
Similar User

@_Hao_Zhu

@lileics

@stefan_fee

@JunjieHu12

@qi2peng2

@MaxMa1987

@shuyanzhxyc

@muhao_chen

@ZiyuYao

@zhegan4

@Lianhuiq

@byryuer

@ruizhang_nlp

@YizheZhangNLP

@shoubin621

🚀Introducing MRAG-Bench: How do Large Vision-Language Models utilize vision-centric multimodal knowledge? 🤔Previous multimodal knowledge QA benchmarks can mainly be solved by retrieving text knowledge.💥We focus on scenarios where retrieving knowledge from image corpus is more…

Thrilled to share that MQT-LLaVA is accepted to #NeurIPS2024! 🎉 (arxiv.org/pdf/2405.19315) Matryoshka visual tokens have demonstrated robust capabilities across various downstream tasks. Our work enables dynamic and efficient LVLM inference, saving your inference costs while…
How to pick a good number of visual tokens? Too few, you have poor performance; too many, you need quadratically more compute. In this work, we introduce a model that works with an elastic number of tokens. arXiv: arxiv.org/abs/2405.19315

How to pick a good number of visual tokens? Too few, you have poor performance; too many, you need quadratically more compute. In this work, we introduce a model that works with an elastic number of tokens. arXiv: arxiv.org/abs/2405.19315

🔍Hallucination or informativeness? 🤔Our latest research unveils a multi-dimensional benchmark and an LLM-based metric for measuring faithfulness and coverage in LVLMs. Explore our new method for a more reliable understanding of model outputs! 📣arxiv.org/pdf/2404.13874…

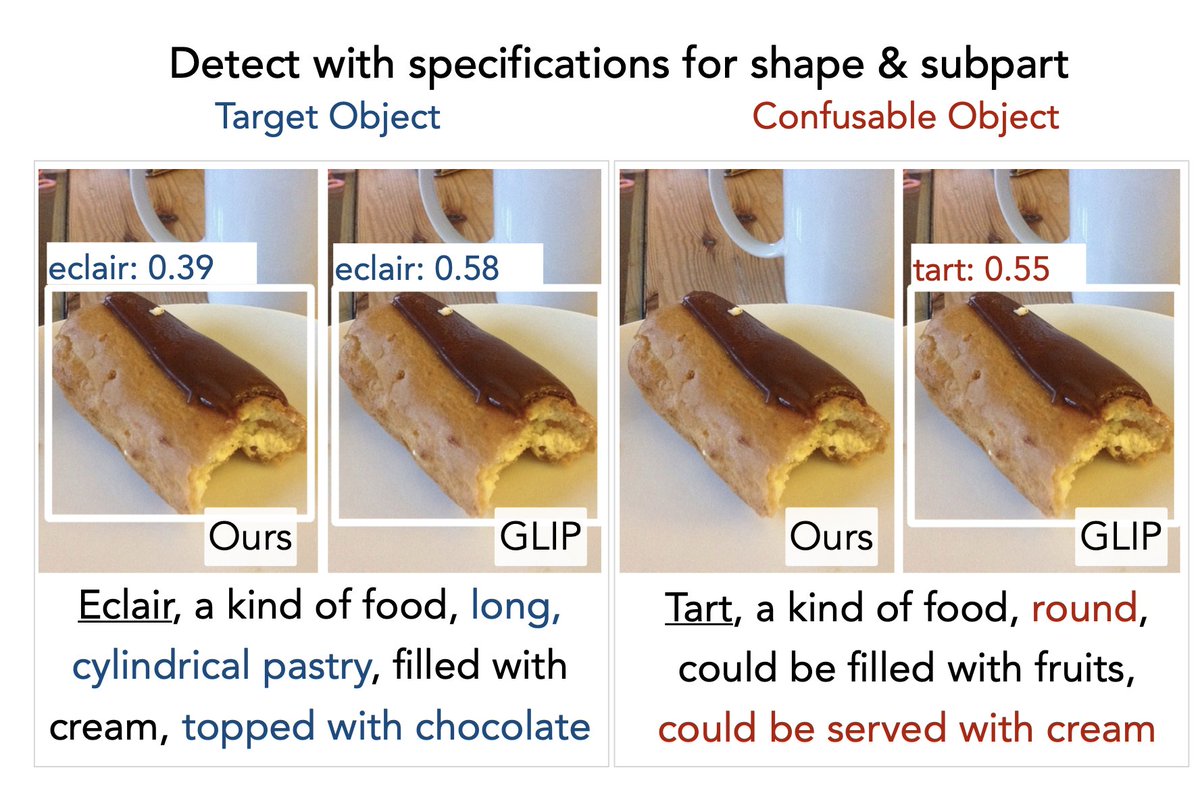
#NeurIPS2023 Stop by our poster at Great Hall & Hall B1+B2 (level 1) #1925 (today 10:45-12:45) to chat about object recognition with language descriptions! Paper: openreview.net/pdf?id=WKJDGfU… Code: github.com/liunian-harold… Demo: huggingface.co/spaces/zdou083…

Arrived at #NeurIPS2023! Looking forward to meeting old and new friends! We will present our work on teaching models to ground by descriptions (DesCo) on Wed morning. Also checkout our demo huggingface.co/spaces/zdou083…!


Besides, @LiLiunian and @ZiYiDou will present Desco, our new initiative on learning to recognize objects with rich language descriptions. It extends GLIP and achieves top performance #OminiLabel challenge in CVPR23. twitter.com/LiLiunian/stat…

Arrived at #NeurIPS2023! Looking forward to meeting old and new friends! We will present our work on teaching models to ground by descriptions (DesCo) on Wed morning. Also checkout our demo huggingface.co/spaces/zdou083…!
Arrived at #NeurIPS2023! Looking forward to meeting old and new friends! We will present our work on teaching models to ground by descriptions (DesCo) on Wed morning. Also checkout our demo huggingface.co/spaces/zdou083…!
Excited to share our new work DesCo (arxiv.org/pdf/2306.14060…) -- an instructing object detector that takes complex language descriptions (e.g., attributes & relations). DesCo improves zero-shot detection (+9.1 APr on LVIS) and ranks 1st at the #OmniLabel Challenge of CVPR2023!



🚨Model-based evaluation metrics like CLIPScore can unintentionally favor gender-biased captions in image captioning tasks! 📣 Check out our new #EMNLP2023 work: arxiv.org/abs/2305.14711 A joint effort with @ZiYiDou @Tianlu_Wang @real_asli and my amazing advisor @VioletNPeng

Check out our new work DesCo🪩 that can locate objects based on diverse and complex language descriptions! abs: arxiv.org/abs/2306.14060
Excited to share our new work DesCo (arxiv.org/pdf/2306.14060…) -- an instructing object detector that takes complex language descriptions (e.g., attributes & relations). DesCo improves zero-shot detection (+9.1 APr on LVIS) and ranks 1st at the #OmniLabel Challenge of CVPR2023!
DesCo🪩: Can we teach a vision-language model to recognize objects by language descriptions as a kid does? 🔥 Our new approach leverages LLM for training vision models based on rich descriptions @uclanlp
Excited to share our new work DesCo (arxiv.org/pdf/2306.14060…) -- an instructing object detector that takes complex language descriptions (e.g., attributes & relations). DesCo improves zero-shot detection (+9.1 APr on LVIS) and ranks 1st at the #OmniLabel Challenge of CVPR2023!
Excited to share our new work DesCo (arxiv.org/pdf/2306.14060…) -- an instructing object detector that takes complex language descriptions (e.g., attributes & relations). DesCo improves zero-shot detection (+9.1 APr on LVIS) and ranks 1st at the #OmniLabel Challenge of CVPR2023!

We built X-Dec as a generalist model and showed demos @huggingface, but never poured all capacities into a single system. Now inspired by Visual ChatGPT, we are excited to share X-GPT that marries X-Dec with GPT for conversation AI, where X-Dec is the ONLY model for all VL tasks!

X-Decoder: Generalized Decoding for Pixel, Image and Language Hugging Face demo: huggingface.co/spaces/xdecode… abs: arxiv.org/abs/2212.11270 project page: x-decoder-vl.github.io github: github.com/microsoft/X-De…
Accepted by #CVPR2023! X-Decoder is the FIRST generalist decoder that supports all segmentation tasks (ins/sem/pano/ref) in OPEN VOCABULARY, both inter- AND intra-image VL tasks, and even helps instruct image inpainting/editing! New demo below and more at huggingface.co/xdecoder!
X-Decoder: Generalized Decoding for Pixel, Image and Language Hugging Face demo: huggingface.co/spaces/xdecode… abs: arxiv.org/abs/2212.11270 project page: x-decoder-vl.github.io github: github.com/microsoft/X-De…
#NeurIPS2022 Will present FIBER at Hall J #635, Dec 1st 4-6pm!


Presenting FIBER (Fusion In-the-Backbone transformER) a novel V&L architecture w/ deep multi-modal fusion + a new pre-training strategy that first learns through coarse-grained image level objectives, and then obtains fine-grained understanding using image-text-box data.

Presenting FIBER (Fusion In-the-Backbone transformER) a novel V&L architecture w/ deep multi-modal fusion + a new pre-training strategy that first learns through coarse-grained image level objectives, and then obtains fine-grained understanding using image-text-box data.
Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone abs: arxiv.org/abs/2206.07643 project page: ashkamath.github.io/FIBER_page/ github: github.com/microsoft/FIBER


AWESOME aligner is now on PyPi, so you can now download and install a state-of-the-art cross-lingual word aligner with just a "pip install awesome-align"! Check it out: pypi.org/project/awesom…
Check out our new awesome word aligner, AWESOME aligner by @ZiYiDou 😀: github.com/neulab/awesome… * Uses multilingual BERT and can align sentences in all included languages * No additional training needed, so you can align even a single sentence pair! * Excellent accuracy 1/3


Check out our new awesome word aligner, AWESOME aligner by @ZiYiDou 😀: github.com/neulab/awesome… * Uses multilingual BERT and can align sentences in all included languages * No additional training needed, so you can align even a single sentence pair! * Excellent accuracy 1/3
What if the best Ext-Sum MEETS the best Abs-Sum system? Check out (@ZiYiDou @gneubig,@hiroakiLhayashi, zbj): arxiv.org/pdf/2010.08014… That's not the whole story, highlightings: 1) a general guided framework 2) simple yet effective training strategy 3) super encouraging result


"A General Framework for Guided Abstractive Summarization" by @ZiYiDou et al! Highlights: 1. One framework that allows control of summaries using keywords, IE triples, templates, extractive summaries. 2. Great results, e.g. SOTA on CNN-DM. 3. Lots of nice analysis/examples.
What if the best Ext-Sum MEETS the best Abs-Sum system? Check out (@ZiYiDou @gneubig,@hiroakiLhayashi, zbj): arxiv.org/pdf/2010.08014… That's not the whole story, highlightings: 1) a general guided framework 2) simple yet effective training strategy 3) super encouraging result
#EMNLP2019 paper "Unsupervised Domain Adaptation for NMT with Domain-Aware Feature Embeddings" by @ZiYiDou presents a simple and effective way to perform unsupervised pre-training of MT models for specific domains by joint training with LM objectives: arxiv.org/abs/1908.10430























































































































United States Trends
- 1. Colorado 53,5 B posts
- 2. Kansas 27,7 B posts
- 3. Devin Neal 2.953 posts
- 4. Ole Miss 32,2 B posts
- 5. Travis Hunter 9.721 posts
- 6. Indiana 62,2 B posts
- 7. Penn State 8.340 posts
- 8. Gators 19 B posts
- 9. Ewers 2.167 posts
- 10. Shedeur 8.072 posts
- 11. Jaxson Dart 6.950 posts
- 12. Sark 3.035 posts
- 13. Ohio State 41,1 B posts
- 14. Olivia Miles 1.802 posts
- 15. Minnesota 17,3 B posts
- 16. James Franklin N/A
- 17. #Huskers 2.363 posts
- 18. Heisman 7.863 posts
- 19. Wayne 142 B posts
- 20. Fickell N/A
Who to follow
-
 Hao Zhu 朱昊
Hao Zhu 朱昊
@_Hao_Zhu -
 Lei Li
Lei Li
@lileics -
 Pengfei Liu
Pengfei Liu
@stefan_fee -
 Junjie Hu
Junjie Hu
@JunjieHu12 -
 Peng Qi
Peng Qi
@qi2peng2 -
 Xuezhe Ma (Max)
Xuezhe Ma (Max)
@MaxMa1987 -
 Shuyan Zhou
Shuyan Zhou
@shuyanzhxyc -
 🌴Muhao Chen🌴
🌴Muhao Chen🌴
@muhao_chen -
 Ziyu Yao
Ziyu Yao
@ZiyuYao -
 Zhe Gan
Zhe Gan
@zhegan4 -
 Lianhui Qin
Lianhui Qin
@Lianhuiq -
 Shiyue Zhang
Shiyue Zhang
@byryuer -
 Rui Zhang @ EMNLP 2024
Rui Zhang @ EMNLP 2024
@ruizhang_nlp -
 Yizhe Zhang
Yizhe Zhang
@YizheZhangNLP -
 Shoubin Yu
Shoubin Yu
@shoubin621
Something went wrong.
Something went wrong.