
Saliya Ekanayake
@esaliyaPrincipal Software Engineer at d-Matrix, Accelerating AI
Similar User

@srinath_perera

@chanaka3d

@charithwiki

@miyurudw



Easily the most impressive uncut autonomous video I've ever seen, from @physical_int
I created a video to help explain how LLMs work. Hope you'll find it useful! youtube.com/watch?v=6o0Xnl… P.S. Creating videos is hard, but kind of fun experience

Hi all prospective grad students! Our Equal Access to Application Assistance (EAAA) program for @Berkeley_EECS is now accepting applications! Any PhD applicant to @Berkeley_EECS can submit their application for feedback by Oct. 6th 11:59PM PST forms.gle/rYVtXyaE9qE8ug…
This seems like a cool research place to join mlcollective.org/?s=09

Real2Code -- translating real-world articulated objects to sim using code generation! With the code representation, this method scales well wrt the number of object parts, check out the 10-drawer table it reconstructed 😉

Here’s something you didn’t know LLMs can do – reconstruct articulated objects! Introducing Real2Code – our new real2sim approach that scalably reconstructs complex, multi-part articulated objects. arxiv.org/abs/2406.08474



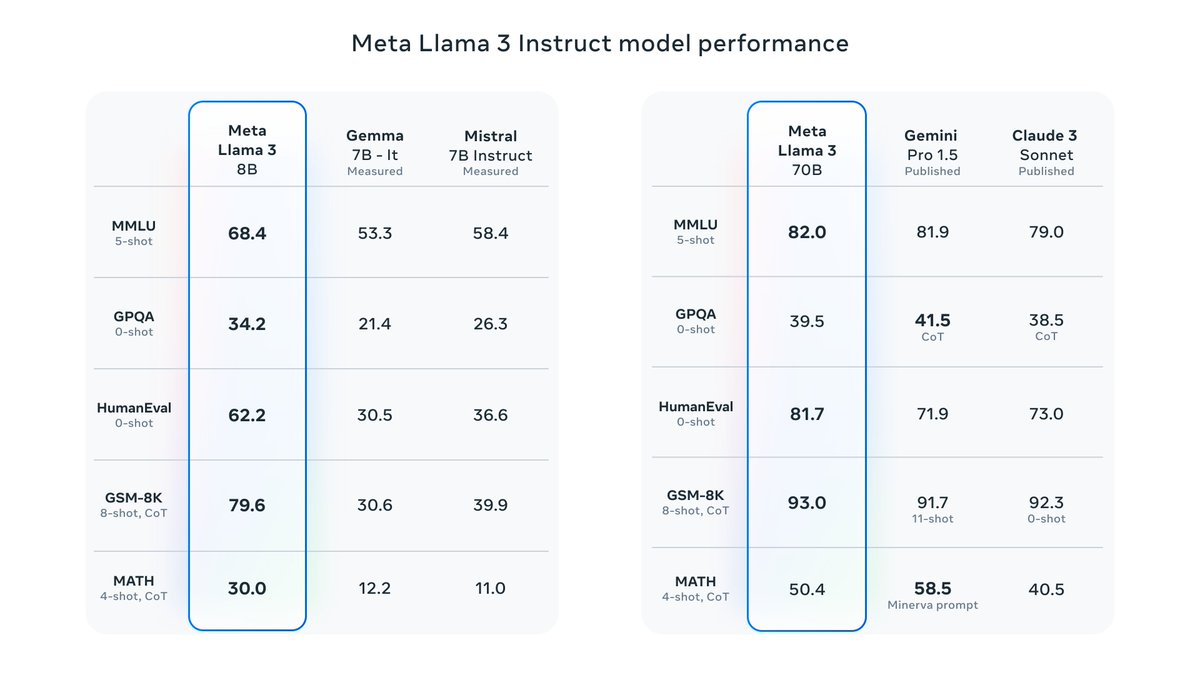
Llama3 8B and 70B are out, with pretty exciting results! * The ~400B is still training but results already look promising. * Meta's own Chat interface is also live at meta.ai * TorchTune integration is shortly going live: github.com/pytorch/torcht…

It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs. Key highlights • 8B and 70B parameter openly available pre-trained and fine-tuned models. • Trained on more…


It's been a wild ride. Just 20 of us, burning through thousands of H100s over the past months, we're glad to finally share this with the world! 💪 One of the goals we’ve had when starting Reka was to build cool innovative models at the frontier. Reaching GPT-4/Opus level was a…

Meet Reka Core, our best and most capable multimodal language model yet. 🔮 It’s been a busy few months training this model and we are glad to finally ship it! 💪 Core has a lot of capabilities, and one of them is understanding video --- let’s see what Core thinks of the 3 body…


Speedup Open-Sora's training by 3x and inference by 2x with our novel DSP (Dynamic Sequence Parallelism)! For 10s 512x512 videos, Open-Sora's inference time: 1xH800: 106s 8xH800: 45s 8xH800+DSP: 22s DSP can be seamlessly adapted to all multi-dimensional transformers, unlocking…


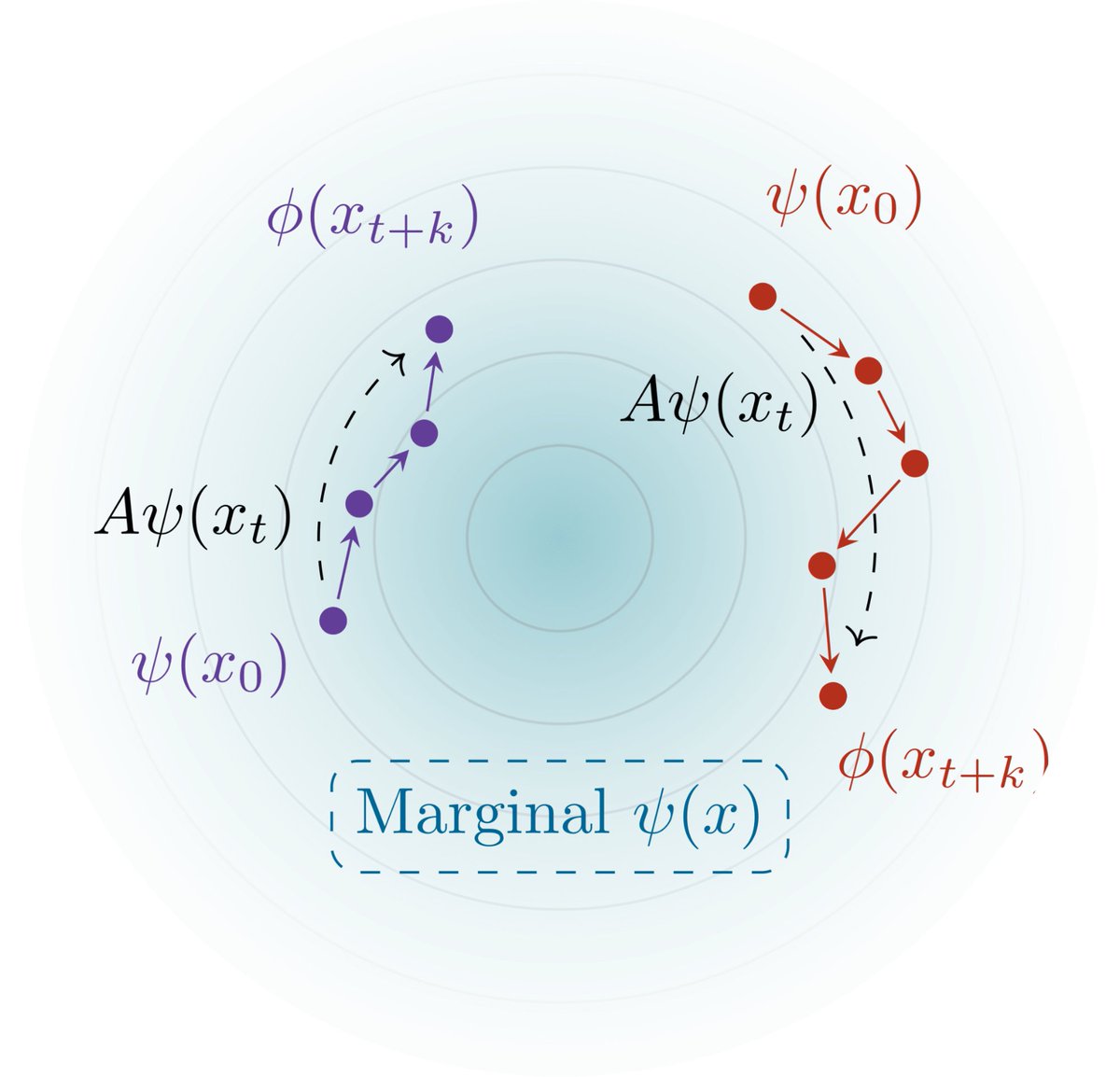
1/ Given high-dim time series data (e.g., video, text), we'd like to know "what happens in the future?" and "what happened between A and B?" Turns out temporal contrastive learning provably answers these questions! Paper+Code: arxiv.org/abs/2403.04082 Backstory and details below
I didn't know people go to the toilet to just flush toilet tissue -- must be some fun game even my kids would love

cmd+shift+A is the best thing I found in a long while -- it allows to search open tabs in the browser :)


New Resource: Foundation Model Development Cheatsheet for best practices We compiled 250+ resources & tools for: 🔭 sourcing data 🔍 documenting & audits 🌴 environmental impact ☢️ risks & harms eval 🌍 release & monitoring With experts from @AiEleuther, @allen_ai,…














































































































United States Trends
- 1. #BlueBloodsFinale 14 B posts
- 2. #dronesoverNJ 10,4 B posts
- 3. Standard 106 B posts
- 4. #SantaIsCoco N/A
- 5. #SmackDown 65,5 B posts
- 6. Daylight 98,8 B posts
- 7. Margaret Thatcher 4.252 posts
- 8. Go Army 7.503 posts
- 9. Sydney Sweeney 31,9 B posts
- 10. The Guy 321 B posts
- 11. Mayorkas 22,3 B posts
- 12. Tessa 14,9 B posts
- 13. #TADC 45,5 B posts
- 14. Bill Barr 21,2 B posts
- 15. Blazers 2.740 posts
- 16. Gangle 23,2 B posts
- 17. Michin 10,4 B posts
- 18. Embiid 10,1 B posts
- 19. Project Blue Beam 21,4 B posts
- 20. Space Force 12,5 B posts




Something went wrong.
Something went wrong.