
Similar User

@frances_ryta

@Steviraehobson3

@JUDBIANCFARMS

@webPegaz

@clu007

@CryptoneDon

@Kierans_stuff

@Northeasttowba1

@inkjewels

@gurbeyhiz

@irwinvalntyne

@OscarMwandu1

@HoanHyInvest

@Russell_Wilkey

@kellierosanna

Microsoft released a groundbreaking model that can be used for web automation, with MIT license 🔥👏 OmniParser is a state-of-the-art UI parsing/understanding model that outperforms GPT4V in parsing. 👏

Planning GenAI Right: Your Blueprint for Reliable Business Transformation 🚀 For enterprises 🏢, reliability is essential when integrating GenAI into business processes 🤖. The paper "LLMs Still Can’t Plan; Can LRMs?" reveals that even advanced models like OpenAI’s o1 face…

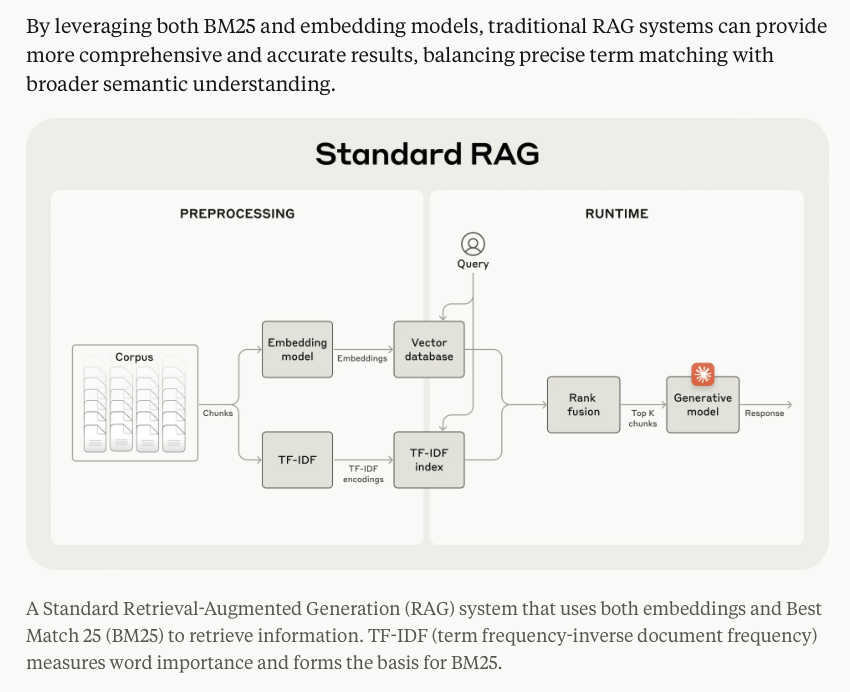
♥️ this writeup from @AnthropicAI for so many reasons: • Reiterating bm25 + semantic retrieval is standard RAG • Not just sharing what worked but also what didn't work • Evals on various data (code, fiction, arXiv) + embeddings • Breaking down gains from each step More of…




The most comprehensive overview of LLM-as-a-Judge! READ IT‼️ "Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)” summarizes and analyzes two dozen papers on different LLM as Judge approaches.🤯 TL;DR; ⚖️ Direct scoring is suitable for objective evaluations, while…

Here's an engaging intro to evals by @sridatta and @iamwil They've clearly put a lot of care and effort into it, where the content is well organized with plenty of illustrations throughout. Across 60 pages, they explain model vs. system evals, vibe checks and property-based…



Thats Big! ⛰️ FRAMES released by @GoogleAI! FRAMES is a comprehensive evaluation dataset designed to test Retrieval-Augmented Generation (RAG) Applications on factuality, retrieval accuracy, and reasoning. It includes multi-hop questions that demand sophisticated retrieval and…

🚨 Why Are So Many GenAI Projects Failing? 📉 And How to Fix Them! 💡 GenAI has huge potential, but many projects fall short. Why? 🤔 Here are 6 common reasons and learn actionable solutions to avoid them: 1️⃣ Treating GenAI as simple automation 🤖 2️⃣ Over-relying on a single…

After years eclipsed by its big brothers, gpt-2 resurgant? 🤔

The hype for finding out what is "gpt2-chatbot" on lmsys chatbot arena is real 😅

arxiv.org/abs/2404.16811 "our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle."
Easily Fine-tune @AIatMeta Llama 3 70B! 🦙 I am excited to share a new guide on how to fine-tune Llama 3 70B with @PyTorch FSDP, Q-Lora, and Flash Attention 2 (SDPA) using @huggingface build for consumer-size GPUs (4x 24GB). 🚀 Blog: philschmid.de/fsdp-qlora-lla… The blog covers: 👨💻…


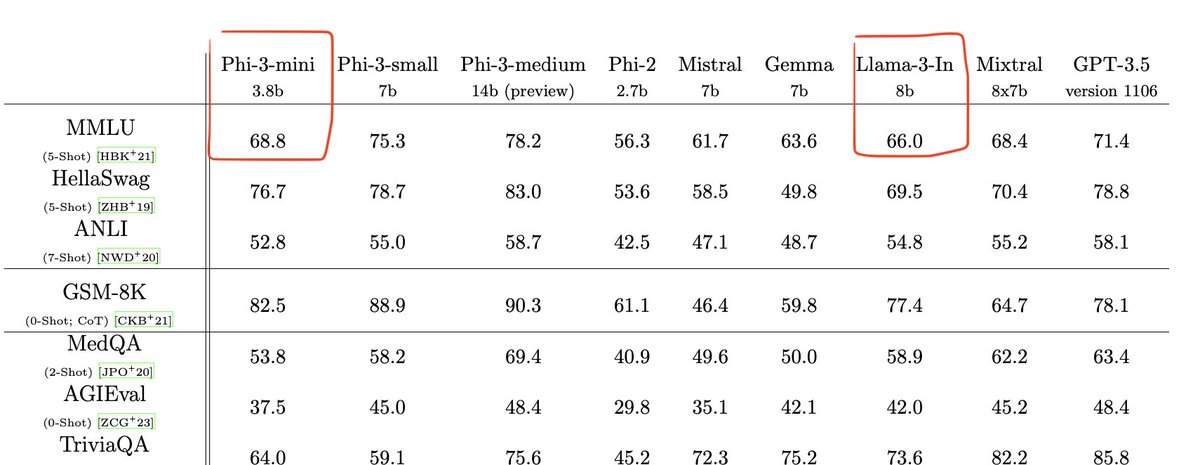
Phi-3 has "only" been trained on 5x fewer tokens than Llama 3 (3.3 trillion instead of 15 trillion) Phi-3-mini less has "only" 3.8 billion parameters, less than half the size of Llama 3 8B. Despite being small enough to be deployed on a phone (according to the technical…
I can't believe microsoft just dropped phi-3 less than a week after llama 3 arxiv.org/abs/2404.14219. And it looks good!
Just learned that the RedPajama-V2 pretraining dataset is actually 30T tokens. 2x the size used for Llama 3 🤯 github.com/togethercomput…
"... do SSMs truly have an advantage (over transformers) in expressive power for state tracking? Surprisingly, the answer is no ... Thus, despite its recurrent formulation, the 'state' in an SSM is an illusion" 🎤✋🔥 arxiv.org/abs/2404.08819

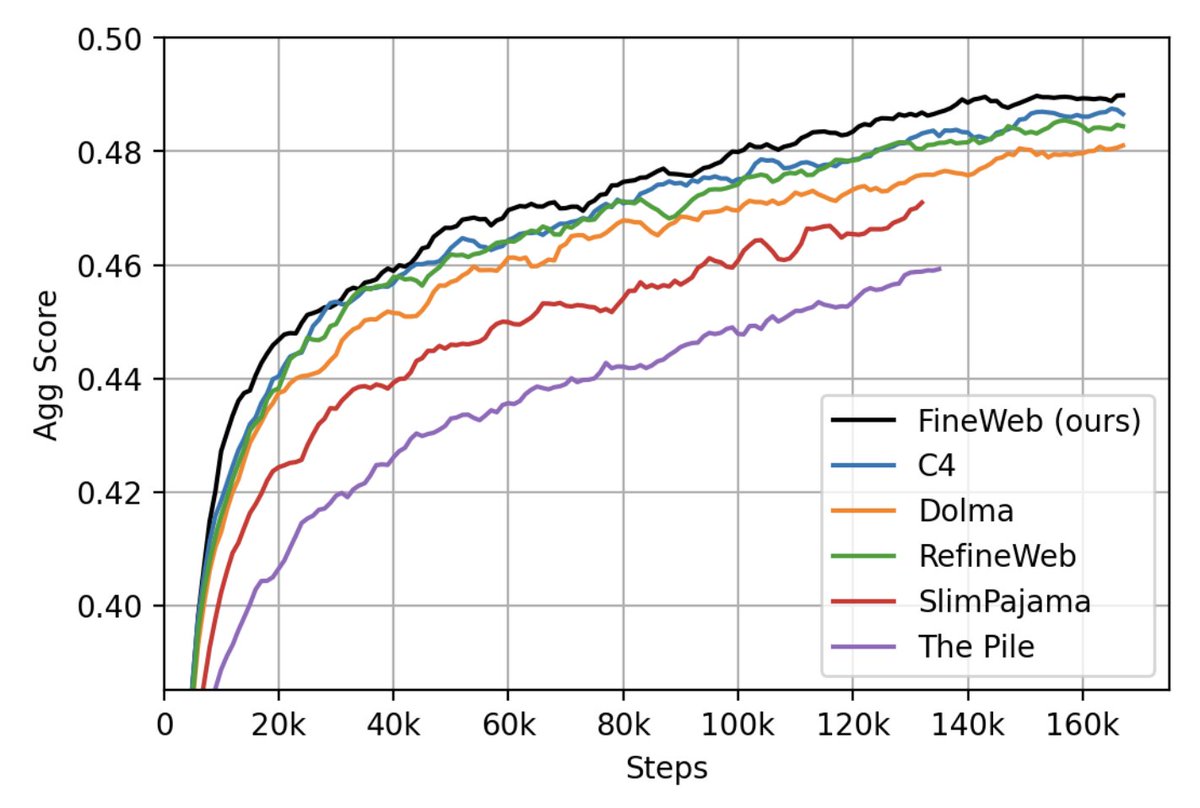
Llama3 was trained on 15 trillion tokens of public data. But where can you find such datasets and recipes?? Here comes the first release of 🍷Fineweb. A high quality large scale filtered web dataset out-performing all current datasets of its scale. We trained 200+ ablation…

We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!

Introducing Meta Llama 3: the most capable openly available LLM to date. Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes. Today's release includes the first two Llama 3…
Meta Llama 3 70B Instruct in Hugging Chat! Go have fun! huggingface.co/chat/models/me…">huggingface.co/chat/models/me… huggingface.co/chat/models/me…">huggingface.co/chat/models/me…


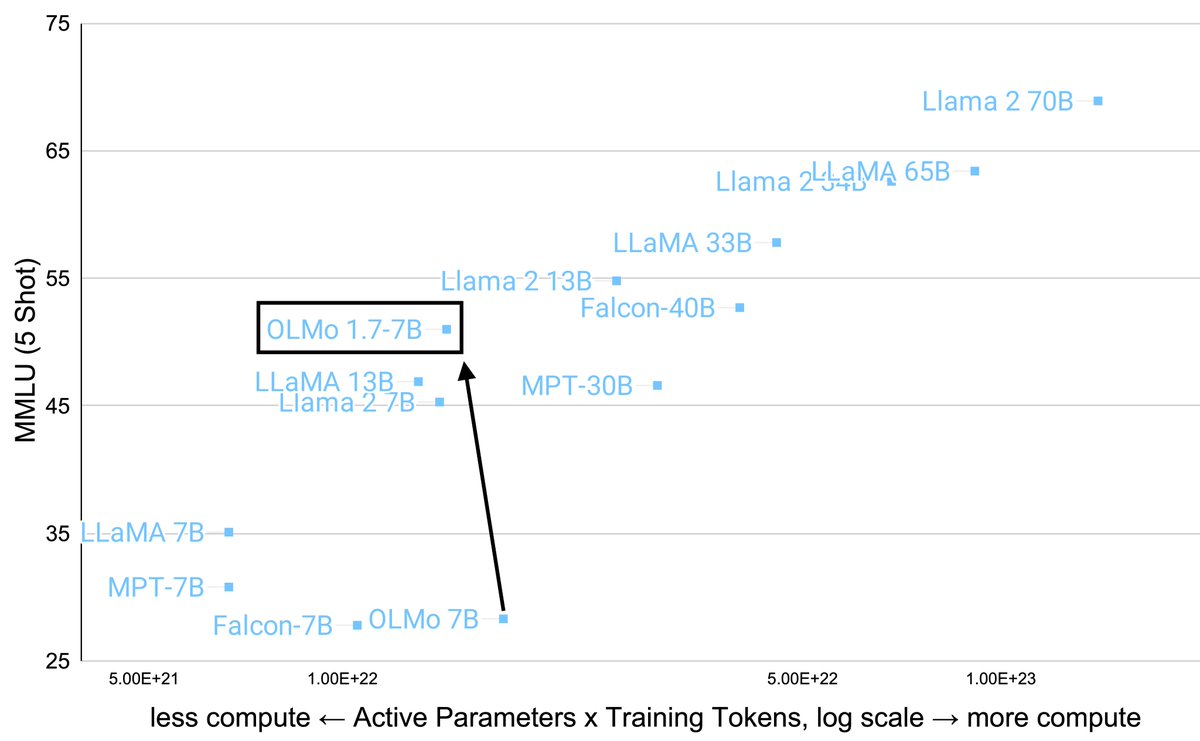
Announcing our latest addition to the OLMo family, OLMo 1.7!🎉Our team's efforts to improve data quality, training procedures and model architecture have led to a leap in performance. See how OLMo 1.7 stacks up against its peers and peek into the technical details on the blog:…
We can do it! 🙌 First open LLM outperforms @OpenAI GPT-4 (March) on MT-Bench. WizardLM 2 is a fine-tuned and preferences-trained Mixtral 8x22B! 🤯 TL;DR; 🧮 Mixtral 8x22B based (141B-A40 MoE) 🔓 Apache 2.0 license 🤖 First > 9.00 on MT-Bench with an open LLM 🧬 Used multi-step…

New open model from @MistralAI! 🧠 Yesterday night, Mistral released Mixtral 8x22B a 176B MoE via magnet link. 🔗🤯 What we know so far: 🧮 176B MoE with ~40B active 📜 context length of 65k tokens. 🪨 Base model can be fine-tuned 👀 ~260GB VRAM in fp16, 73GB in int4 📜 Apache…


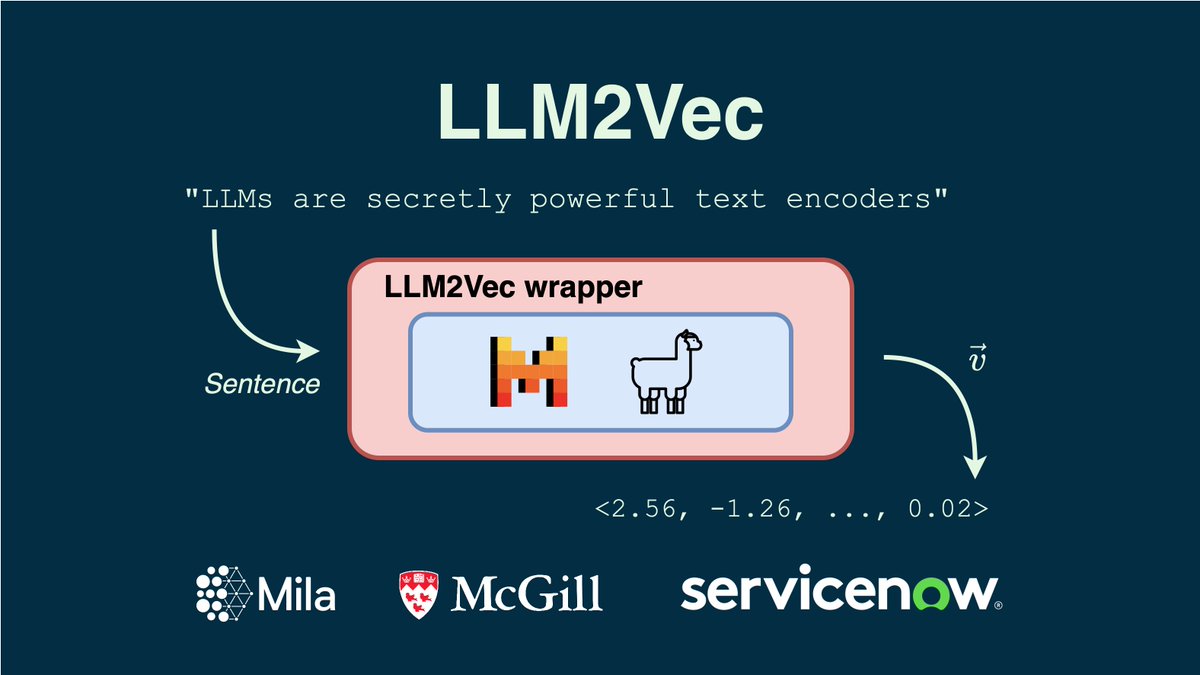
We introduce LLM2Vec, a simple approach to transform any decoder-only LLM into a text encoder. We achieve SOTA performance on MTEB in the unsupervised and supervised category (among the models trained only on publicly available data). 🧵1/N Paper: arxiv.org/abs/2404.05961

















































United States Trends
- 1. Cowboys 47,8 B posts
- 2. #WWERaw 55,8 B posts
- 3. Texans 58,9 B posts
- 4. Cooper Rush 8.098 posts
- 5. Pulisic 16,6 B posts
- 6. Mixon 12,2 B posts
- 7. #USMNT 3.118 posts
- 8. Turpin 2.967 posts
- 9. #HOUvsDAL 6.542 posts
- 10. #AskShadow 5.747 posts
- 11. Aubrey 14,4 B posts
- 12. Bruins 4.887 posts
- 13. Jake Ferguson 1.395 posts
- 14. #90dayfiancetheotherway 1.809 posts
- 15. Bray 3.828 posts
- 16. Trey Lance 1.477 posts
- 17. Zach Lavine 2.017 posts
- 18. Weah 2.088 posts
- 19. UTRGV N/A
- 20. Sheamus 2.092 posts
Who to follow
-
 IamCharytashomes🇳🇬
IamCharytashomes🇳🇬
@frances_ryta -
 Stevirae Hobson
Stevirae Hobson
@Steviraehobson3 -
 Judbianc Farms
Judbianc Farms
@JUDBIANCFARMS -
 Pegazus
Pegazus
@webPegaz -
 Carilu Dietrich
Carilu Dietrich
@clu007 -
 Don Cryptone
Don Cryptone
@CryptoneDon -
 Kieran Harvey
Kieran Harvey
@Kierans_stuff -
 Northeast Towbars & Accessories
Northeast Towbars & Accessories
@Northeasttowba1 -
 Ju ✨
Ju ✨
@inkjewels -
 Gürbey Hiz
Gürbey Hiz
@gurbeyhiz -
 ava | FLY HIGH LIAM🕊️
ava | FLY HIGH LIAM🕊️
@irwinvalntyne -
 Oska
Oska
@OscarMwandu1 -
 HOAN HỶ INVEST
HOAN HỶ INVEST
@HoanHyInvest -
 Russell W
Russell W
@Russell_Wilkey -
 kellie
kellie
@kellierosanna
Something went wrong.
Something went wrong.