
Huizhuo Yuan
@HuizhuoYGraduate student @UCLA AGI lab, Researcher on LLMs, Diffusion Models, Reinforcement Learning, Games and AI for Science. Opinions are my own.

🤯 ModelCloud has Tested and Validated the new MARS optimizer from UCLA over two models Llama 3.1 8B and Qwen 2.5 32B which resulted in significant time savings in BF16 finetuning versus Paged-AdamW-8bit. @QuanquanGu👇 Paper: arxiv.org/pdf/2411.10438 Code: github.com/AGI-Arena/MARS


I re-implemented your experiments using PyTorch, with the same setting (github.com/AGI-Arena/MARS…), getting higher performances for all the optimizers. And when I changed optimizer_1d=False for MARS, MARS shows clear edge over other optimizers about 1%.


Finally making variance reduction practical for modern AI training. Basically, teaching AI models faster by reducing the noise in their learning Original Problem 🎯: Training LLMs faces high gradient variance issues. Current adaptive optimizers like AdamW, while widely used,…


What’s New in MARS? Variance reduction techniques have been extensively developed over the past decade to accelerate stochastic optimization in both convex and nonconvex settings. However, their application to training deep neural networks and LLMs has met with limited success,…
Today’s the day to launch! Introducing MARS (Make vAriance Reduction Shine): the ultimate LLM optimizer. Let’s unite, innovate, and take our shot at MARS! 🚀🚀🚀 Paper: arxiv.org/pdf/2411.10438 Code: github.com/AGI-Arena/MARS

What is Variance Reduction? Variance reduction in Monte Carlo estimation leverages correlations between random variables to improve estimation accuracy. If X is the target random variable and Y is a similar one with a known expectation E[Y], we can define an estimator as…
Today’s the day to launch! Introducing MARS (Make vAriance Reduction Shine): the ultimate LLM optimizer. Let’s unite, innovate, and take our shot at MARS! 🚀🚀🚀 Paper: arxiv.org/pdf/2411.10438 Code: github.com/AGI-Arena/MARS
Today’s the day to launch! Introducing MARS (Make vAriance Reduction Shine): the ultimate LLM optimizer. Let’s unite, innovate, and take our shot at MARS! 🚀🚀🚀 Paper: arxiv.org/pdf/2411.10438 Code: github.com/AGI-Arena/MARS

1/ 🔍 Wonder about the answer? cryo-EM ✖️ Foundation Model 🟰 ❓ cryo-EM ✖️ Flow Matching 🟰 ❓ cryo-EM ✖️ Diffusion Transformer 🟰 ❓ Excited to introduce our new work--cryoFM, the first cryo-EM foundation model for protein densities with flow matching, which generalizes to…
We've applied Self-Play Preference Optimization (SPPO) to the latest Gemma-2-9B-instruct model, achieving a 53.27% LC win rate on AlpacaEval 2.0 leaderboard. Check out the models and code here: 🤗models: huggingface.co/collections/UC… ✨code: github.com/uclaml/SPPO


We've open-sourced the code and models for Self-Play Preference Optimization (SPPO)! 🚀🚀🚀 ⭐ code: github.com/uclaml/SPPO 🤗models: huggingface.co/collections/UC…

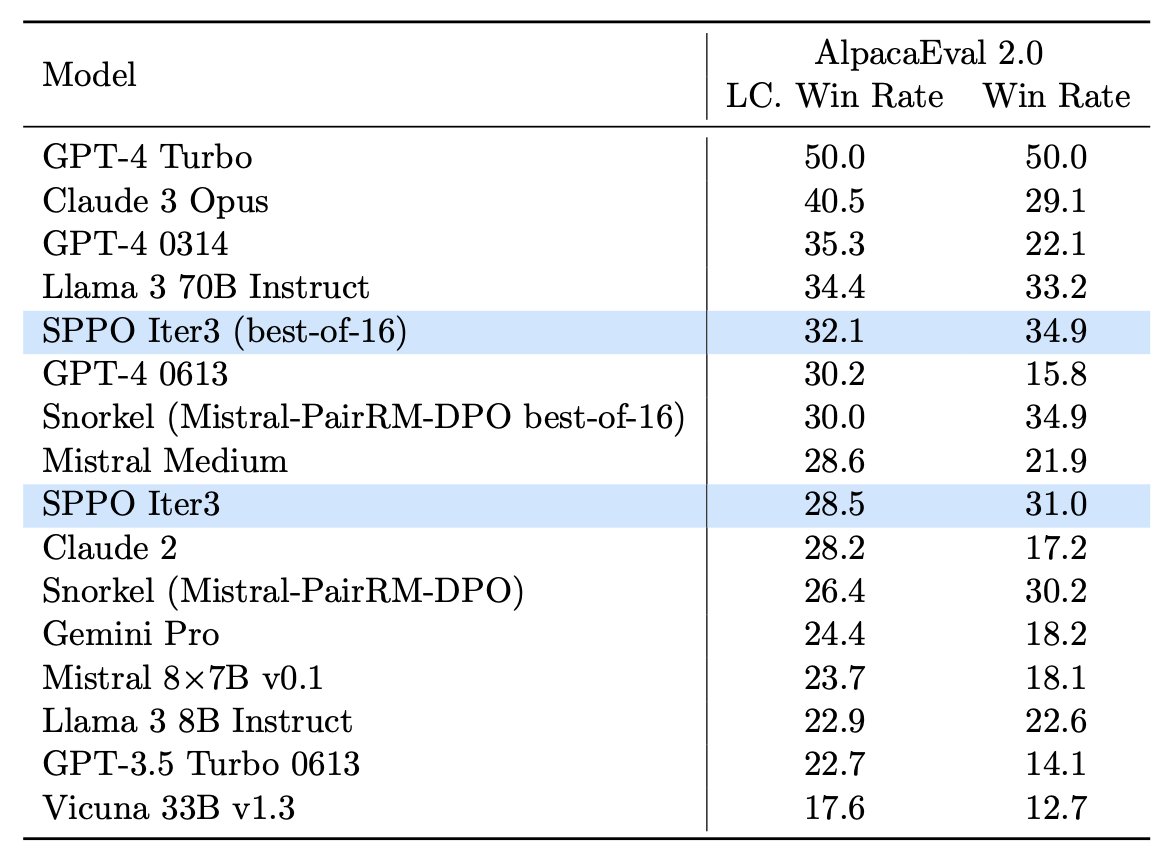
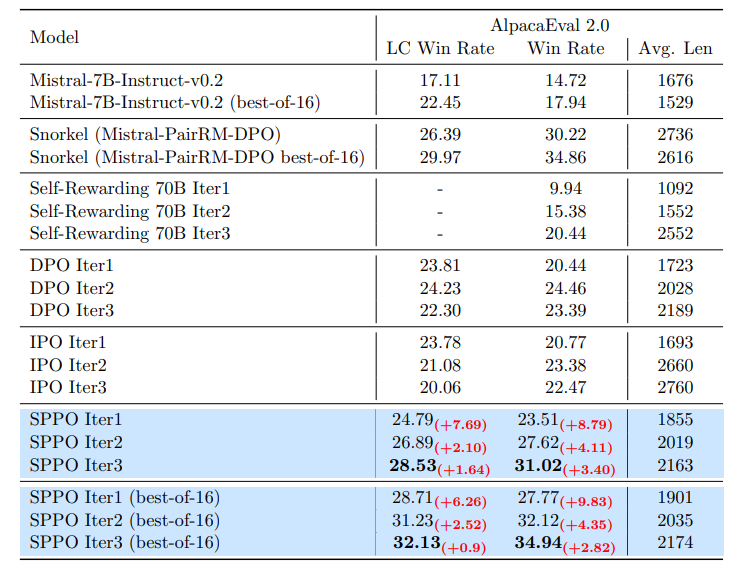
Another triumph for Self-Play! Self-Play Preference Optimization (SPPO) has surpassed (iterative) DPO, IPO, Self-Rewarding LMs, and others on AlpacaEval, MT-Bench, and the Open LLM Leaderboard. Remarkably, Mistral-7B-instruct-v0.2 fine-tuned by SPPO achieves superior…

Google presents To Believe or Not to Believe Your LLM arxiv.org/abs/2406.02543


Thrilled to announce that I am joining @CS_UCLA as an Assistant Professor this Fall! 🐻 Many thanks to my incredible advisors, mentors, family and friends for the encouragement and support. ❤️Looking forward to this exciting new chapter and all the opportunities ahead! 🤖🤖🤖

Why CLIP is more robust to distribution shift than supervised learning? This #ICLR2024 paper provides the first rigorous proof! TL;DR details specified in the captions allow learning more generalizable features from images. Check it out: Tue, PS#1, P#113 arxiv.org/pdf/2319.04971

Happy to share that I have two papers (arxiv.org/pdf/2310.04971… , arxiv.org/pdf/2403.11391… ) accepted at #ICLR2024! ⬇️🧵 1/



Thanks everyone for cheering applause and constructive criticism. I wrote a few paragraphs responding to the recent KAN hype. In short, I think it is too early to say KANs will replace MLPs, but there are indeed many interesting directions to explore. github.com/KindXiaoming/p…


⭐Self-Play Preference Optimization for Language Model Alignment⭐ arxiv.org/abs/2405.00675 Bradley-Terry models in RLHF fall short in capturing the intransitivity and irrationality in human preferences. How can we identify the Nash equilibrium policy with general preferences?🧵

Self-Play Preference Optimization for Language Model Alignment Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences.

Another triumph for Self-Play! Self-Play Preference Optimization (SPPO) has surpassed (iterative) DPO, IPO, Self-Rewarding LMs, and others on AlpacaEval, MT-Bench, and the Open LLM Leaderboard. Remarkably, Mistral-7B-instruct-v0.2 fine-tuned by SPPO achieves superior…
Self-Play Preference Optimization for Language Model Alignment SPPO serves as the RLHF counterpart of SPIN and outperforms iterative DPO, Snorkel AI, Self-Rewarding LM, GPT-4 0613 etc arxiv.org/abs/2405.00675
🚨Excited to introduce ConfDiff for protein conformation generation! Background: Protein folding can be likened to text-to-image generation, while protein conformation generation is akin to text-to-video generation. For protein folding, notable methods include AlphaFold,…

1/ Proteins exhibit a dynamic nature. We stand by the belief that steering with physical knowledge is vital in real-world dynamic structure prediction, and we're delighted to introduce our force-guided diffusion model for generating protein conformations. arxiv.org/abs/2403.14088


🫡Excited to see this strong and versatile diffusion-based protein language model🧬 which shows superiority in numerous predictive and generative tasks. Let's eagerly anticipate its transformative potential! Congrats to my friends! 👏

























































































United States Trends
- 1. Black Friday 508 B posts
- 2. #TheOfficialTSTheErasTourBook 9.549 posts
- 3. #TTPDTheAnthology 9.960 posts
- 4. $CUTO 8.690 posts
- 5. #socideveloper_com N/A
- 6. #FridayVibes 5.370 posts
- 7. #TaylorSwift 1.380 posts
- 8. Great War 8.657 posts
- 9. Cutoshi Farming N/A
- 10. Cyber Monday 12,7 B posts
- 11. Datsun 13 B posts
- 12. Secured 36,4 B posts
- 13. FROMIS TOO 1.811 posts
- 14. Aleppo 114 B posts
- 15. Kyrie 33,4 B posts
- 16. YOKO AT BVLGARI 282 B posts
- 17. Algebra 11,5 B posts
- 18. TODAY ONLY 81,9 B posts
- 19. Assad 91,7 B posts
- 20. Syria 163 B posts
Something went wrong.
Something went wrong.