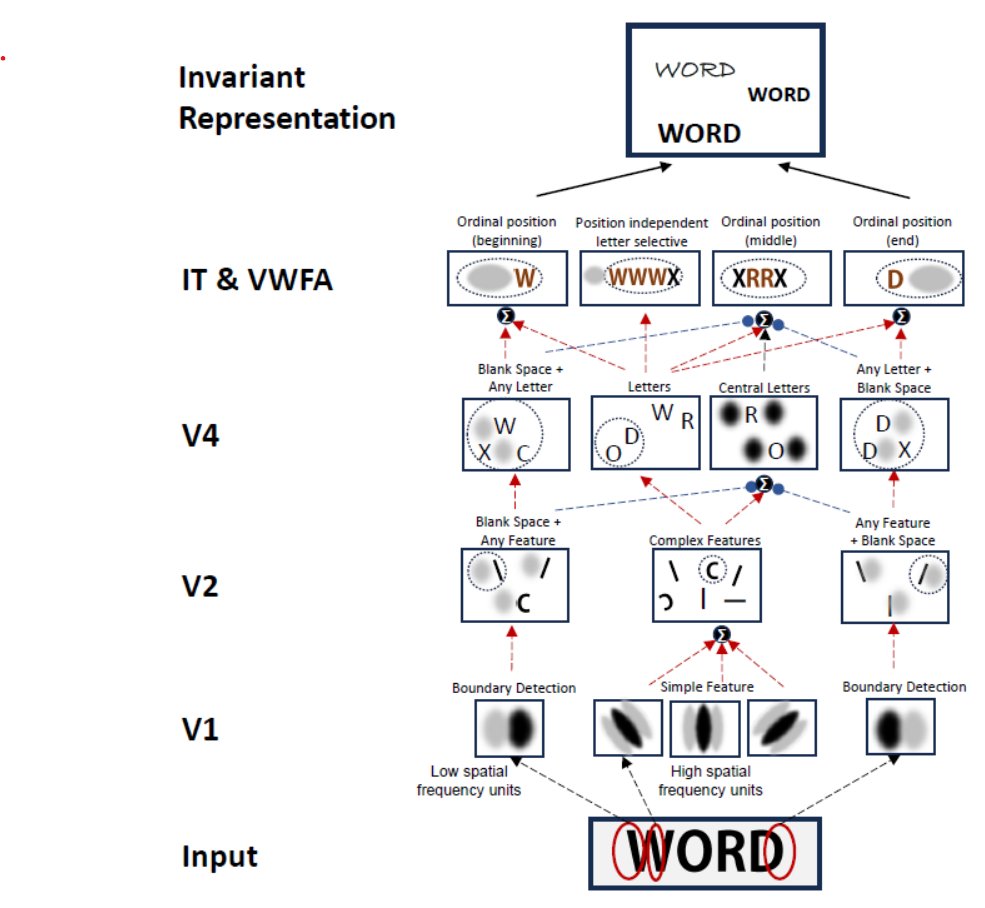
🚨 Publication Alert! #PLOSCompBio: Cracking the neural code for word recognition in convolutional neural networks dx.plos.org/10.1371/journa… We (@StanDehaene) have uncovered how convolutional neural networks recognize words, and the results are fascinating.

What aspects of human knowledge are vision models missing, and can we align them with human knowledge to improve their performance and robustness on cognitive and ML tasks? Excited to share this new work led by @lukas_mut! 1/10


Is expecting something the same as attending to something? Very interesting study on the differences and commonalities between preparing for something probable and preparing for something relevant by Peñalver and Ruz and colleagues @cimcyc biorxiv.org/content/10.110…

Can we gain a deep understanding of neural representations through dimensionality reduction? Our new work shows that the visual representations of the human brain need to be understood in high dimensions. w/ @RajThrowaway42 & Brice Ménard. arxiv.org/abs/2409.06843#

do large-scale vision models represent the 3D structure of objects? excited to share our benchmark: multiview object consistency in humans and image models (MOCHI) with @xkungfu @YutongBAI1002 @thomaspocon @_yonifriedman @Nancy_Kanwisher Josh Tenenbaum and Alexei Efros 1/👀


We know that middle layers from LLMs best predict brain responses to natural language. But why? In our new short paper (arxiv.org/abs/2409.05771), we show that this prediction performance closely aligns with a peak in the ✨intrinsic dimensionality✨of the LLM's layers. (1/6)

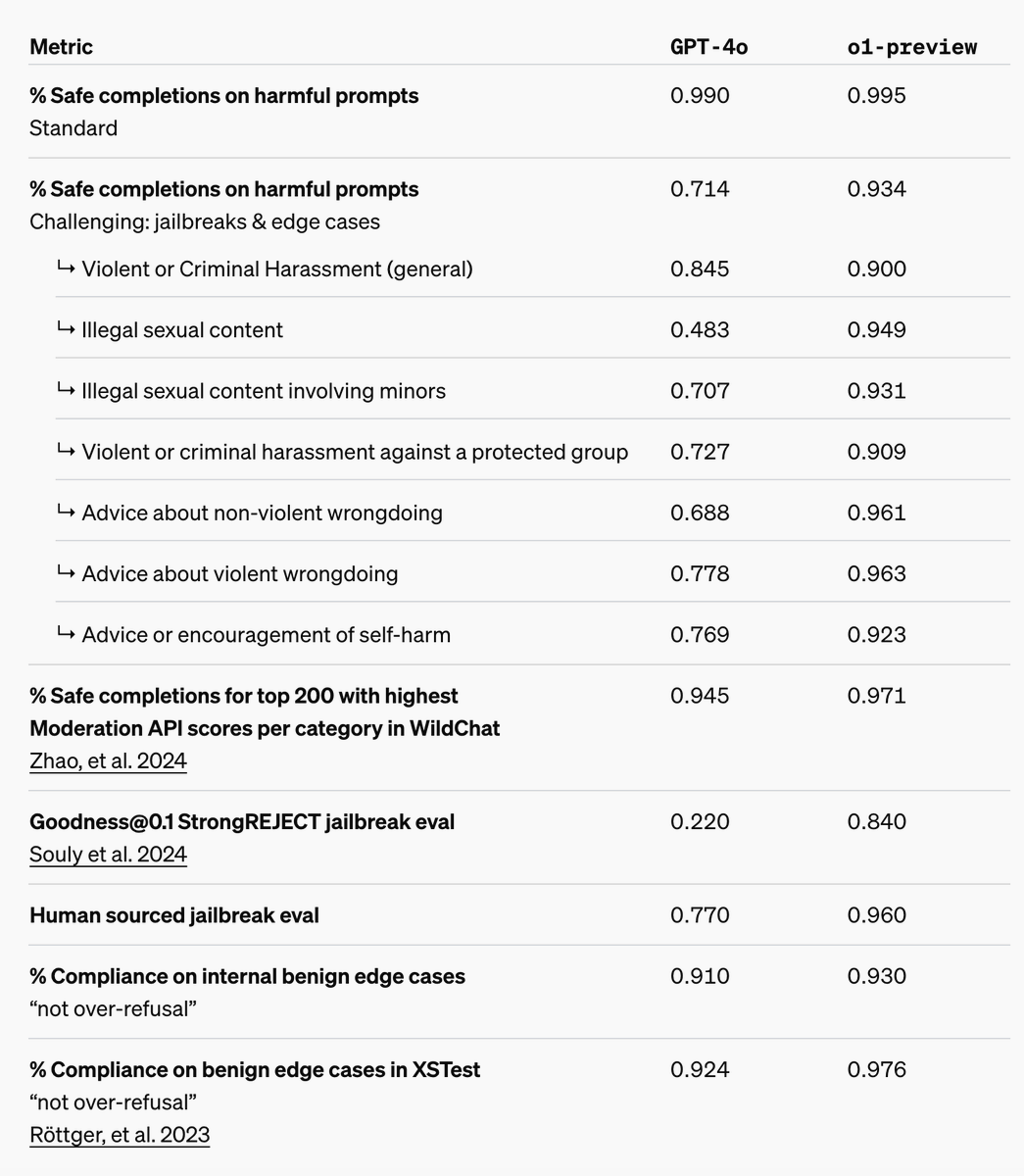
🍓 Finally o1 is out - our first model with general reasoning capabilities. Not only it achieves impressive results on hard, scientific tasks, but also it gets significantly improved on safety and robustness. openai.com/index/learning… We found reasoning in context about safety…


Attention is awesome! So we (@NeuroLei @arisbenjamin @ml_tuberlin @KordingLab and #NeuroAi) built a biologically inspired model of visual attention and binding that can simultaneously learn and perform multiple attention tasks 🧠 Pre-print: doi.org/10.1101/2024.0… A 🧵...

How does our brain allow us to make sense of our visual world? Work led by @OliverContier w/ @Chris_I_Baker now out in @NatureHumBehav provides support for a theoretical framework of behaviorally-relevant selectivity beyond high-level categorization. 🧵 x.com/OliverContier/…

Hugely excited that this work with @martin_hebart and @Chris_I_Baker is now out in @NatureHumBehav !!! By moving from a category-focused to a behaviour-focused model, we identified behaviourally relevant object information throughout visual cortex. nature.com/articles/s4156…

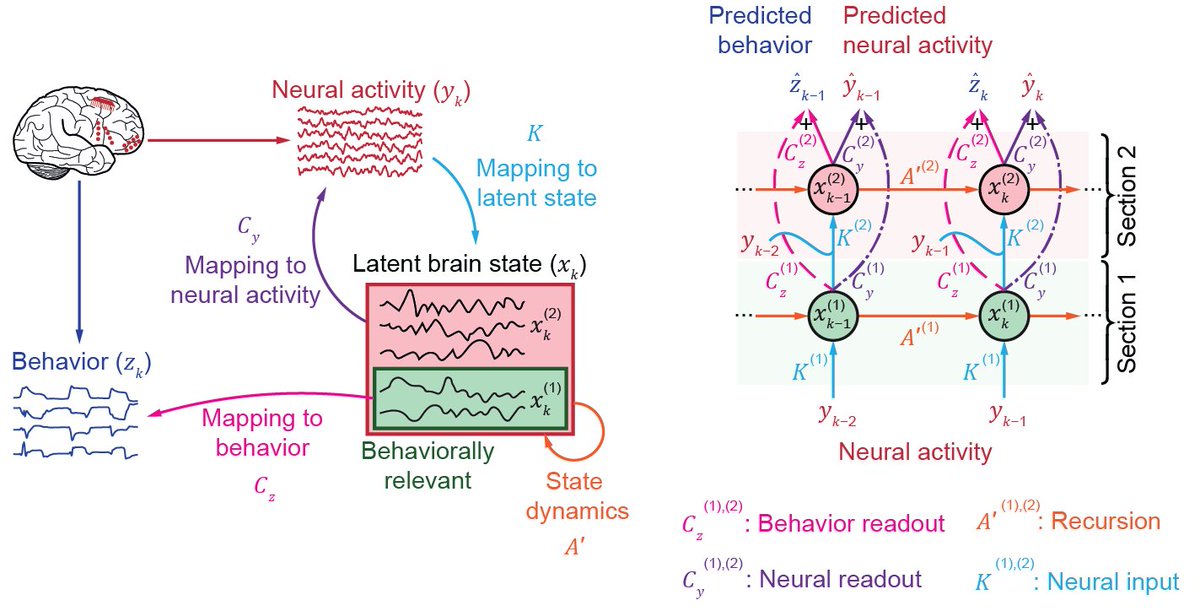
New in @NatureNeuro, we present DPAD, a deep learning method for dynamical modeling of neural-behavioral data & dissociating behaviorally relevant dynamics. It enables diverse neurotech & neuroscience use-cases. 👏@omidsani 💻github.com/ShanechiLab/DP… 📜nature.com/articles/s4159… 🧵⬇️

Diffusion Models Are Real-Time Game Engines arxiv.org/abs/2408.14837 gamengen.github.io Amazing how much Neural Game Engines have improved over the years using advances in Generative AI. 2018: VAE+RNN latent world models 2024: Stable Diffusion trained to predict next frame


























































United States Trends
- 1. McDonald 51,1 B posts
- 2. #AskFFT N/A
- 3. Mike Johnson 55,2 B posts
- 4. #RollWithUs N/A
- 5. Good Sunday 71,2 B posts
- 6. #sundayvibes 8.446 posts
- 7. Go Bills 5.045 posts
- 8. Big Mac 5.090 posts
- 9. Coke 34 B posts
- 10. #AskZB N/A
- 11. Tillman 1.885 posts
- 12. Sunday Funday 5.107 posts
- 13. Happy Founders N/A
- 14. #ATEEZ_1stDAESANG 12,7 B posts
- 15. Jon Jones 302 B posts
- 16. NFL Sunday 5.628 posts
- 17. CONGRATULATIONS ATEEZ 22,6 B posts
- 18. Founders Day 1.160 posts
- 19. McDs N/A
- 20. Higgins 9.830 posts
Something went wrong.
Something went wrong.