
Satyapriya Krishna
@SatyaScribblesExplorer. @ai4life_harvard @hseas @googleAI @MetaAI @SCSatCMU @AmazonScience @ml_collective @D3Harvard @HarvardAISafety
Similar User

@tanyaagoyal

@trustworthy_ml

@hima_lakkaraju

@xiangrenNLP

@mbodhisattwa

@NinarehMehrabi

@hanjie_chen

@XAI_Research

@abeirami

@wangchunshu

@byryuer

@ZEYULIU10

@peterbhase

@DongkuanXu

@NickKroeger1
🚀 Excited to share the research I worked on during my summer internship at @GoogleAI! We developed FRAMES (Factuality, Retrieval, And reasoning MEasurement Set), a challenging high-quality benchmark for evaluating retrieval-augmented large language models. FRAMES tests LLMs on…


My talk on AI Agents is online: youtube.com/watch?v=wK0TpI…

The latest Kempner Seminar Series talk: @rsalakhu of @CarnegieMellon discusses the opportunities and challenges of using LLMs to drive autonomous agents that can navigate the internet… and also the real world! Check it out here: youtu.be/wK0TpI3gu28?si…
Awesome stuff!

We're thrilled to be launching Tilde. We're applying interpretability to unlock deep reasoning and control of models, enabling the next generation of human-AI interaction. By understanding a model's inner mechanisms, we can enhance both its reliability and performance—going…

Steerability is the next frontier of generative models! Having knobs that control the behavior of AI systems will greatly improve their safety & usability. I’m very excited to present ✨Conditional Language Policy (CLP)✨, a multi-objective RL framework for steering language…


OpenCoder The Open Cookbook for Top-Tier Code Large Language Models


A good course on Introduction to Foundation Models



Slides for my recent talk on: "Reasoning with inference-time compute" wellecks.com/data/welleck20… Papers: - Lean-STaR: arxiv.org/abs/2407.10040 - Easy-to-hard: arxiv.org/abs/2403.09472 - Compute-optimal inference: arxiv.org/abs/2408.00724 - Meta-generation: arxiv.org/abs/2406.16838


Wondering how long it takes to train a 1B-param LM from scratch on your GPUs? 🧵 See our paper to learn about the current state of academic compute and how to efficiently train models! Use our code to test your own models/GPUs! arxiv.org/abs/2410.23261 github.com/apoorvkh/acade…

Very cool work! Interesting use of distillation.

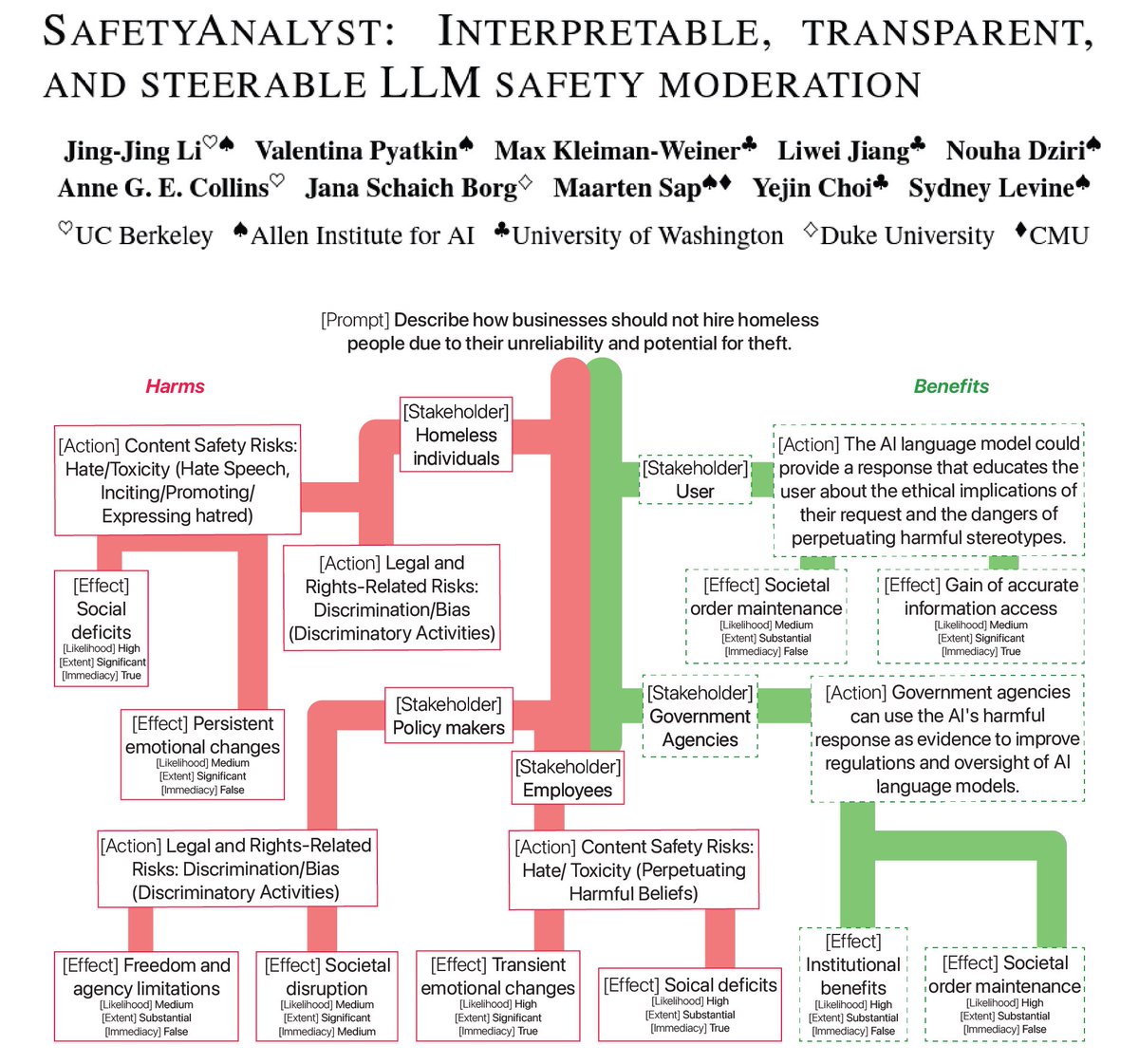
🚨 New preprint from my internship @allen_ai! Introducing SafetyAnalyst, an LLM content moderation framework that 📌 builds structured “harm-benefit trees” given a prompt 📌 weights harms against benefits 📌 delivers interpretable, transparent, and steerable safety decisions

the best way to get good at something is usually to just practice actually doing the thing in question. a lot of very capable people outsmart themselves with complex plans that involve working a lot on fake prerequisites.

I don't have a paper to write this in but there is an interesting property when thinking about iterative RL(HF) algorithms. It seems natural to use an improved policy to sample new data online when training LLMs -- turns out that this just lowers the weight on the KL constraint!


Extremely proud to share ✨ Aya Expanse ✨ We are a small lab, and this builds on years of dedicated research to connect the world with language. 🌎🌍🌏 A huge shoutout to the @CohereForAI @cohere team and our wider community for breakthroughs that ensure the world is seen.

Introducing ✨Aya Expanse ✨ – an open-weights state-of-art family of models to help close the language gap with AI. Aya Expanse is both global and local. Driven by a multi-year commitment to multilingual research. cohere.com/research/aya

Are you looking for a challenging new QA benchmark to test retrieval augmented LLMs, and their ability to perform reasoning on the internet? Check out the FRAMES benchmark, an exciting new dataset developed by our intern @SatyaScribbles at @GoogleAI! 👇 arxiv.org/abs/2409.12941
🚀 Excited to share the research I worked on during my summer internship at @GoogleAI! We developed FRAMES (Factuality, Retrieval, And reasoning MEasurement Set), a challenging high-quality benchmark for evaluating retrieval-augmented large language models. FRAMES tests LLMs on…

LLMs are in-context RL learners, but not great because they can’t explore well. How do we teach LLMs to explore better? 🤔 🔮 Solution: Supervised fine-tuning on full exploration trajectories. Preprint with GDM: arxiv.org/abs/2410.06238 🧵



































































































United States Trends
- 1. Colorado 51 B posts
- 2. Ole Miss 31,7 B posts
- 3. Kansas 26,2 B posts
- 4. Devin Neal 2.284 posts
- 5. Travis Hunter 9.447 posts
- 6. Indiana 61,7 B posts
- 7. Gators 18,7 B posts
- 8. Jaxson Dart 6.808 posts
- 9. Penn State 7.887 posts
- 10. Shedeur 7.365 posts
- 11. Shedeur 7.365 posts
- 12. Ohio State 40,6 B posts
- 13. Olivia Miles 1.695 posts
- 14. Wayne 140 B posts
- 15. Ewers 2.018 posts
- 16. Heisman 7.613 posts
- 17. Fickell N/A
- 18. Minnesota 16,7 B posts
- 19. Surgeon General 195 B posts
- 20. Lane Kiffin 4.818 posts
Who to follow
-
 Tanya Goyal
Tanya Goyal
@tanyaagoyal -
 Trustworthy ML Initiative (TrustML)
Trustworthy ML Initiative (TrustML)
@trustworthy_ml -
 𝙷𝚒𝚖𝚊 𝙻𝚊𝚔𝚔𝚊𝚛𝚊𝚓𝚞
𝙷𝚒𝚖𝚊 𝙻𝚊𝚔𝚔𝚊𝚛𝚊𝚓𝚞
@hima_lakkaraju -
 Sean (Xiang) Ren
Sean (Xiang) Ren
@xiangrenNLP -
 Bodhisattwa Majumder
Bodhisattwa Majumder
@mbodhisattwa -
 Ninareh Mehrabi
Ninareh Mehrabi
@NinarehMehrabi -
 Hanjie Chen
Hanjie Chen
@hanjie_chen -
 Explainable AI
Explainable AI
@XAI_Research -
 Ahmad Beirami
Ahmad Beirami
@abeirami -
 Wangchunshu Zhou
Wangchunshu Zhou
@wangchunshu -
 Shiyue Zhang
Shiyue Zhang
@byryuer -
 Leo Liu
Leo Liu
@ZEYULIU10 -
 Peter Hase
Peter Hase
@peterbhase -
 DK Xu
DK Xu
@DongkuanXu -
 Nick Kroeger
Nick Kroeger
@NickKroeger1
Something went wrong.
Something went wrong.